.webp)



- RAG łączy wyszukiwanie danych z zaufanych źródeł z generowaniem przez LLM, zapewniając, że odpowiedzi AI są dokładne, trafne i oparte na rzeczywistej wiedzy biznesowej.
- W przeciwieństwie do samych LLM-ów, RAG ogranicza halucynacje, opierając odpowiedzi na konkretnych dokumentach, bazach danych lub zatwierdzonych treściach.
- RAG umożliwia korzystanie z aktualnych informacji, dzięki czemu systemy AI mogą odpowiadać na pytania dotyczące najnowszych zmian lub niszowych tematów, wykraczających poza statyczne dane treningowe LLM.
- Utrzymanie systemu RAG polega na regularnym aktualizowaniu danych, monitorowaniu wyników i udoskonalaniu metod wyszukiwania, aby zapewnić najlepszą wydajność w czasie.
RAG pozwala organizacjom wykorzystywać AI przy mniejszym ryzyku niż w przypadku tradycyjnego użycia LLM.
Generowanie wspomagane wyszukiwaniem zyskuje na popularności wraz z wdrażaniem rozwiązań AI w firmach. Wczesne czatboty korporacyjne popełniały ryzykowne błędy i generowały halucynacje.
RAG umożliwia firmom korzystanie z mocy LLM-ów, jednocześnie opierając generowane odpowiedzi na ich własnej wiedzy biznesowej.
Czym jest generowanie wspomagane wyszukiwaniem?
Retrieval-augmented generation (RAG) w AI to technika łącząca a) pobieranie odpowiednich zewnętrznych informacji i b) generowanie odpowiedzi przez AI, co zwiększa dokładność i trafność.
Zamiast polegać wyłącznie na generowaniu przez duże modele językowe (LLM), odpowiedzi modeli RAG opierają się na bazach wiedzy określonych przez twórcę agenta AI – np. stronie firmowej czy dokumencie z polityką HR.
RAG działa w dwóch głównych krokach:
1. Wyszukiwanie
Model wyszukuje i pobiera odpowiednie dane ze źródeł ustrukturyzowanych lub nieustrukturyzowanych (np. bazy danych, pliki PDF, pliki HTML lub inne dokumenty). Źródła te mogą być ustrukturyzowane (np. tabele) lub nieustrukturyzowane (np. zatwierdzone strony internetowe).
2. Generowanie
Po wyszukaniu informacje są przekazywane do LLM. LLM wykorzystuje te dane do wygenerowania odpowiedzi w języku naturalnym, łącząc zatwierdzone informacje ze swoimi możliwościami językowymi, aby tworzyć dokładne, naturalne i zgodne z marką odpowiedzi.
Przykłady zastosowań RAG
Po co stosować RAG? Pozwala organizacjom dostarczać trafne, rzetelne i dokładne odpowiedzi.
RAG to bezpośredni sposób na zmniejszenie ryzyka błędnych odpowiedzi lub halucynacji generowanych przez LLM.
Przykład 1: Kancelaria prawna
Kancelaria prawna może wykorzystać RAG w systemie AI do:
- Wyszukiwanie odpowiednich orzeczeń, precedensów i wyroków sądowych w bazach dokumentów podczas badań.
- Tworzenie podsumowań spraw poprzez wyodrębnianie kluczowych faktów z akt i wcześniejszych orzeczeń.
- Automatyczne przekazywanie pracownikom aktualnych informacji o zmianach w przepisach.
Przykład 2: Agencja nieruchomości
Agencja nieruchomości może wykorzystać RAG w systemie AI do:
- Podsumowywanie danych z historii transakcji nieruchomości i statystyk przestępczości w okolicy.
- Odpowiadanie na pytania prawne dotyczące transakcji nieruchomości, powołując się na lokalne przepisy i regulacje.
- Usprawnianie procesów wyceny poprzez pobieranie danych z raportów o stanie nieruchomości, trendów rynkowych i historycznych sprzedaży.
