.webp)



- RAG kết hợp việc truy xuất dữ liệu đáng tin cậy với khả năng sinh văn bản của LLM, đảm bảo phản hồi của AI chính xác, phù hợp và dựa trên kiến thức thực tế của doanh nghiệp.
- Khác với LLM thuần túy, RAG giảm thiểu hiện tượng "ảo giác" bằng cách gắn kết câu trả lời với các tài liệu, cơ sở dữ liệu hoặc nội dung đã được phê duyệt cụ thể.
- RAG hỗ trợ thông tin cập nhật, giúp hệ thống AI trả lời các câu hỏi về thay đổi gần đây hoặc chủ đề chuyên biệt vượt ra ngoài dữ liệu huấn luyện tĩnh của LLM.
- Duy trì một hệ thống RAG bao gồm việc cập nhật dữ liệu, giám sát kết quả và cải tiến phương pháp truy xuất để đạt hiệu suất tối ưu theo thời gian.
RAG cho phép tổ chức ứng dụng AI – với rủi ro thấp hơn so với việc sử dụng LLM truyền thống.
Retrieval-augmented generation ngày càng phổ biến khi nhiều doanh nghiệp triển khai giải pháp AI. Những chatbot doanh nghiệp đầu tiên từng gặp phải lỗi nghiêm trọng và hiện tượng "ảo giác".
RAG giúp các công ty tận dụng sức mạnh của LLM đồng thời đảm bảo kết quả sinh ra dựa trên kiến thức doanh nghiệp cụ thể.
Retrieval-augmented generation là gì?
Retrieval-augmented generation (RAG) trong AI là kỹ thuật kết hợp a) truy xuất thông tin bên ngoài liên quan và b) phản hồi do AI tạo ra, giúp tăng độ chính xác và phù hợp.
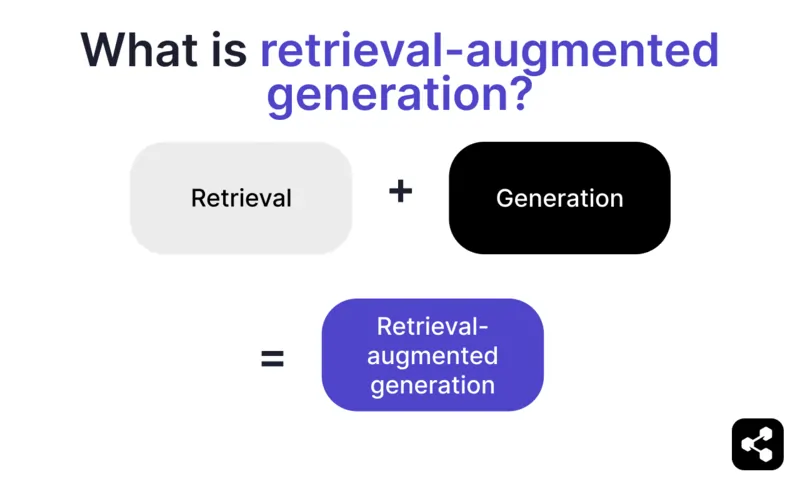
Thay vì chỉ dựa vào khả năng tạo văn bản của LLM, phản hồi từ mô hình RAG được lấy từ các cơ sở tri thức do người xây dựng AI quyết định – như trang web công ty hoặc tài liệu chính sách nhân sự.
RAG hoạt động qua hai bước chính:
1. Truy xuất dữ liệu
Mô hình sẽ tìm kiếm và lấy dữ liệu liên quan từ các nguồn có cấu trúc hoặc không có cấu trúc (ví dụ: cơ sở dữ liệu, tệp PDF, tệp HTML hoặc các tài liệu khác). Các nguồn này có thể là dạng bảng (có cấu trúc) hoặc trang web đã được phê duyệt (không có cấu trúc).
2. Sinh văn bản
Sau khi truy xuất, thông tin được đưa vào LLM. LLM sử dụng thông tin này để tạo ra phản hồi bằng ngôn ngữ tự nhiên, kết hợp dữ liệu đã được phê duyệt với khả năng ngôn ngữ của mình nhằm tạo ra câu trả lời chính xác, tự nhiên và phù hợp với thương hiệu.
Ví dụ về các trường hợp sử dụng RAG
Ý nghĩa của RAG là gì? Nó giúp tổ chức cung cấp kết quả phù hợp, hữu ích và chính xác.
RAG là cách trực tiếp để giảm rủi ro về kết quả không chính xác hoặc "ảo giác" của LLM.
