.webp)



- RAG ผสานการค้นหาข้อมูลจากแหล่งที่เชื่อถือได้เข้ากับการสร้างข้อความโดย LLM เพื่อให้คำตอบของ AI แม่นยำ ตรงประเด็น และอ้างอิงจากความรู้จริงของธุรกิจ
- ต่างจาก LLMs แบบเดิม RAG ลดปัญหาข้อมูลหลอน (hallucinations) ด้วยการยึดคำตอบกับเอกสาร ฐานข้อมูล หรือเนื้อหาที่ได้รับอนุมัติ
- RAG รองรับข้อมูลล่าสุด ทำให้ AI ตอบคำถามเกี่ยวกับการเปลี่ยนแปลงใหม่ ๆ หรือหัวข้อเฉพาะทางที่อยู่นอกเหนือข้อมูลฝึกของ LLM ได้
- การดูแลระบบ RAG ต้องอัปเดตข้อมูล ตรวจสอบผลลัพธ์ และปรับปรุงวิธีการค้นหาเพื่อให้ได้ประสิทธิภาพสูงสุดในระยะยาว
RAG ช่วยให้องค์กรนำ AI มาใช้ได้อย่างมั่นใจ โดยมีความเสี่ยงน้อยกว่าการใช้ LLM แบบเดิม
Retrieval-augmented generation กำลังได้รับความนิยมมากขึ้นเมื่อธุรกิจต่าง ๆ เริ่มใช้ AI ตัวอย่างแรก ๆ อย่าง แชทบอทสำหรับองค์กร เคยเกิดข้อผิดพลาดและข้อมูลหลอนบ่อยครั้ง
RAG ช่วยให้บริษัทใช้ศักยภาพของ LLMs พร้อมกับยึดเนื้อหาที่สร้างขึ้นกับความรู้เฉพาะของธุรกิจตนเอง
Retrieval-augmented generation คืออะไร?
Retrieval-augmented generation (RAG) ใน AI คือเทคนิคที่ผสมผสานระหว่าง a) การค้นหาข้อมูลภายนอกที่เกี่ยวข้อง และ b) การสร้างคำตอบโดย AI เพื่อเพิ่มความแม่นยำและความเกี่ยวข้อง
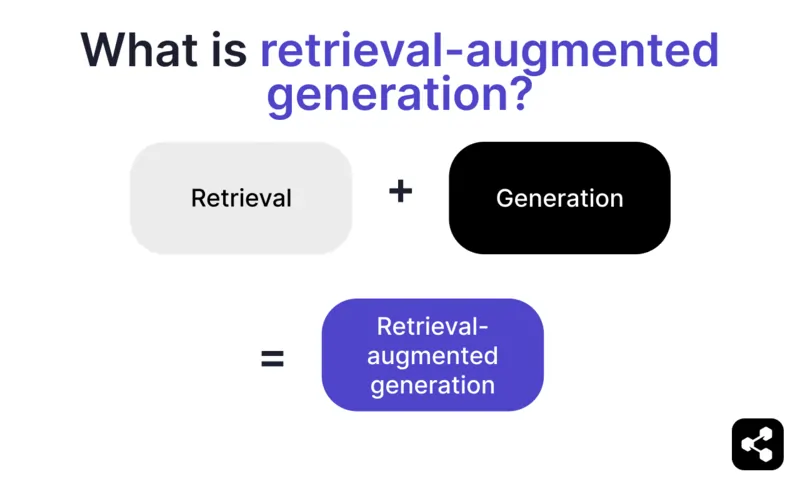
แทนที่จะพึ่งแค่การสร้างคำตอบจาก LLM คำตอบจาก RAG จะอ้างอิงจากฐานความรู้ที่ผู้สร้าง AI agent กำหนด เช่น หน้าเว็บบริษัท หรือเอกสารนโยบาย HR
RAG ทำงานหลัก ๆ สองขั้นตอน:
1. การค้นหา (Retrieval)
โมเดลจะค้นหาและดึงข้อมูลที่เกี่ยวข้องจากแหล่งข้อมูลที่มีโครงสร้างหรือไม่มีโครงสร้าง (เช่น ฐานข้อมูล, PDF, ไฟล์ HTML หรือเอกสารอื่น ๆ) แหล่งข้อมูลเหล่านี้อาจเป็นแบบมีโครงสร้าง (เช่น ตาราง) หรือไม่มีโครงสร้าง (เช่น เว็บไซต์ที่ได้รับอนุมัติ)
2. การสร้างข้อความ (Generation)
