.webp)



- RAG menggabungkan pengambilan data daripada sumber yang dipercayai dengan penjanaan LLM, memastikan respons AI adalah tepat, relevan, dan berpaksikan pengetahuan sebenar perniagaan.
- Berbeza dengan LLM semata-mata, RAG mengurangkan halusinasi dengan memautkan jawapan kepada dokumen, pangkalan data, atau kandungan yang diluluskan.
- RAG menyokong maklumat terkini, membolehkan sistem AI menjawab soalan tentang perubahan terbaru atau topik khusus yang tidak terdapat dalam data latihan statik LLM.
- Menyelenggara sistem RAG melibatkan memastikan data sentiasa dikemas kini, memantau output, dan menambah baik kaedah pengambilan untuk prestasi terbaik dari semasa ke semasa.
RAG membolehkan organisasi menggunakan AI – dengan risiko yang lebih rendah berbanding penggunaan LLM tradisional.
Penjanaan berasaskan pengambilan semakin popular apabila lebih banyak perniagaan memperkenalkan penyelesaian AI. Chatbot perusahaan awal pernah mengalami kesilapan dan halusinasi yang berisiko.
RAG membolehkan syarikat memanfaatkan kekuatan LLM sambil memastikan output generatif berpandukan pengetahuan perniagaan mereka sendiri.
Apakah itu penjanaan berasaskan pengambilan?
Retrieval-augmented generation (RAG) dalam AI ialah teknik yang menggabungkan a) pencarian maklumat luaran yang relevan dan b) respons yang dijana AI, untuk meningkatkan ketepatan dan kaitan jawapan.
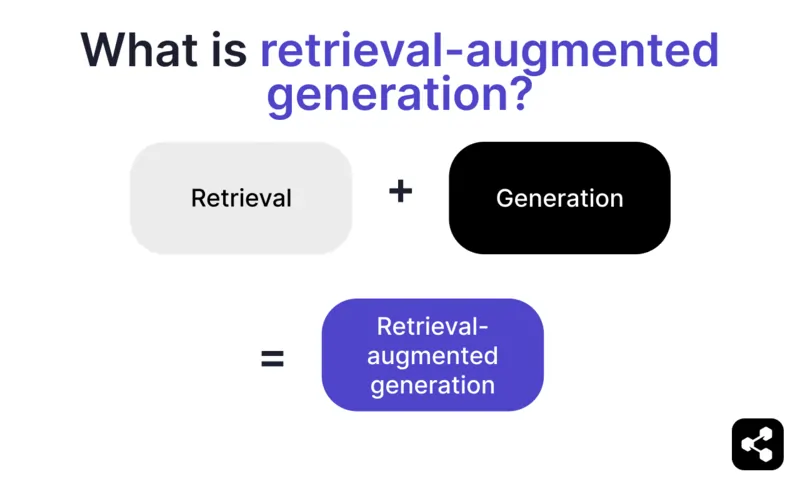
Daripada hanya bergantung pada penjanaan model bahasa besar (LLM), respons daripada model RAG dipandu oleh pangkalan pengetahuan yang ditetapkan oleh pembina ejen AI – seperti laman web syarikat atau dokumen polisi HR.
RAG beroperasi dalam dua langkah utama:
1. Pengambilan
Model mencari dan mengambil data yang relevan daripada sumber berstruktur atau tidak berstruktur (contohnya pangkalan data, PDF, fail HTML, atau dokumen lain). Sumber ini boleh jadi berstruktur (seperti jadual) atau tidak berstruktur (seperti laman web yang diluluskan).
2. Penjanaan
Selepas pengambilan, maklumat dimasukkan ke dalam LLM. LLM menggunakan maklumat ini untuk menjana respons dalam bahasa semula jadi, menggabungkan data yang diluluskan dengan keupayaan linguistiknya untuk menghasilkan jawapan yang tepat, seperti manusia, dan selari dengan jenama.
Contoh Penggunaan RAG
Apa tujuan RAG? Ia membolehkan organisasi memberikan output yang relevan, bermaklumat, dan tepat.
RAG ialah cara langsung untuk mengurangkan risiko output LLM yang tidak tepat atau halusinasi.
Contoh 1: Firma Guaman
Sebuah firma guaman mungkin menggunakan RAG dalam sistem AI untuk:
- Mencari undang-undang kes, preseden, dan keputusan undang-undang yang relevan daripada pangkalan data dokumen semasa penyelidikan.
- Menjana ringkasan kes dengan mengekstrak fakta utama daripada fail kes dan keputusan lalu.
- Secara automatik memberikan kemas kini peraturan yang berkaitan kepada pekerja.
Contoh 2: Agensi Hartanah
Sebuah agensi hartanah mungkin menggunakan RAG dalam sistem AI untuk:
- Meringkaskan data daripada sejarah transaksi hartanah dan statistik jenayah kawasan.
- Menjawab soalan undang-undang tentang transaksi hartanah dengan merujuk undang-undang dan peraturan hartanah tempatan.
- Memudahkan proses penilaian dengan mengambil data daripada laporan keadaan hartanah, trend pasaran, dan jualan terdahulu.
Contoh 3: Kedai E-Dagang
Sebuah kedai e-dagang mungkin menggunakan RAG dalam sistem AI untuk:
- Mengumpul maklumat produk, spesifikasi, dan ulasan daripada pangkalan data syarikat untuk memberikan cadangan produk yang diperibadikan.
- Mengambil sejarah pesanan untuk menghasilkan pengalaman membeli-belah yang disesuaikan mengikut keutamaan pengguna.
- Menjana kempen e-mel yang disasarkan dengan mengambil data segmentasi pelanggan dan menggabungkannya dengan corak pembelian terkini.
