.webp)



- RAGは信頼できるデータからの検索とLLMによる生成を組み合わせることで、AIの応答が正確で関連性が高く、実際のビジネス知識に基づいたものとなります。
- 純粋なLLMとは異なり、RAGは特定のドキュメントやデータベース、公認コンテンツに根拠を持たせることで、誤った生成(ハルシネーション)を減らします。
- RAGは最新情報の取得をサポートし、AIシステムがLLMの静的な学習データを超えて、最近の変更やニッチな話題にも対応できるようにします。
- RAGシステムを維持するには、データを最新に保ち、出力を監視し、検索手法を継続的に改善することが重要です。
RAGを使うことで、従来のLLM利用よりもリスクを抑えつつ、AIを業務に活用できます。
リトリーバル拡張生成は、より多くの企業がAIソリューションを導入する中で注目を集めています。初期のエンタープライズチャットボットでは、リスクのある誤りやハルシネーションが見られました。
RAGを使えば、企業はLLMの力を活かしつつ、自社固有のビジネス知識に基づいた生成結果を得ることができます。
リトリーバル拡張生成とは?
AIにおける検索拡張生成(RAG)は、a)外部情報の検索とb)AIによる回答生成を組み合わせ、正確性と関連性を高める手法です。
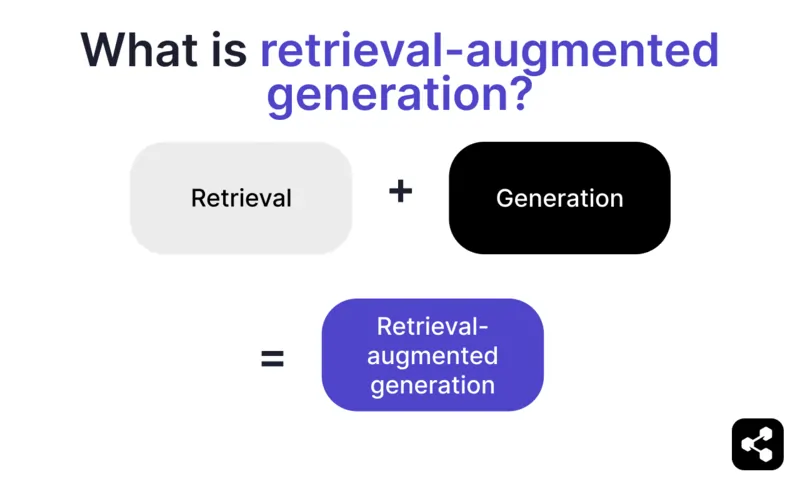
大規模言語モデル(LLM)による生成だけに頼らず、RAGモデルはAIエージェント作成者が指定したナレッジベース(企業のウェブページや人事ポリシー文書など)を参照して回答します。
RAGは主に2つのステップで動作します:
1. 検索
モデルが構造化または非構造化のデータソース(例:データベース、PDF、HTMLファイル、その他のドキュメント)から関連データを検索・取得します。これらのソースは、テーブルのような構造化データや、公認ウェブサイトのような非構造化データが含まれます。
2. 生成
検索後、取得した情報がLLMに入力されます。LLMはその情報を使い、承認されたデータと自身の言語能力を組み合わせて、正確で人間らしく、ブランドに合った応答を生成します。
RAGの活用事例
RAGの目的は何でしょうか?それは、組織が関連性が高く、有益で正確な出力を提供できるようにすることです。
RAGは、LLMによる不正確な出力やハルシネーションのリスクを直接的に減らす方法です。
例1:法律事務所
法律事務所がAIシステムでRAGを使う場合:
- 調査時に、ドキュメントデータベースから関連する判例や先例、法的判断を検索する。
- ケースファイルや過去の判決から主要な事実を抽出し、事例の要約を生成する。
- 従業員に対して、関連する法規制の最新情報を自動で提供する。
例2:不動産会社
不動産会社がAIシステムでRAGを使う場合:
- 物件の取引履歴や地域の犯罪統計データを要約する。
- 地元の不動産法や規制を引用しながら、物件取引に関する法律的な質問に答える。
- 物件の状態レポート、市場動向、過去の販売データから情報を取得し、査定プロセスを効率化する。
例3:ECストア
ECサイトがAIシステムでRAGを使う場合:
- 商品情報や仕様、レビューを社内データベースから集め、パーソナライズされた商品提案に活用する。
- 注文履歴を取得し、ユーザーの好みに合わせたカスタマイズされたショッピング体験を提供する。
- 顧客セグメントデータと最近の購入傾向を組み合わせて、ターゲットを絞ったメールキャンペーンを生成する。