หลังจากค้นหา ข้อมูลจะถูกส่งเข้า LLM ซึ่ง LLM จะใช้ข้อมูลนั้นสร้างคำตอบเป็นภาษาธรรมชาติ โดยผสมผสานข้อมูลที่ได้รับอนุมัติกับความสามารถด้านภาษา เพื่อให้ได้คำตอบที่แม่นยำ เป็นธรรมชาติ และสอดคล้องกับแบรนด์
ตัวอย่างการใช้งาน RAG
RAG มีประโยชน์อย่างไร? ช่วยให้องค์กรให้ข้อมูลที่เกี่ยวข้อง ให้ความรู้ และให้ข้อมูลที่แม่นยำ
RAG เป็นวิธีตรงไปตรงมาในการลดความเสี่ยงจากข้อมูลผิดพลาดหรือหลอนของ LLM
ตัวอย่างที่ 1: สำนักงานกฎหมาย
สำนักงานกฎหมายอาจใช้ RAG ในระบบ AI เพื่อ:
- ค้นหากฎหมาย คำพิพากษา และบรรทัดฐานที่เกี่ยวข้องจากฐานข้อมูลเอกสารระหว่างการวิจัย
- สร้างสรุปคดีโดยดึงข้อเท็จจริงสำคัญจากแฟ้มคดีและคำพิพากษาเดิม
- แจ้งข่าวสารด้านกฎระเบียบที่เกี่ยวข้องให้พนักงานโดยอัตโนมัติ
ตัวอย่างที่ 2: บริษัทอสังหาริมทรัพย์
บริษัทอสังหาริมทรัพย์อาจใช้ RAG ในระบบ AI เพื่อ:
- สรุปข้อมูลจากประวัติการซื้อขายอสังหาริมทรัพย์และสถิติอาชญากรรมในพื้นที่
- ตอบคำถามด้านกฎหมายเกี่ยวกับการซื้อขายอสังหาริมทรัพย์โดยอ้างอิงกฎหมายและข้อบังคับท้องถิ่น
- ปรับปรุงกระบวนการประเมินราคาโดยดึงข้อมูลจากรายงานสภาพทรัพย์ แนวโน้มตลาด และประวัติการขาย
ตัวอย่างที่ 3: ร้านค้าอีคอมเมิร์ซ
ร้านค้าอีคอมเมิร์ซอาจใช้ RAG ในระบบ AI เพื่อ:
- รวบรวมข้อมูลสินค้า สเปก และรีวิวจากฐานข้อมูลบริษัท เพื่อแนะนำสินค้าแบบเฉพาะบุคคล
- ดึงประวัติการสั่งซื้อเพื่อสร้างประสบการณ์ช็อปปิ้งที่ปรับให้เหมาะกับแต่ละผู้ใช้
- สร้างแคมเปญอีเมลแบบเจาะจงกลุ่มเป้าหมายโดยดึงข้อมูลการแบ่งกลุ่มลูกค้าและผสมกับรูปแบบการซื้อล่าสุด
ข้อดีของ RAG
ใครที่เคยใช้ ChatGPT หรือ Claude จะทราบดีว่า LLMs มีระบบป้องกันข้อผิดพลาดน้อยมาก
หากไม่มีการควบคุมที่เหมาะสม อาจสร้างข้อมูลผิดหรือเป็นอันตรายได้ ทำให้ไม่เหมาะกับการใช้งานจริง
RAG แก้ปัญหานี้ด้วยการอ้างอิงคำตอบกับแหล่งข้อมูลที่เชื่อถือได้และอัปเดตล่าสุด ลดความเสี่ยงเหล่านี้ได้อย่างมาก
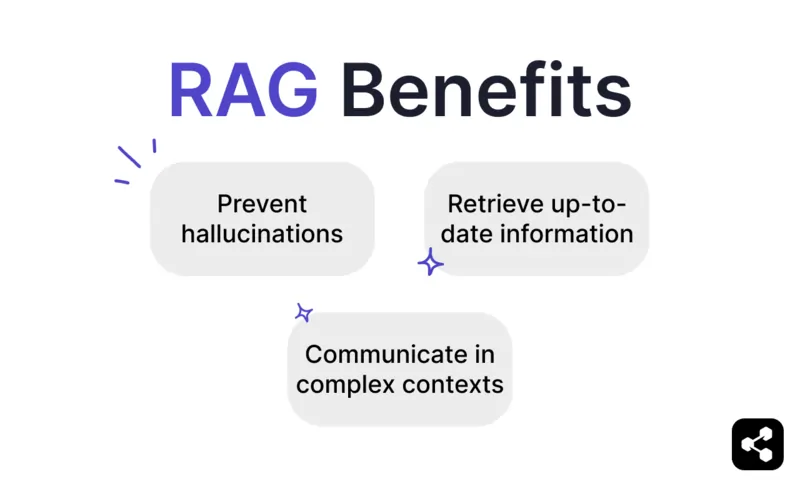
ป้องกันข้อมูลหลอนและข้อผิดพลาด
โมเดลภาษาแบบเดิมมักสร้างข้อมูลหลอน — คำตอบที่ฟังดูน่าเชื่อแต่ผิดหรือไม่เกี่ยวข้อง
