.webp)



- RAG kombiniert das Abrufen aus vertrauenswürdigen Daten mit der Generierung durch LLMs und sorgt so dafür, dass KI-Antworten genau, relevant und auf echtem Unternehmenswissen basieren.
- Im Gegensatz zu reinen LLMs reduziert RAG Halluzinationen, indem Antworten auf bestimmte Dokumente, Datenbanken oder freigegebene Inhalte gestützt werden.
- RAG unterstützt aktuelle Informationen und ermöglicht es KI-Systemen, Fragen zu jüngsten Änderungen oder Nischenthemen zu beantworten, die über die statischen Trainingsdaten eines LLM hinausgehen.
- Die Pflege eines RAG-Systems umfasst das Aktualisieren der Daten, die Überwachung der Ausgaben und die Optimierung der Abrufmethoden, um dauerhaft die beste Leistung zu erzielen.
Mit RAG können Unternehmen KI einsetzen – mit weniger Risiko als bei herkömmlicher LLM-Nutzung.
Retrieval-Augmented Generation wird immer beliebter, da mehr Unternehmen KI-Lösungen einführen. Frühe Enterprise-Chatbots führten zu riskanten Fehlern und Halluzinationen.
RAG ermöglicht es Unternehmen, die Leistungsfähigkeit von LLMs zu nutzen und dabei die generierten Ergebnisse auf ihr spezifisches Unternehmenswissen zu stützen.
Was ist Retrieval-Augmented Generation?
Retrieval-augmented Generation (RAG) in der KI kombiniert a) das Abrufen relevanter externer Informationen und b) KI-generierte Antworten, um Genauigkeit und Relevanz zu erhöhen.
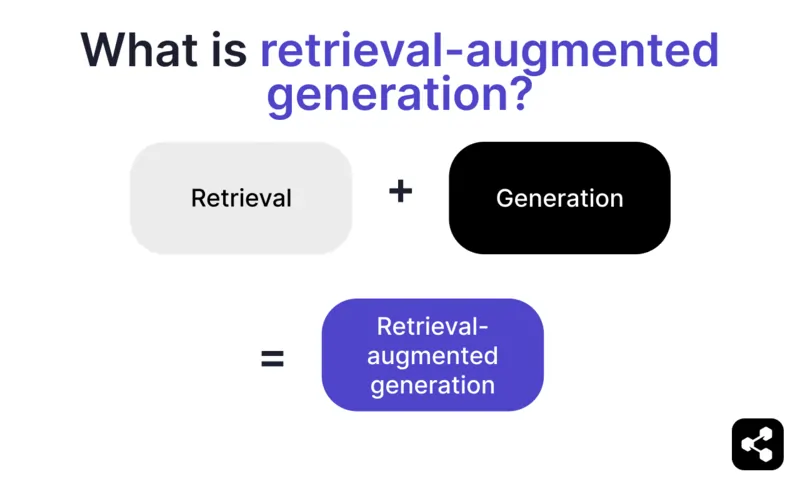
Statt sich nur auf die Generierung durch Large Language Models (LLMs) zu verlassen, werden die Antworten von RAG-Modellen durch Wissensdatenbanken bestimmt, die vom KI-Agenten-Ersteller festgelegt werden – etwa die Unternehmenswebsite oder ein HR-Dokument.
RAG arbeitet in zwei Hauptschritten:
1. Abruf
Das Modell sucht nach relevanten Daten in strukturierten oder unstrukturierten Quellen (z. B. Datenbanken, PDFs, HTML-Dateien oder anderen Dokumenten). Diese Quellen können strukturiert (z. B. Tabellen) oder unstrukturiert (z. B. freigegebene Webseiten) sein.
2. Generierung
Nach dem Abruf werden die Informationen in das LLM eingespeist. Das LLM nutzt diese Informationen, um eine Antwort in natürlicher Sprache zu generieren, indem es die freigegebenen Daten mit seinen eigenen sprachlichen Fähigkeiten kombiniert und so genaue, menschenähnliche und markenkonforme Antworten erstellt.
Beispiele für RAG-Anwendungsfälle
Wozu dient RAG? Es ermöglicht Unternehmen, relevante, informative und genaue Ergebnisse zu liefern.
RAG ist ein direkter Weg, das Risiko ungenauer LLM-Ausgaben oder Halluzinationen zu verringern.