Przykład 3: Sklep e-commerce
Sklep e-commerce może wykorzystać RAG w systemie AI do:
- Zbieranie informacji o produktach, specyfikacjach i recenzjach z bazy firmy, aby przygotować spersonalizowane rekomendacje produktowe.
- Pobieranie historii zamówień w celu tworzenia spersonalizowanych doświadczeń zakupowych dostosowanych do preferencji użytkownika.
- Tworzenie ukierunkowanych kampanii e-mailowych poprzez pobieranie danych o segmentacji klientów i łączenie ich z ostatnimi wzorcami zakupowymi.
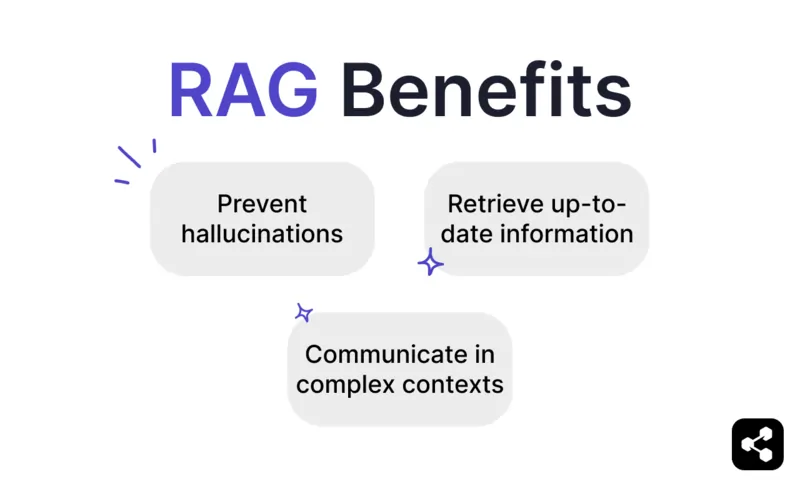
Korzyści z RAG
Każdy, kto korzystał z ChatGPT lub Claude, wie, że LLM-y mają niewiele wbudowanych zabezpieczeń.
Bez odpowiedniego nadzoru mogą generować nieprawdziwe lub nawet szkodliwe informacje, co czyni je niepewnymi w rzeczywistych zastosowaniach.
RAG rozwiązuje ten problem, opierając odpowiedzi na zaufanych, aktualnych źródłach danych, znacząco ograniczając te ryzyka.
Zapobieganie halucynacjom i nieścisłościom
Tradycyjne modele językowe często generują halucynacje — odpowiedzi brzmiące wiarygodnie, ale niezgodne z faktami lub nieistotne.
RAG ogranicza halucynacje, opierając odpowiedzi na wiarygodnych i bardzo trafnych źródłach danych.
Etap wyszukiwania zapewnia, że model odwołuje się do dokładnych, aktualnych informacji, co znacząco zmniejsza ryzyko halucynacji i zwiększa wiarygodność.
Pobieranie aktualnych informacji
Choć LLM-y są potężnym narzędziem do wielu zadań, nie są w stanie dostarczać rzetelnych informacji o rzadkich lub najnowszych wydarzeniach – w tym o specyficznej wiedzy biznesowej.
RAG pozwala jednak modelowi pobierać informacje w czasie rzeczywistym z dowolnego źródła, w tym stron internetowych, tabel czy baz danych.
To sprawia, że jeśli źródło prawdy jest aktualizowane, model będzie odpowiadał na podstawie najnowszych informacji.
Komunikacja w złożonych kontekstach
Kolejną słabością tradycyjnych LLM-ów jest utrata informacji kontekstowych.
LLM-y mają trudności z utrzymaniem kontekstu w długich lub złożonych rozmowach, co często prowadzi do niepełnych lub fragmentarycznych odpowiedzi.