RAG ลดปัญหานี้ด้วยการอ้างอิงคำตอบกับแหล่งข้อมูลที่เชื่อถือได้และตรงประเด็น
ขั้นตอนการค้นหาช่วยให้โมเดลอ้างอิงข้อมูลที่ถูกต้องและอัปเดต ลดโอกาสเกิดข้อมูลหลอนและเพิ่มความน่าเชื่อถือ
ดึงข้อมูลล่าสุด
แม้ LLMs จะเก่งหลายด้าน แต่ไม่สามารถให้ข้อมูลที่ถูกต้องเกี่ยวกับเรื่องเฉพาะหรือเหตุการณ์ล่าสุด รวมถึงความรู้เฉพาะของธุรกิจได้
แต่ RAG ช่วยให้โมเดลดึงข้อมูลแบบเรียลไทม์จากแหล่งใดก็ได้ เช่น เว็บไซต์ ตาราง หรือฐานข้อมูล
ตราบใดที่แหล่งข้อมูลได้รับการอัปเดต โมเดลก็จะตอบด้วยข้อมูลล่าสุดเสมอ
สื่อสารในบริบทซับซ้อน
อีกจุดอ่อนของ LLM แบบเดิมคือการสูญเสียข้อมูลบริบท
LLMs มักรักษาบริบทในบทสนทนายาวหรือซับซ้อนได้ไม่ดี ส่งผลให้คำตอบไม่สมบูรณ์หรือขาดตอน
แต่ RAG ช่วยให้โมเดลเข้าใจบริบทได้ดีขึ้นด้วยการดึงข้อมูลจากแหล่งที่เชื่อมโยงกันตามความหมาย
ด้วยข้อมูลเพิ่มเติมที่ตอบโจทย์ผู้ใช้โดยตรง เช่น แชทบอทขายสินค้าที่มีแคตตาล็อกสินค้า RAG ช่วยให้ AI สนทนาแบบเข้าใจบริบทได้
RAG ทำงานอย่างไร?
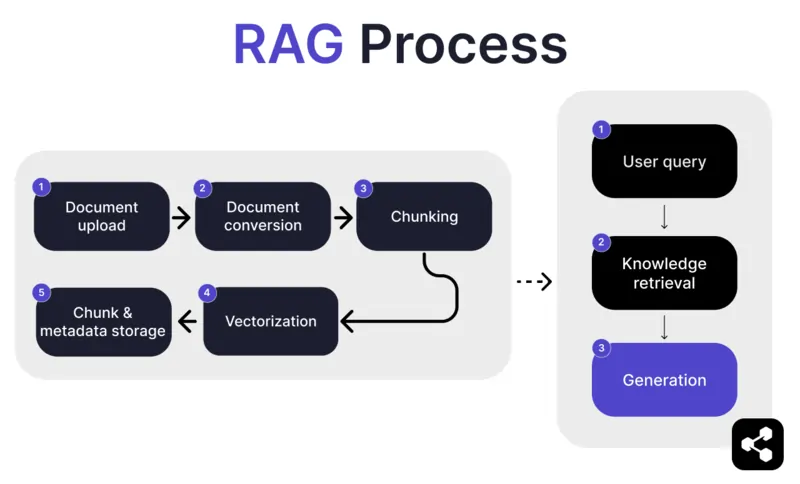
1. อัปโหลดเอกสาร
เริ่มต้น ผู้สร้างจะอัปโหลดเอกสารหรือไฟล์เข้าสู่คลังความรู้ของ AI ไฟล์อาจเป็นหน้าเว็บ PDF หรือรูปแบบอื่นที่รองรับ ซึ่งจะกลายเป็นส่วนหนึ่งของฐานความรู้ของ AI
2. แปลงเอกสาร
เนื่องจากมีไฟล์หลายประเภท เช่น PDF หน้าเว็บ ฯลฯ ระบบจะทำการแปลงไฟล์เหล่านี้ให้อยู่ในรูปแบบข้อความมาตรฐาน เพื่อให้ AI ประมวลผลและค้นหาข้อมูลที่เกี่ยวข้องได้ง่ายขึ้น
3. แบ่งส่วนและจัดเก็บ
เอกสารที่แปลงแล้วจะถูกแบ่งเป็นส่วนย่อย ๆ หรือชิ้นข้อมูล (chunk) ที่จัดการได้ง่าย จากนั้นจัดเก็บในฐานข้อมูล เพื่อให้ AI ค้นหาและดึงส่วนที่เกี่ยวข้องได้อย่างมีประสิทธิภาพเมื่อมีการถาม
4. การถามของผู้ใช้
เมื่อเตรียมฐานความรู้แล้ว ผู้ใช้สามารถถามคำถามกับ AI ได้ ระบบจะประมวลผลคำถามด้วย การประมวลผลภาษาธรรมชาติ (NLP) เพื่อเข้าใจสิ่งที่ผู้ใช้ต้องการ
5. ค้นหาความรู้