Beispiel 1: Anwaltskanzlei
Eine Anwaltskanzlei könnte RAG in einem KI-System nutzen, um:
- Relevante Urteile, Präzedenzfälle und rechtliche Entscheidungen aus Dokumentendatenbanken während der Recherche zu suchen.
- Fallzusammenfassungen zu erstellen, indem Schlüsselfakten aus Fallakten und früheren Urteilen extrahiert werden.
- Mitarbeitern automatisch relevante regulatorische Updates bereitzustellen.
Beispiel 2: Immobilienagentur
Eine Immobilienagentur könnte RAG in einem KI-System nutzen, um:
- Daten aus Immobilienverkaufshistorien und Kriminalstatistiken von Stadtvierteln zusammenzufassen.
- Rechtliche Fragen zu Immobilientransaktionen zu beantworten, indem lokale Immobiliengesetze und Vorschriften zitiert werden.
- Bewertungsprozesse zu optimieren, indem Daten aus Zustandsberichten, Markttrends und historischen Verkäufen herangezogen werden.
Beispiel 3: E-Commerce-Shop
Ein E-Commerce-Unternehmen könnte RAG in einem KI-System nutzen, um:
- Produktinformationen, Spezifikationen und Bewertungen aus der Firmendatenbank zu sammeln, um personalisierte Produktempfehlungen zu ermöglichen.
- Bestellhistorien abzurufen, um individuelle Einkaufserlebnisse an die Vorlieben der Nutzer anzupassen.
- Gezielte E-Mail-Kampagnen zu erstellen, indem Kundensegmentierungsdaten abgerufen und mit aktuellen Kaufmustern kombiniert werden.
Vorteile von RAG
Wie jeder weiß, der ChatGPT oder Claude genutzt hat, verfügen LLMs nur über minimale Schutzmechanismen.
Ohne angemessene Kontrolle können sie ungenaue oder sogar schädliche Informationen erzeugen, was sie für reale Einsätze unzuverlässig macht.
RAG bietet eine Lösung, indem Antworten auf vertrauenswürdigen, aktuellen Datenquellen basieren und so diese Risiken deutlich reduziert werden.
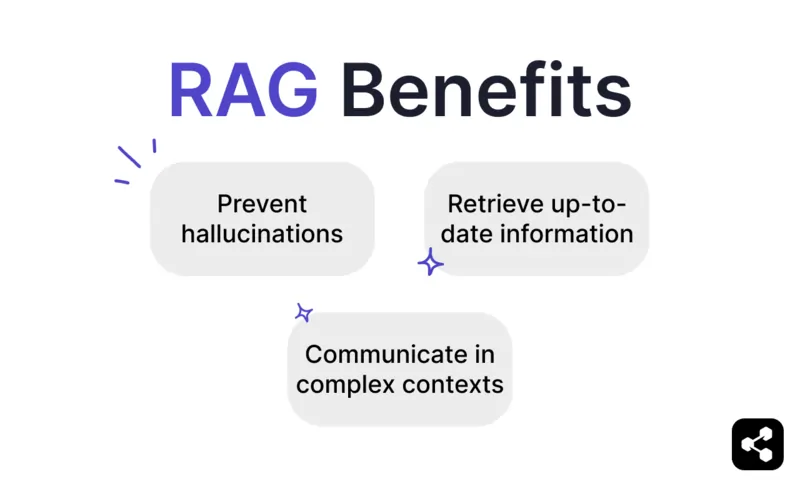
Halluzinationen und Ungenauigkeiten verhindern
Traditionelle Sprachmodelle erzeugen häufig Halluzinationen – Antworten, die überzeugend klingen, aber sachlich falsch oder irrelevant sind.
RAG verringert Halluzinationen, indem Antworten auf zuverlässigen und hochrelevanten Datenquellen basieren.
Der Abrufschritt stellt sicher, dass das Modell auf genaue, aktuelle Informationen zugreift, was die Wahrscheinlichkeit von Halluzinationen deutlich senkt und die Zuverlässigkeit erhöht.
Aktuelle Informationen abrufen
LLMs sind zwar ein leistungsfähiges Werkzeug für viele Aufgaben, können aber keine genauen Informationen zu seltenen oder aktuellen Themen liefern – einschließlich unternehmensspezifischem Wissen.
Mit RAG kann das Modell jedoch Echtzeitinformationen aus beliebigen Quellen abrufen, darunter Webseiten, Tabellen oder Datenbanken.