Model RAG umożliwia jednak zachowanie kontekstu, pobierając informacje bezpośrednio z powiązanych semantycznie źródeł danych.
Dzięki dodatkowym informacjom dostosowanym do potrzeb użytkownika – jak czatbot sprzedażowy wyposażony w katalog produktów – RAG pozwala agentom AI prowadzić rozmowy kontekstowe.
Jak działa RAG?
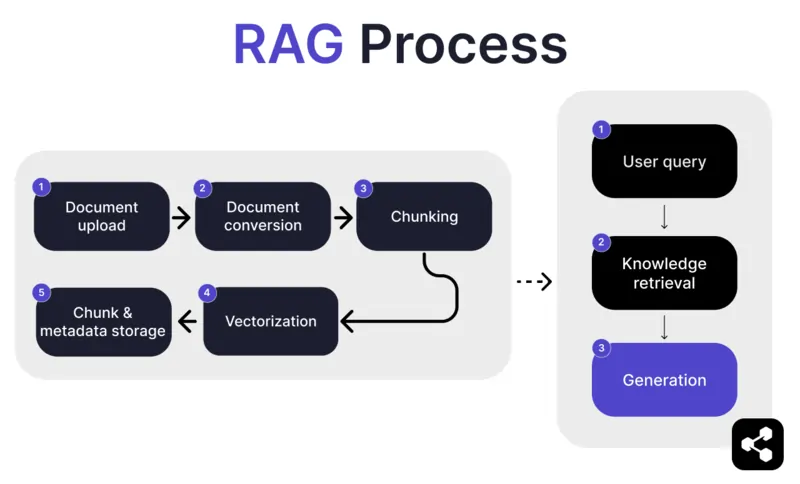
1. Przesyłanie dokumentu
Najpierw twórca przesyła dokument lub plik do biblioteki swojego agenta AI. Może to być strona internetowa, plik PDF lub inny obsługiwany format, który staje się częścią bazy wiedzy AI.
2. Konwersja dokumentu
Ponieważ istnieje wiele typów plików – PDF, strony internetowe itp. – system konwertuje je do ustandaryzowanego formatu tekstowego, co ułatwia AI przetwarzanie i wyszukiwanie potrzebnych informacji.
3. Dzielenie na fragmenty i przechowywanie
Przekonwertowany dokument jest dzielony na mniejsze, łatwe do zarządzania fragmenty. Te fragmenty są przechowywane w bazie danych, co pozwala agentowi AI efektywnie wyszukiwać i pobierać odpowiednie sekcje podczas zapytania.
4. Zapytanie użytkownika
Po skonfigurowaniu baz wiedzy użytkownik może zadać agentowi AI pytanie. Zapytanie jest analizowane przy użyciu przetwarzania języka naturalnego (NLP), aby zrozumieć intencję użytkownika.
5. Wyszukiwanie wiedzy
Agent AI przeszukuje zapisane fragmenty, wykorzystując algorytmy wyszukiwania, aby znaleźć najbardziej odpowiednie informacje z przesłanych dokumentów, które mogą odpowiedzieć na pytanie użytkownika.
6. Generowanie
Na końcu agent AI generuje odpowiedź, łącząc pobrane informacje ze swoimi możliwościami językowymi, tworząc spójną, kontekstowo trafną odpowiedź na podstawie zapytania i znalezionych danych.
Zaawansowane funkcje RAG
Jeśli nie jesteś deweloperem, możesz się zdziwić, że nie każdy RAG działa tak samo.
Różne systemy tworzą różne modele RAG, w zależności od potrzeb, zastosowań lub umiejętności.
Niektóre platformy AI oferują zaawansowane funkcje RAG, które mogą dodatkowo zwiększyć dokładność i niezawodność Twojego oprogramowania AI.
Chunking semantyczny vs naiwny
Naiwny chunking polega na dzieleniu dokumentu na fragmenty o stałej wielkości, np. na sekcje po 500 słów, bez względu na znaczenie czy kontekst.