AI จะค้นหาชิ้นข้อมูลที่จัดเก็บไว้ โดยใช้ขั้นตอนการค้นหาเพื่อหาข้อมูลที่เกี่ยวข้องที่สุดจากเอกสารที่อัปโหลดมาตอบคำถามผู้ใช้
6. สร้างคำตอบ
สุดท้าย AI จะสร้างคำตอบโดยผสมข้อมูลที่ค้นพบกับความสามารถด้านภาษา เพื่อให้ได้คำตอบที่สมบูรณ์และตรงกับบริบทของคำถามและข้อมูลที่ค้นพบ
ฟีเจอร์ RAG ขั้นสูง
หากคุณไม่ใช่นักพัฒนา คุณอาจจะแปลกใจเมื่อรู้ว่า RAG แต่ละระบบไม่ได้เหมือนกันทั้งหมด
แต่ละระบบจะสร้างโมเดล RAG แตกต่างกัน ขึ้นอยู่กับความต้องการ กรณีใช้งาน หรือทักษะของผู้สร้าง
บางแพลตฟอร์ม AI มีฟีเจอร์ RAG ขั้นสูงที่ช่วยเพิ่มความแม่นยำและความน่าเชื่อถือของซอฟต์แวร์ AI ได้อีก
การแบ่งส่วนแบบ semantic กับ naive
Naive chunking คือการแบ่งเอกสารเป็นส่วนขนาดเท่ากัน เช่น ตัดข้อความเป็นช่วงละ 500 คำ โดยไม่สนใจความหมายหรือบริบท
ส่วน semantic chunking จะตัดเอกสารเป็นส่วนที่มีความหมายตามเนื้อหา
โดยจะคำนึงถึงจุดแบ่งธรรมชาติ เช่น ย่อหน้าหรือหัวข้อ เพื่อให้แต่ละส่วนมีข้อมูลที่สมบูรณ์ในตัวเอง
การอ้างอิงแหล่งข้อมูลเป็นข้อบังคับ
สำหรับอุตสาหกรรมที่ใช้ AI ในการสนทนาเสี่ยงสูง เช่น การเงินหรือสุขภาพ การอ้างอิงแหล่งข้อมูลช่วยสร้างความเชื่อมั่นให้ผู้ใช้
นักพัฒนาสามารถตั้งค่าให้ RAG อ้างอิงแหล่งข้อมูลทุกครั้งที่ให้ข้อมูล
เช่น หากพนักงานถามแชทบอท AI เกี่ยวกับสิทธิประโยชน์ด้านสุขภาพ แชทบอทสามารถตอบพร้อมแนบลิงก์ไปยังเอกสารสิทธิประโยชน์ที่เกี่ยวข้อง
สร้าง RAG AI Agent แบบกำหนดเอง
ผสานศักยภาพของ LLMs รุ่นล่าสุดกับความรู้เฉพาะขององค์กรคุณ
Botpress คือแพลตฟอร์มแชทบอท AI ที่ยืดหยุ่นและขยายความสามารถได้ไม่จำกัด
ผู้ใช้สามารถสร้าง AI agent หรือแชทบอทได้ทุกรูปแบบสำหรับทุกกรณีใช้งาน – และยังมีระบบ RAG ที่ล้ำหน้าที่สุดในตลาด
เชื่อมต่อแชทบอทของคุณกับแพลตฟอร์มหรือช่องทางใดก็ได้ หรือเลือกใช้ไลบรารีการเชื่อมต่อสำเร็จรูปของเรา เริ่มต้นได้ง่าย ๆ ด้วยวิดีโอสอนจากช่อง YouTube ของ Botpress หรือคอร์สฟรีจาก Botpress Academy