Ví dụ 1: Công ty Luật
Một công ty luật có thể sử dụng RAG trong hệ thống AI để:
- Tìm kiếm các án lệ, tiền lệ và phán quyết pháp lý liên quan từ cơ sở dữ liệu tài liệu trong quá trình nghiên cứu.
- Tạo tóm tắt vụ án bằng cách trích xuất các thông tin chính từ hồ sơ vụ án và các phán quyết trước đó.
- Tự động cung cấp cho nhân viên các cập nhật quy định liên quan.
Ví dụ 2: Công ty Bất động sản
Một công ty bất động sản có thể sử dụng RAG trong hệ thống AI để:
- Tóm tắt dữ liệu từ lịch sử giao dịch bất động sản và thống kê tội phạm khu vực.
- Trả lời các câu hỏi pháp lý về giao dịch bất động sản bằng cách trích dẫn luật và quy định địa phương.
- Tối ưu hóa quy trình thẩm định bằng cách lấy dữ liệu từ báo cáo tình trạng bất động sản, xu hướng thị trường và lịch sử giao dịch.
Ví dụ 3: Cửa hàng Thương mại điện tử
Một doanh nghiệp thương mại điện tử có thể sử dụng RAG trong hệ thống AI để:
- Thu thập thông tin sản phẩm, thông số kỹ thuật và đánh giá từ cơ sở dữ liệu công ty để đưa ra gợi ý sản phẩm cá nhân hóa.
- Truy xuất lịch sử đơn hàng để tạo trải nghiệm mua sắm phù hợp với sở thích người dùng.
- Tạo chiến dịch email nhắm mục tiêu bằng cách truy xuất dữ liệu phân khúc khách hàng và kết hợp với hành vi mua hàng gần đây.
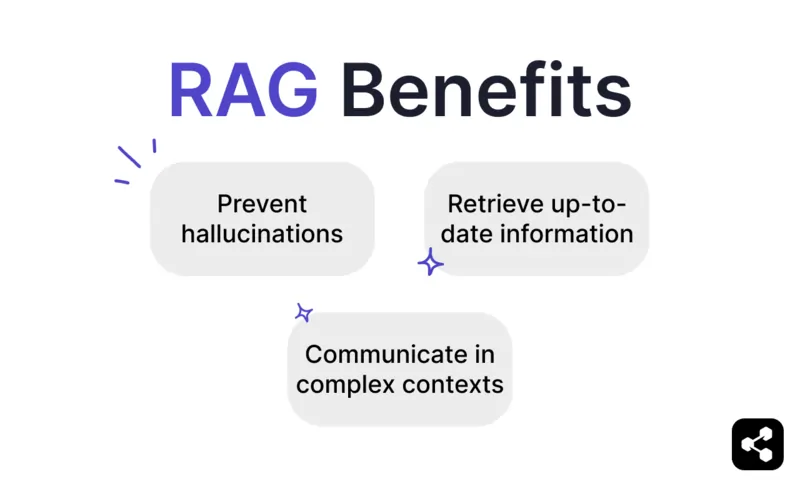
Lợi ích của RAG
Như bất kỳ ai từng hỏi ChatGPT hoặc Claude đều biết, các LLM có rất ít biện pháp bảo vệ tích hợp.
Nếu không được kiểm soát đúng cách, chúng có thể tạo ra thông tin không chính xác hoặc thậm chí gây hại, khiến chúng không đáng tin cậy khi triển khai thực tế.
RAG mang đến giải pháp bằng cách dựa vào các nguồn dữ liệu đáng tin cậy, cập nhật, giúp giảm đáng kể các rủi ro này.
Ngăn ngừa "ảo giác" và sai sót
Các mô hình ngôn ngữ truyền thống thường tạo ra "ảo giác" – những câu trả lời nghe có vẻ hợp lý nhưng thực tế lại sai hoặc không liên quan.
RAG giảm thiểu "ảo giác" bằng cách dựa vào các nguồn dữ liệu đáng tin cậy và cực kỳ liên quan.
Bước truy xuất đảm bảo mô hình tham chiếu thông tin chính xác, cập nhật, từ đó giảm đáng kể nguy cơ "ảo giác" và tăng độ tin cậy.
Truy xuất thông tin cập nhật
Dù LLM là công cụ mạnh mẽ cho nhiều tác vụ, chúng không thể cung cấp thông tin chính xác về các chủ đề hiếm gặp hoặc mới – bao gồm cả kiến thức doanh nghiệp được thiết kế riêng.
Nhưng RAG cho phép mô hình lấy thông tin theo thời gian thực từ bất kỳ nguồn nào, bao gồm trang web, bảng dữ liệu hoặc cơ sở dữ liệu.
