.webp)



- RAG combines retrieval from trusted data with LLM generation, ensuring AI responses are accurate, relevant, and grounded in real business knowledge.
- Unlike pure LLMs, RAG reduces hallucinations by anchoring answers in specific documents, databases, or approved content.
- RAG supports up-to-date information, enabling AI systems to answer questions about recent changes or niche topics beyond an LLM’s static training data.
- Maintaining a RAG system involves keeping data fresh, monitoring outputs, and refining retrieval methods for the best performance over time.
RAG allows organizations to put AI to work – with less risk than traditional LLM usage.
Retrieval-augmented generation is becoming more popular as more businesses introduce AI solutions. Early enterprise chatbots saw risky mistakes and hallucinations.
RAG allows companies to harness the power of LLMs while grounding generative output in their specific business knowledge.
What is retrieval-augmented generation?
Retrieval-augmented generation (RAG) in AI is a technique that combines a) retrieving relevant external information and b) AI-generated responses, improving accuracy and relevance.
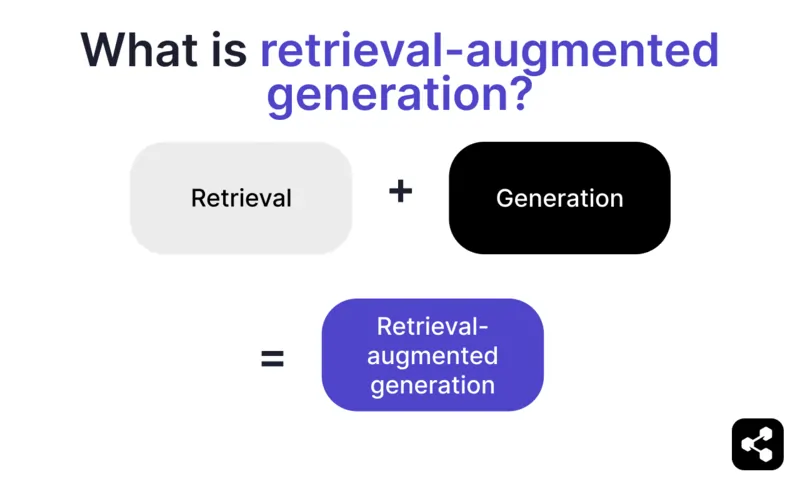
Instead of relying on the generation of large language models (LLMs), the responses from RAG models are informed by knowledge bases dictated by the AI agent builder – like a company’s webpage or a HR policy document.
RAG operates in two main steps:
1. Retrieval
The model searches for and retrieves relevant data from structured or unstructured sources (e.g. databases, PDFs, HTML files, or other documents). These sources can be structured (e.g. tables) or unstructured (e.g. approved websites).
2. Generation
After retrieval, information is fed into the LLM. The LLM uses the information to generate a natural-language response, combining the approved data with its own linguistic capabilities to create accurate, human-like, and on-brand responses.
Examples of RAG Use Cases
What’s the point of RAG? It allows organizations to provide relevant, informative, and accurate output.
RAG is a direct way to decrease the risk of inaccurate LLM output or hallucinations.
Example 1: Law Firm
A law firm might use a RAG in an AI system to:
- Search for relevant case laws, precedents, and legal rulings from document databases during research.
- Generate case summaries by extracting key facts from case files and past rulings.
- Automatically provide employees with relevant regulatory updates.
Example 2: Real Estate Agency
A real estate agency might use a RAG in an AI system to:
- Summarize data from property transaction histories and neighborhood crime statistics.
- Answer legal questions about property transactions by citing local property laws and regulations.
- Streamline appraisal processes by pulling data from property condition reports, market trends, and historical sales.
Example 3: E-Commerce Store
An e-commerce might use a RAG in an AI system to:
- Gather product information, specifications, and reviews from company database to inform personalized product recommendations.
- Retrieve order history to generate customized shopping experiences tailored to user preferences.
- Generate targeted email campaigns by retrieving customer segmentation data and combining it with recent purchase patterns.