คำถามที่พบบ่อย
1. RAG แตกต่างจากการ fine-tune LLM อย่างไร?
RAG (Retrieval-Augmented Generation) แตกต่างจากการปรับแต่งโมเดล (fine-tuning) ตรงที่ RAG จะคงโมเดล LLM ดั้งเดิมไว้โดยไม่เปลี่ยนแปลง และนำความรู้จากภายนอกมาใช้ขณะทำงานด้วยการค้นหาเอกสารที่เกี่ยวข้อง ในขณะที่การปรับแต่งโมเดลจะเปลี่ยนน้ำหนักของโมเดลโดยใช้ข้อมูลฝึก ซึ่งต้องใช้ทรัพยากรมากกว่าและต้องทำซ้ำทุกครั้งที่มีการอัปเดตข้อมูล
2. แหล่งข้อมูลประเภทใดที่ไม่เหมาะสำหรับ RAG?
แหล่งข้อมูลที่ไม่เหมาะกับ RAG ได้แก่ ไฟล์ที่ไม่ใช่ข้อความ เช่น เอกสารสแกน, PDF ที่เป็นภาพ, ไฟล์เสียงที่ไม่มีการถอดคำพูด และเนื้อหาที่ล้าสมัยหรือขัดแย้งกัน ข้อมูลเหล่านี้จะทำให้ความแม่นยำของบริบทที่ค้นหาได้น้อยลง
3. RAG แตกต่างจากเทคนิคการเรียนรู้แบบ in-context เช่น prompt engineering อย่างไร?
RAG แตกต่างจาก prompt engineering ตรงที่ RAG จะค้นหาข้อมูลที่เกี่ยวข้องจากฐานความรู้ขนาดใหญ่ที่จัดทำดัชนีไว้ในขณะรับคำถาม แทนที่จะใช้ตัวอย่างที่ฝังไว้ใน prompt แบบคงที่ด้วยตนเอง วิธีนี้ช่วยให้ RAG ขยายขนาดได้ง่ายกว่าและอัปเดตความรู้ได้ตลอดโดยไม่ต้องฝึกโมเดลใหม่
4. ฉันสามารถใช้ RAG กับ LLM ของบุคคลที่สาม เช่น OpenAI, Anthropic หรือ Mistral ได้หรือไม่?
ได้ คุณสามารถใช้ RAG กับ LLM จาก OpenAI, Anthropic, Mistral หรือรายอื่น ๆ ได้ โดยจัดการกระบวนการค้นหาข้อมูลแยกต่างหาก แล้วส่งบริบทที่ค้นหาได้ไปยัง LLM ผ่าน API RAG สามารถใช้กับโมเดลใดก็ได้ ตราบใดที่ LLM รองรับการรับข้อมูลบริบทผ่าน prompt
5. การดูแลรักษา AI agent ที่ใช้ RAG ต้องทำอะไรบ้าง?
การดูแลรักษา AI agent ที่ใช้ RAG ประกอบด้วย การอัปเดตฐานความรู้ด้วยเอกสารใหม่หรือแก้ไขข้อมูล, การจัดทำดัชนีเนื้อหาใหม่เป็นระยะ, ประเมินคุณภาพการค้นหา, ปรับขนาดชิ้นข้อมูลและวิธีฝังข้อมูล และตรวจสอบคำตอบของ agent เพื่อป้องกันข้อผิดพลาดหรือการสร้างข้อมูลเท็จ