Sofern eine zuverlässige Quelle aktuell ist, liefert das Modell stets aktuelle Informationen.
Kommunikation in komplexen Kontexten
Ein weiteres Problem bei der herkömmlichen LLM-Nutzung ist der Verlust von Kontextinformationen.
LLMs haben Schwierigkeiten, den Kontext in langen oder komplexen Gesprächen aufrechtzuerhalten. Das führt oft zu unvollständigen oder fragmentierten Antworten.
Ein RAG-Modell ermöglicht hingegen Kontextbewusstsein, indem Informationen direkt aus semantisch verknüpften Datenquellen abgerufen werden.
Mit zusätzlichen, gezielt auf die Nutzerbedürfnisse zugeschnittenen Informationen – etwa bei einem Vertriebs-Chatbot mit Produktkatalog – können KI-Agenten mit RAG an kontextbezogenen Gesprächen teilnehmen.
Wie funktioniert RAG?
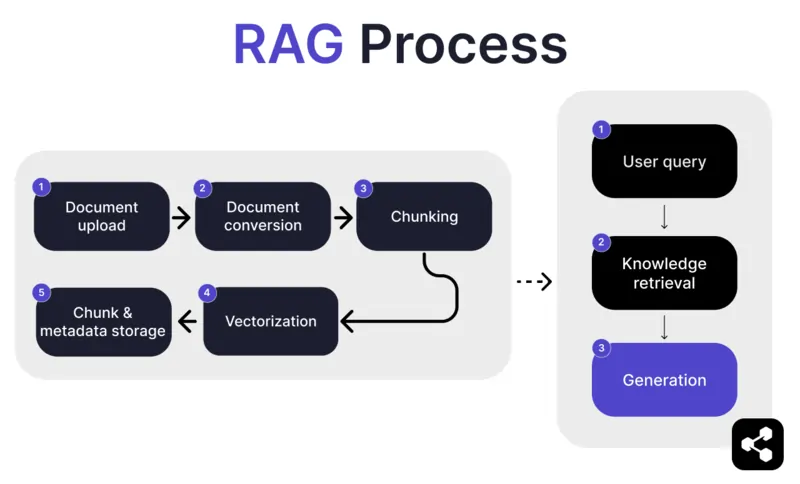
1. Dokumenten-Upload
Zunächst lädt der Ersteller ein Dokument oder eine Datei in die Bibliothek seines KI-Agenten hoch. Die Datei kann eine Webseite, ein PDF oder ein anderes unterstütztes Format sein und bildet einen Teil der Wissensbasis der KI.
2. Dokumentenkonvertierung
Da es viele Dateitypen gibt – PDFs, Webseiten usw. – wandelt das System diese Dateien in ein standardisiertes Textformat um, damit die KI sie leichter verarbeiten und relevante Informationen abrufen kann.
3. Aufteilung und Speicherung
Das konvertierte Dokument wird dann in kleinere, handhabbare Abschnitte, sogenannte Chunks, unterteilt. Diese Chunks werden in einer Datenbank gespeichert, sodass der KI-Agent bei einer Anfrage effizient relevante Abschnitte durchsuchen und abrufen kann.
4. Nutzeranfrage
Nachdem die Wissensdatenbanken eingerichtet sind, kann ein Nutzer dem KI-Agenten eine Frage stellen. Die Anfrage wird mit Natural Language Processing (NLP) verarbeitet, um zu verstehen, was der Nutzer wissen möchte.
5. Wissensabruf
Der KI-Agent durchsucht die gespeicherten Chunks und verwendet Abrufalgorithmen, um die relevantesten Informationen aus den hochgeladenen Dokumenten zu finden, die die Nutzerfrage beantworten können.
6. Generierung
Abschließend generiert der KI-Agent eine Antwort, indem er die abgerufenen Informationen mit seinen Sprachmodell-Fähigkeiten kombiniert und eine kohärente, kontextuell passende Antwort auf Grundlage der Anfrage und der gefundenen Daten erstellt.
Erweiterte RAG-Funktionen
Wenn Sie kein Entwickler sind, könnte es Sie überraschen zu erfahren, dass nicht jedes RAG gleich ist.
Je nach Bedarf, Anwendungsfall oder Fähigkeiten werden unterschiedliche RAG-Modelle entwickelt.
Einige KI-Plattformen bieten erweiterte RAG-Funktionen, mit denen Sie die Genauigkeit und Zuverlässigkeit Ihrer KI-Software weiter steigern können.