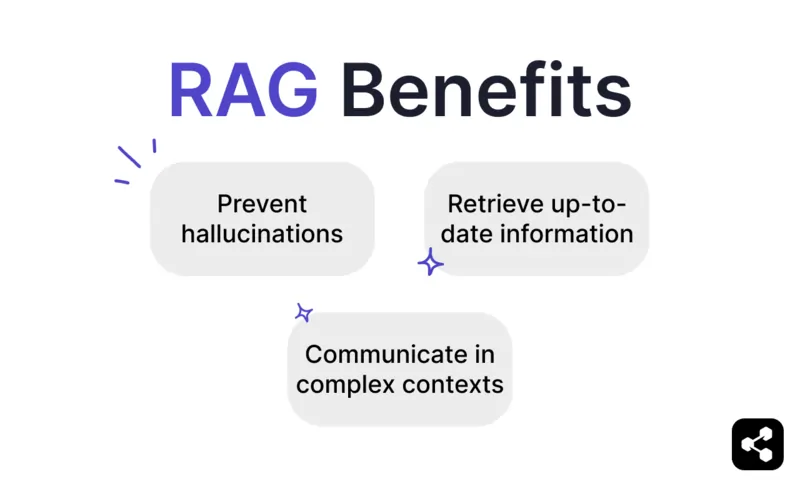
Benefits of RAG
As anyone who has queried ChatGPT or Claude knows, LLMs have minimal safeguards built in.
Without proper oversight, they can produce inaccurate or even harmful information, making them unreliable for real-world deployments.
RAG offers a solution by grounding responses in trusted, up-to-date data sources, significantly reducing these risks.
Prevent hallucinations and inaccuracies
Traditional language models often generate hallucinations — responses that sound convincing but are factually incorrect or irrelevant.
RAG mitigates hallucinations by grounding responses in reliable and hyper-relevant data sources.
The retrieval step ensures the model references accurate, up-to-date information, which significantly reduces the chance of hallucinations and heightens reliability.
Retrieve up-to-date information
While LLMs are a powerful tool for many tasks, they’re unable to provide accurate information about rare or recent information – including bespoke business knowledge.
But RAG allows the model to fetch real-time information from any source, including website, tables, or databases.
This ensures that, as long as a source of truth is updated, the model will respond with up-to-date information.
Communicate in complex contexts
Another weakness of traditional LLM use is the loss of contextual information.
LLMs struggle to maintain context in long or complex conversations. This often results in incomplete or fragmented responses.
But a RAG model allows for context awareness by pulling information directly from semantically linked data sources.
With extra information aimed specifically at the users’ needs – like a sales chatbot equipped with a product catalog – RAG allows AI agents to participate in contextual conversations.
How does RAG work?
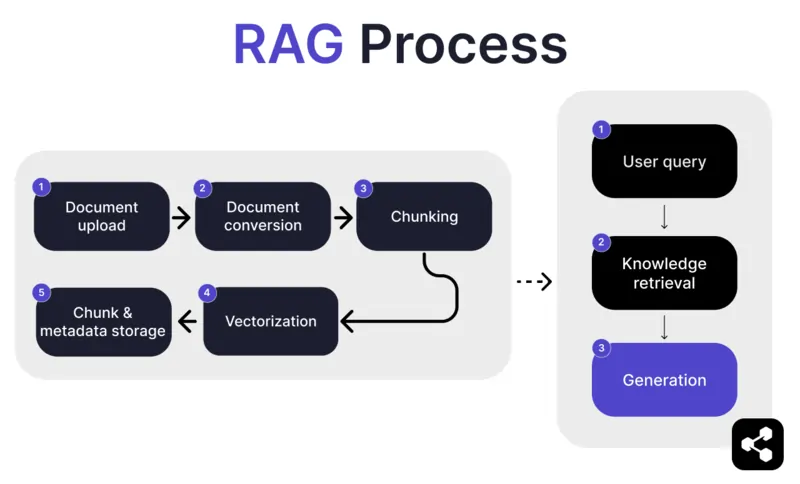
1. Document Upload
First, the builder uploads a document or file to their AI agent’s library. The file can be a webpage, PDF, or other supported format, which forms part of the AI’s knowledge base.