Điều này đảm bảo rằng, miễn là nguồn dữ liệu được cập nhật, mô hình sẽ phản hồi bằng thông tin mới nhất.
Giao tiếp trong bối cảnh phức tạp
Một điểm yếu khác của việc sử dụng LLM truyền thống là mất thông tin ngữ cảnh.
LLM gặp khó khăn khi duy trì ngữ cảnh trong các cuộc trò chuyện dài hoặc phức tạp, thường dẫn đến câu trả lời thiếu sót hoặc rời rạc.
Nhưng mô hình RAG cho phép nhận biết ngữ cảnh bằng cách lấy thông tin trực tiếp từ các nguồn dữ liệu liên kết theo ngữ nghĩa.
Với thông tin bổ sung phù hợp với nhu cầu người dùng – như chatbot bán hàng có tích hợp danh mục sản phẩm – RAG giúp AI tham gia vào các cuộc trò chuyện có ngữ cảnh.
RAG hoạt động như thế nào?
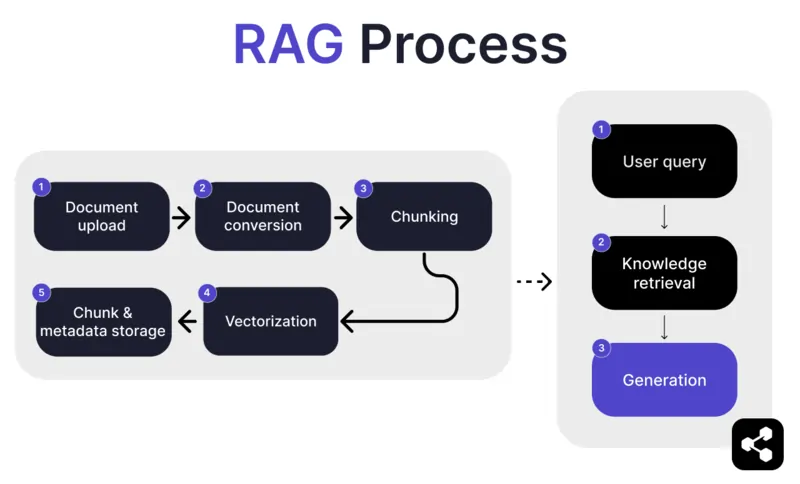
1. Tải lên tài liệu
Đầu tiên, người xây dựng tải lên một tài liệu hoặc tệp vào thư viện của AI agent. Tệp này có thể là trang web, PDF hoặc định dạng được hỗ trợ khác, tạo thành một phần cơ sở kiến thức của AI.
2. Chuyển đổi tài liệu
Vì có nhiều loại tệp khác nhau – PDF, trang web, v.v. – hệ thống sẽ chuyển đổi các tệp này sang định dạng văn bản chuẩn hóa, giúp AI dễ dàng xử lý và truy xuất thông tin liên quan.
3. Chia nhỏ và lưu trữ
Tài liệu đã chuyển đổi sẽ được chia thành các phần nhỏ, dễ quản lý, gọi là "chunk". Các phần này được lưu trữ trong cơ sở dữ liệu, cho phép AI agent tìm kiếm và truy xuất các đoạn liên quan một cách hiệu quả khi có truy vấn.
4. Truy vấn người dùng
Sau khi xây dựng xong cơ sở kiến thức, người dùng có thể đặt câu hỏi cho AI agent. Truy vấn này được xử lý bằng xử lý ngôn ngữ tự nhiên (NLP) để hiểu ý định của người dùng.
5. Truy xuất kiến thức
AI agent sẽ tìm kiếm trong các phần đã lưu trữ, sử dụng thuật toán truy xuất để xác định các thông tin liên quan nhất từ tài liệu đã tải lên nhằm trả lời câu hỏi của người dùng.
6. Sinh phản hồi
Cuối cùng, AI agent sẽ tạo ra câu trả lời bằng cách kết hợp thông tin đã truy xuất với khả năng của mô hình ngôn ngữ, tạo ra phản hồi mạch lạc, chính xác theo ngữ cảnh dựa trên truy vấn và dữ liệu đã lấy.
Các tính năng RAG nâng cao
Nếu bạn không phải là lập trình viên, bạn có thể sẽ ngạc nhiên khi biết rằng không phải tất cả các hệ thống RAG đều giống nhau.
Các hệ thống khác nhau sẽ xây dựng mô hình RAG khác nhau, tùy theo nhu cầu, trường hợp sử dụng hoặc kỹ năng của họ.
Một số nền tảng AI cung cấp các tính năng RAG nâng cao giúp tăng độ chính xác và độ tin cậy cho phần mềm AI của bạn.