Semantische vs. naive Aufteilung
Bei naiver Aufteilung wird ein Dokument in Abschnitte fester Größe unterteilt, zum Beispiel in 500-Wörter-Blöcke, unabhängig von Bedeutung oder Kontext.
Bei der semantischen Aufteilung hingegen wird das Dokument anhand des Inhalts in sinnvolle Abschnitte unterteilt.
Dabei werden natürliche Brüche wie Absätze oder Themen berücksichtigt, sodass jeder Abschnitt einen zusammenhängenden Informationsblock enthält.
Pflichtzitate
In Branchen, die risikoreiche Gespräche mit KI automatisieren – etwa im Finanz- oder Gesundheitswesen – können Quellenangaben das Vertrauen der Nutzer stärken.
Entwickler können ihre RAG-Modelle so konfigurieren, dass für jede bereitgestellte Information eine Quelle angegeben wird.
Fragt beispielsweise ein Mitarbeiter einen KI-Chatbot nach Informationen zu Sozialleistungen, kann der Chatbot antworten und einen Link zum entsprechenden Dokument mit den Mitarbeiterleistungen bereitstellen.
Einen eigenen RAG-KI-Agenten erstellen
Kombinieren Sie die Leistungsfähigkeit der neuesten LLMs mit Ihrem einzigartigen Unternehmenswissen.
Botpress ist eine flexible und unbegrenzt erweiterbare KI-Chatbot-Plattform.
Sie ermöglicht es Nutzern, jeden beliebigen KI-Agenten oder Chatbot für jeden Anwendungsfall zu erstellen – und bietet das fortschrittlichste RAG-System auf dem Markt.
Integrieren Sie Ihren Chatbot in jede Plattform oder jeden Kanal oder wählen Sie aus unserer Bibliothek mit vorgefertigten Integrationen. Starten Sie mit Tutorials auf dem Botpress YouTube-Kanal oder mit kostenlosen Kursen der Botpress Academy.
Jetzt starten. Kostenlos.
FAQs
1. Worin unterscheidet sich RAG vom Fine-Tuning eines LLM?
RAG (Retrieval-Augmented Generation) unterscheidet sich vom Fine-Tuning, da bei RAG das ursprüngliche LLM unverändert bleibt und externes Wissen zur Laufzeit durch das Abrufen relevanter Dokumente eingebracht wird. Beim Fine-Tuning werden die Modellgewichte mit Trainingsdaten angepasst, was mehr Rechenleistung erfordert und bei jeder Aktualisierung wiederholt werden muss.
2. Welche Arten von Datenquellen sind für RAG nicht geeignet?
Für RAG ungeeignete Datenquellen sind Formate, die nicht aus Text bestehen, wie gescannte Dokumente, PDF-Dateien auf Bildbasis, Audiodateien ohne Transkripte sowie veraltete oder widersprüchliche Inhalte. Solche Daten verringern die Genauigkeit des abgerufenen Kontexts.
3. Wie schneidet RAG im Vergleich zu In-Context-Learning-Techniken wie Prompt Engineering ab?
RAG unterscheidet sich vom Prompt Engineering, indem es zur Abfragezeit relevante Inhalte aus einer großen, indizierten Wissensdatenbank abruft, anstatt sich auf statische, manuell eingebettete Beispiele im Prompt zu verlassen. Dadurch ist RAG besser skalierbar und kann aktuelles Wissen bereitstellen, ohne dass ein erneutes Training nötig ist.
4. Kann ich RAG mit externen LLMs wie OpenAI, Anthropic oder Mistral verwenden?
Ja, Sie können RAG mit LLMs von OpenAI, Anthropic, Mistral oder anderen nutzen, indem Sie die Retrieval-Pipeline unabhängig betreiben und den abgerufenen Kontext über die API an das LLM senden. RAG ist modellunabhängig, solange das LLM kontextuelle Eingaben über Prompts unterstützt.
5. Wie sieht die laufende Wartung eines RAG-fähigen KI-Agenten aus?
Die laufende Wartung eines RAG-fähigen KI-Agenten umfasst das Aktualisieren der Wissensdatenbank mit neuen oder korrigierten Dokumenten, das regelmäßige Reindizieren der Inhalte, die Bewertung der Retrieval-Qualität, das Anpassen von Chunk-Größe und Embedding-Methoden sowie das Überwachen der Agentenantworten auf Abweichungen oder Halluzinationen.