2. Document Conversion
Since there are many types of files – PDFs, webpages, etc. – the system converts these files into a standardized text format, making them easier for the AI to process and retrieve relevant information from.
3. Chunking and Storage
The converted document is then broken down into smaller, manageable pieces, or chunks. These chunks are stored in a database, allowing the AI agent to efficiently search and retrieve relevant sections during a query.
4. User Query
After the knowledge bases are set up, a user can ask the AI agent a question. The query is processed using natural language processing (NLP) to understand what the user is asking.
5. Knowledge Retrieval
The AI agent searches through the stored chunks, using retrieval algorithms to find the most relevant pieces of information from the uploaded documents that can answer the user's question.
6. Generation
Lastly, the AI agent will generate a response by combining the retrieved information with its language model capabilities, crafting a coherent, contextually accurate answer based on the query and the retrieved data.
Advanced RAG Features
If you’re not a developer, you might be surprised to learn that not all RAG is created equal.
Different systems will build different RAG models, depending on their need, use case, or skill ability.
Some AI platforms will offer advanced RAG features that can further enhance the accuracy and reliability of your AI software.
Semantic vs naive chunking
Naive chunking is when a document is split into fixed-size pieces, like cutting text into sections of 500 words, regardless of meaning or context.
Semantic chunking, on the other hand, breaks the document into meaningful sections based on the content.
It considers natural breaks, like paragraphs or topics, ensuring that each chunk contains a coherent piece of information.
Mandatory citations
For industries automating high-risk conversations with AI – like finance or healthcare – citations can help instil trust in users when receiving information.
Developers can instruct their RAG models to provide citations for any information sent.
For example, if an employee asks an AI chatbot for information about health benefits, the chatbot can respond and provide a link to the relevant employee benefits document.
Build a Custom RAG AI Agent
Combine the power of the latest LLMs with your unique enterprise knowledge.
Botpress is a flexible and endlessly extendable AI chatbot platform.
It allows users to build any type of AI agent or chatbot for any use case – and it offers the most advanced RAG system in the market.
Integrate your chatbot to any platform or channel, or choose from our pre-built integration library. Get started with tutorials from the Botpress YouTube channel or with free courses from Botpress Academy.
Start building today. It’s free.
FAQs
1. How is RAG different from fine-tuning an LLM?
RAG (Retrieval-Augmented Generation) is different from fine-tuning because RAG keeps the original LLM unchanged and injects external knowledge at runtime by retrieving relevant documents. Fine-tuning modifies the model's weights using training data, which requires more compute and must be repeated for every update.
2. What kinds of data sources are not suitable for RAG?
Data sources that are unsuitable for RAG include non-text formats like scanned documents, image-based PDFs, audio files without transcripts, and outdated or conflicting content. These types of data reduce the accuracy of retrieved context.
3. How does RAG compare to in-context learning techniques like prompt engineering?
RAG differs from prompt engineering by retrieving relevant content from a large indexed knowledge base at query time, rather than relying on static, manually embedded examples in the prompt. This allows RAG to scale better and maintain up-to-date knowledge without retraining.
4. Can I use RAG with third-party LLMs like OpenAI, Anthropic, or Mistral?
Yes, you can use RAG with LLMs from OpenAI, Anthropic, Mistral, or others by handling the retrieval pipeline independently and sending the retrieved context to the LLM via its API. RAG is model-agnostic as long as the LLM supports receiving contextual input through prompts.
5. What does ongoing maintenance look like for a RAG-enabled AI agent?
Ongoing maintenance for a RAG-enabled AI agent includes updating the knowledge base with new or corrected documents, re-indexing content periodically, evaluating retrieval quality, tuning chunk size and embedding methods, and monitoring the agent's responses for drift or hallucination issues.