Chia nhỏ theo ngữ nghĩa và chia nhỏ đơn giản
Chia nhỏ đơn giản là khi tài liệu được cắt thành các phần có kích thước cố định, ví dụ như chia văn bản thành các đoạn 500 từ mà không quan tâm đến ý nghĩa hay ngữ cảnh.
Chia nhỏ theo ngữ nghĩa thì ngược lại, chia tài liệu thành các phần có ý nghĩa dựa trên nội dung.
Cách này xét đến các điểm ngắt tự nhiên như đoạn văn hoặc chủ đề, đảm bảo mỗi phần chứa một thông tin liền mạch.
Trích dẫn bắt buộc
Đối với các ngành tự động hóa hội thoại rủi ro cao bằng AI – như tài chính hoặc y tế – trích dẫn giúp tăng niềm tin cho người dùng khi nhận thông tin.
Lập trình viên có thể yêu cầu mô hình RAG cung cấp trích dẫn cho bất kỳ thông tin nào được gửi đi.
Ví dụ, nếu một nhân viên hỏi chatbot AI về quyền lợi sức khỏe, chatbot có thể trả lời và cung cấp liên kết đến tài liệu quyền lợi nhân viên liên quan.
Xây dựng AI Agent RAG tùy chỉnh
Kết hợp sức mạnh của các LLM mới nhất với kiến thức doanh nghiệp độc quyền của bạn.
Botpress là nền tảng chatbot AI linh hoạt và có khả năng mở rộng không giới hạn.
Nó cho phép người dùng xây dựng bất kỳ loại AI agent hoặc chatbot nào cho mọi trường hợp sử dụng – và cung cấp hệ thống RAG tiên tiến nhất trên thị trường.
Tích hợp chatbot của bạn vào bất kỳ nền tảng hoặc kênh nào, hoặc chọn từ thư viện tích hợp sẵn. Bắt đầu với các hướng dẫn trên kênh YouTube của Botpress hoặc các khóa học miễn phí từ Botpress Academy.
Bắt đầu xây dựng ngay hôm nay. Miễn phí.
Câu hỏi thường gặp
1. RAG khác gì so với tinh chỉnh LLM?
RAG (Retrieval-Augmented Generation) khác với fine-tuning ở chỗ RAG giữ nguyên LLM gốc và bổ sung kiến thức bên ngoài khi chạy bằng cách truy xuất các tài liệu liên quan. Fine-tuning thì thay đổi trọng số của mô hình dựa trên dữ liệu huấn luyện, đòi hỏi nhiều tài nguyên tính toán hơn và phải thực hiện lại mỗi khi cập nhật.
2. Những loại nguồn dữ liệu nào không phù hợp cho RAG?
Các nguồn dữ liệu không phù hợp với RAG bao gồm các định dạng không phải văn bản như tài liệu quét, PDF dạng hình ảnh, tệp âm thanh không có bản ghi, và nội dung đã lỗi thời hoặc mâu thuẫn. Những loại dữ liệu này làm giảm độ chính xác của ngữ cảnh được truy xuất.
3. RAG so sánh như thế nào với các kỹ thuật học trong ngữ cảnh như prompt engineering?
RAG khác với prompt engineering ở chỗ nó truy xuất nội dung liên quan từ một kho kiến thức lớn đã được lập chỉ mục khi có truy vấn, thay vì dựa vào các ví dụ tĩnh được nhúng thủ công trong prompt. Điều này giúp RAG mở rộng tốt hơn và luôn cập nhật kiến thức mà không cần huấn luyện lại.
4. Tôi có thể sử dụng RAG với các LLM bên thứ ba như OpenAI, Anthropic hoặc Mistral không?
Có, bạn có thể sử dụng RAG với các LLM từ OpenAI, Anthropic, Mistral hoặc các nhà cung cấp khác bằng cách xử lý riêng quy trình truy xuất và gửi ngữ cảnh đã truy xuất đến LLM qua API của nó. RAG không phụ thuộc vào mô hình, miễn là LLM hỗ trợ nhận ngữ cảnh qua prompt.
5. Việc bảo trì liên tục cho một AI agent sử dụng RAG sẽ như thế nào?
Bảo trì liên tục cho một AI agent sử dụng RAG bao gồm cập nhật kho kiến thức với các tài liệu mới hoặc đã chỉnh sửa, lập chỉ mục lại nội dung định kỳ, đánh giá chất lượng truy xuất, điều chỉnh kích thước đoạn và phương pháp embedding, cũng như giám sát phản hồi của agent để phát hiện các vấn đề lệch hướng hoặc ảo giác.