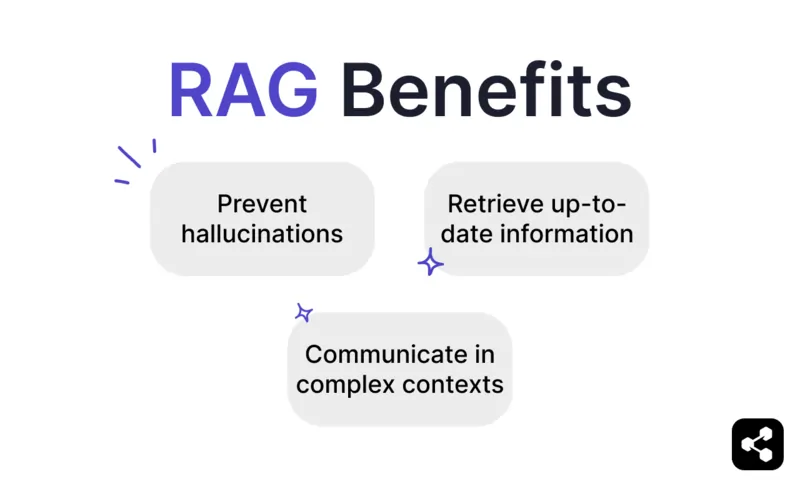
RAGのメリット
ChatGPTやClaudeを使ったことがある方なら分かる通り、LLMには最小限の安全対策しかありません。
適切な監督がなければ、不正確または有害な情報を生成する可能性があり、実際の運用には信頼性が不足します。
RAGは、信頼できる最新データソースに基づいて応答を生成することで、これらのリスクを大幅に低減します。
ハルシネーションや誤りを防ぐ
従来の言語モデルは、もっともらしく聞こえるが実際には誤った、あるいは無関係な応答(ハルシネーション)を生成しがちです。
RAGは、信頼性が高く極めて関連性のあるデータソースに基づいて応答を生成することで、ハルシネーションを抑制します。
検索ステップにより、モデルが正確で最新の情報を参照するため、ハルシネーションのリスクが大幅に減り、信頼性が向上します。
最新情報の取得
LLMは多くのタスクで強力ですが、珍しい情報や最近の出来事、独自のビジネス知識については正確な情報を提供できません。
しかしRAGを使えば、ウェブサイトやテーブル、データベースなど、あらゆるソースからリアルタイムの情報を取得できます。
信頼できる情報源が更新されていれば、モデルは常に最新情報で応答できます。
複雑な文脈でのコミュニケーション
従来のLLM利用のもう一つの弱点は、文脈情報の喪失です。
LLMは長い会話や複雑なやり取りで文脈を維持するのが苦手で、不完全または断片的な応答になりがちです。
しかしRAGモデルなら、意味的に関連したデータソースから直接情報を取得することで、文脈を把握できます。
ユーザーのニーズに合わせた追加情報(例:商品カタログを持つセールスチャットボット)を活用し、RAGはAIエージェントが文脈に沿った会話に参加できるようにします。
RAGはどのように動作するのか?
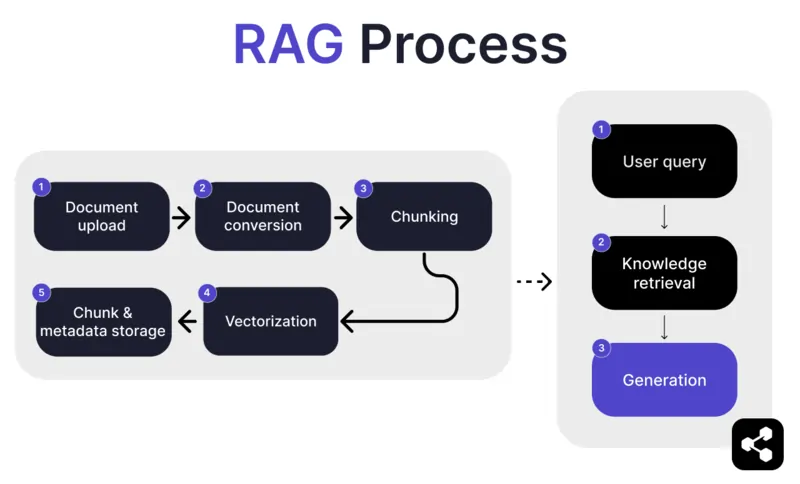
1. ドキュメントのアップロード
まず、作成者がAIエージェントのライブラリにドキュメントやファイルをアップロードします。ファイルはウェブページやPDFなど対応フォーマットで、AIの知識ベースの一部となります。
2. ドキュメントの変換
PDFやウェブページなど様々なファイル形式があるため、システムはこれらを標準化されたテキスト形式に変換し、AIが処理・検索しやすくします。
3. チャンク化と保存
変換されたドキュメントは、さらに小さく扱いやすい単位(チャンク)に分割されます。これらのチャンクはデータベースに保存され、AIエージェントがクエリ時に効率よく関連部分を検索・取得できるようになります。
4. ユーザーからの質問
知識ベースが準備できたら、ユーザーがAIエージェントに質問できます。クエリは自然言語処理(NLP)で解析され、ユーザーの意図を理解します。
5. 知識の検索
AIエージェントは保存されたチャンクの中から、アップロードされたドキュメントの中で質問に答えられる最も関連性の高い情報を検索アルゴリズムで探します。
6. 生成
最後に、AIエージェントは取得した情報と自身の言語モデル機能を組み合わせて、クエリと取得データに基づいた一貫性のある正確な応答を生成します。
高度なRAG機能
開発者でない方は、すべてのRAGが同じではないことに驚くかもしれません。
システムごとに、ニーズや用途、スキルレベルに応じて異なるRAGモデルが構築されます。
一部のAIプラットフォームでは、AIソフトウェアの精度と信頼性をさらに高める高度なRAG機能が提供されています。