Chunking semantyczny natomiast dzieli dokument na sensowne części w oparciu o treść.
Uwzględnia naturalne podziały, takie jak akapity czy tematy, dzięki czemu każdy fragment zawiera spójną informację.
Obowiązkowe cytowania
W branżach, które automatyzują rozmowy wysokiego ryzyka z AI – jak finanse czy opieka zdrowotna – cytowania pomagają budować zaufanie użytkowników do otrzymywanych informacji.
Deweloperzy mogą skonfigurować swoje modele RAG tak, aby do każdej przekazywanej informacji dołączały cytaty.
Na przykład, jeśli pracownik zapyta czatbota AI o informacje dotyczące świadczeń zdrowotnych, czatbot może odpowiedzieć i podać link do odpowiedniego dokumentu z benefitami pracowniczymi.
Zbuduj własnego agenta AI z RAG
Połącz moc najnowszych LLM-ów z unikalną wiedzą swojej firmy.
Botpress to elastyczna i nieograniczenie rozbudowywalna platforma do tworzenia czatbotów AI.
Pozwala użytkownikom budować dowolnego agenta AI lub czatbota do każdego zastosowania – i oferuje najbardziej zaawansowany system RAG na rynku.
Zintegruj swojego czatbota z dowolną platformą lub kanałem albo wybierz coś z naszej biblioteki gotowych integracji. Zacznij od samouczków na kanale YouTube Botpress lub bezpłatnych kursów w Botpress Academy.
Rozpocznij budowę już dziś. To nic nie kosztuje.
Najczęstsze pytania
1. Czym różni się RAG od dostrajania LLM?
RAG (Retrieval-Augmented Generation) różni się od fine-tuningu tym, że RAG pozostawia oryginalny LLM bez zmian i w czasie rzeczywistym wprowadza zewnętrzną wiedzę poprzez wyszukiwanie odpowiednich dokumentów. Fine-tuning polega na modyfikacji wag modelu przy użyciu danych treningowych, co wymaga większej mocy obliczeniowej i musi być powtarzane przy każdej aktualizacji.
2. Jakie rodzaje źródeł danych nie nadają się do RAG?
Do źródeł danych nieodpowiednich dla RAG należą formaty inne niż tekstowe, takie jak zeskanowane dokumenty, PDF-y oparte na obrazach, pliki audio bez transkrypcji oraz nieaktualne lub sprzeczne treści. Takie dane obniżają dokładność wyszukiwanego kontekstu.
3. Jak RAG wypada w porównaniu z technikami uczenia się w kontekście, takimi jak inżynieria promptów?
RAG różni się od inżynierii promptów tym, że podczas zapytania pobiera odpowiednie treści z dużej, zaindeksowanej bazy wiedzy, zamiast polegać na statycznych, ręcznie dodanych przykładach w promptach. Dzięki temu RAG lepiej się skaluję i pozwala utrzymać aktualność wiedzy bez konieczności ponownego trenowania.
4. Czy mogę używać RAG z zewnętrznymi LLM-ami, takimi jak OpenAI, Anthropic lub Mistral?
Tak, możesz używać RAG z LLM-ami od OpenAI, Anthropic, Mistral lub innych, obsługując proces wyszukiwania niezależnie i przesyłając znaleziony kontekst do LLM-a przez jego API. RAG jest niezależny od modelu, o ile LLM umożliwia przekazywanie kontekstu w promptach.
5. Jak wygląda bieżąca obsługa agenta AI z RAG?
Bieżąca obsługa agenta AI z RAG obejmuje aktualizowanie bazy wiedzy o nowe lub poprawione dokumenty, okresowe ponowne indeksowanie treści, ocenę jakości wyszukiwania, dostosowywanie wielkości fragmentów i metod embeddingu oraz monitorowanie odpowiedzi agenta pod kątem błędów lub halucynacji.