セマンティックチャンク化と単純チャンク化
単純チャンク化は、意味や文脈に関係なく、ドキュメントを500語ごとなど一定のサイズで分割する方法です。
一方、セマンティックチャンク化は、内容に基づいて意味のある区切りでドキュメントを分割します。
段落やトピックなど自然な区切りを考慮し、それぞれのチャンクが一貫した情報を含むようにします。
必須の出典表示
金融や医療など、高リスクな会話をAIで自動化する業界では、情報の出典を示すことでユーザーの信頼を高めることができます。
開発者は、RAGモデルに送信する情報すべてに出典を付けるよう指示できます。
例えば、従業員がAIチャットボットに福利厚生について尋ねた場合、チャットボットは回答とともに関連する従業員向け福利厚生ドキュメントへのリンクを提供できます。
カスタムRAG AIエージェントを構築する
最新のLLMの力と、企業独自の知識を組み合わせましょう。
Botpressは柔軟で拡張性の高いAIチャットボットプラットフォームです。
あらゆる用途に合わせてAIエージェントやチャットボットを構築でき、市場で最も高度なRAGシステムを提供しています。
チャットボットをあらゆるプラットフォームやチャネルに統合したり、事前構築済みの統合ライブラリから選んだりできます。BotpressのYouTubeチャンネルのチュートリアルや、Botpress Academyの無料コースで始めましょう。
今すぐ構築を始めましょう。無料です。
よくある質問
1. RAGはLLMのファインチューニングとどう違うのですか?
RAG(検索拡張生成)はファインチューニングとは異なり、RAGは元のLLMを変更せず、関連するドキュメントを検索して外部知識を実行時に注入します。ファインチューニングはトレーニングデータを使ってモデルの重みを変更するため、より多くの計算資源が必要で、更新のたびに繰り返す必要があります。
2. RAGに適さないデータソースにはどのようなものがありますか?
RAGに適さないデータソースには、スキャン文書や画像ベースのPDF、文字起こしのない音声ファイル、古い情報や矛盾した内容などの非テキスト形式が含まれます。これらのデータは検索される文脈の精度を下げます。
3. RAGはプロンプトエンジニアリングのようなインコンテキスト学習手法と比べてどう違いますか?
RAGは、プロンプト内に静的で手動で埋め込まれた例を使うのではなく、大規模なインデックス化されたナレッジベースからクエリ時に関連コンテンツを検索します。これにより、RAGはよりスケーラブルで、再学習なしに最新の知識を維持できます。
4. RAGはOpenAI、Anthropic、Mistralなどのサードパーティ製LLMと併用できますか?
はい、OpenAI、Anthropic、MistralなどのLLMでも、検索パイプラインを独立して処理し、取得した文脈をAPI経由でLLMに送信することでRAGを利用できます。RAGはモデルに依存しませんが、LLMがプロンプトを通じて文脈入力を受け取れる必要があります。
5. RAG対応AIエージェントの継続的な運用・保守はどのようなものですか?
RAG対応AIエージェントの継続的な運用・保守には、新しいドキュメントや修正済みドキュメントでナレッジベースを更新すること、定期的なコンテンツの再インデックス化、検索品質の評価、チャンクサイズや埋め込み手法の調整、応答の変化や誤答(ハルシネーション)の監視などが含まれます。