Kelebihan RAG
Seperti yang diketahui sesiapa yang pernah menggunakan ChatGPT atau Claude, LLM mempunyai perlindungan minimum terbina dalam.
Tanpa pemantauan yang betul, ia boleh menghasilkan maklumat yang tidak tepat atau berbahaya, menjadikannya tidak boleh dipercayai untuk penggunaan dunia sebenar.
RAG menawarkan penyelesaian dengan memautkan respons kepada sumber data yang dipercayai dan terkini, sekali gus mengurangkan risiko ini dengan ketara.
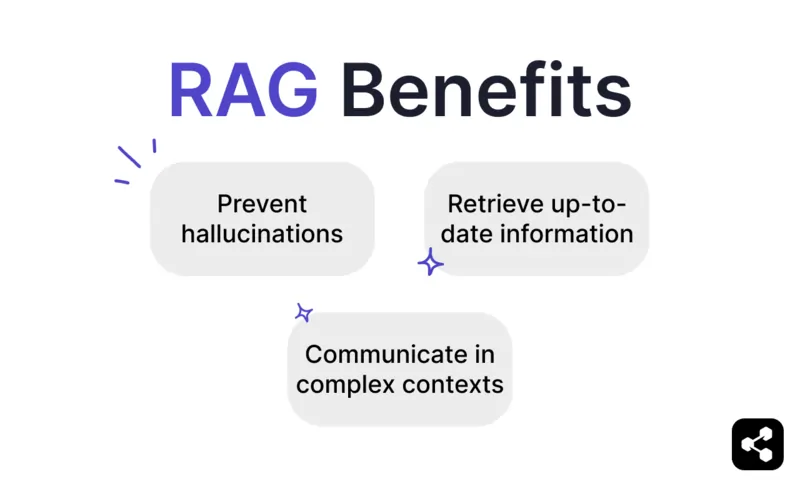
Mencegah halusinasi dan ketidaktepatan
Model bahasa tradisional sering menghasilkan halusinasi — respons yang kedengaran meyakinkan tetapi sebenarnya salah atau tidak relevan.
RAG mengurangkan halusinasi dengan memautkan respons kepada sumber data yang boleh dipercayai dan sangat relevan.
Langkah pengambilan memastikan model merujuk maklumat yang tepat dan terkini, yang secara signifikan mengurangkan kemungkinan halusinasi dan meningkatkan kebolehpercayaan.
Mengambil maklumat terkini
Walaupun LLM adalah alat yang berkuasa untuk banyak tugas, ia tidak dapat memberikan maklumat tepat tentang perkara yang jarang atau baru – termasuk pengetahuan perniagaan khusus.
Tetapi RAG membolehkan model mendapatkan maklumat masa nyata daripada mana-mana sumber, termasuk laman web, jadual, atau pangkalan data.
Ini memastikan bahawa, selagi sumber kebenaran dikemas kini, model akan memberikan maklumat yang terkini.
Berkomunikasi dalam konteks yang kompleks
Satu lagi kelemahan penggunaan LLM tradisional ialah kehilangan maklumat konteks.
LLM sukar mengekalkan konteks dalam perbualan yang panjang atau rumit. Ini sering menyebabkan respons yang tidak lengkap atau terputus-putus.
Tetapi model RAG membolehkan kesedaran konteks dengan mengambil maklumat terus daripada sumber data yang berkaitan secara semantik.
Dengan maklumat tambahan yang disesuaikan untuk keperluan pengguna – seperti chatbot jualan yang dilengkapi katalog produk – RAG membolehkan ejen AI terlibat dalam perbualan yang kontekstual.
Bagaimana RAG berfungsi?
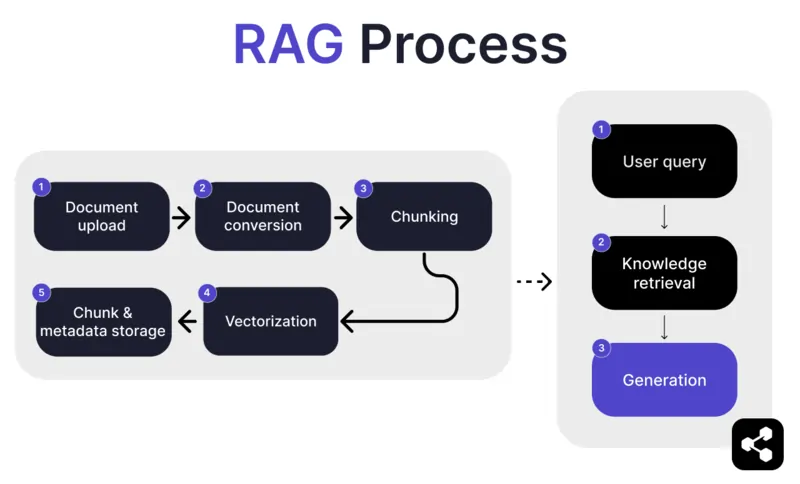
1. Muat Naik Dokumen
Mula-mula, pembina memuat naik dokumen atau fail ke perpustakaan ejen AI mereka. Fail ini boleh berupa laman web, PDF, atau format lain yang disokong, yang akan menjadi sebahagian daripada pangkalan pengetahuan AI.
2. Penukaran Dokumen
Oleh kerana terdapat pelbagai jenis fail – PDF, laman web, dan sebagainya – sistem akan menukar fail-fail ini kepada format teks standard, memudahkan AI memproses dan mengambil maklumat yang relevan.
3. Pemecahan dan Penyimpanan
Dokumen yang telah ditukar kemudian dipecahkan kepada bahagian-bahagian kecil yang mudah diurus, atau 'chunk'. Bahagian-bahagian ini disimpan dalam pangkalan data, membolehkan ejen AI mencari dan mengambil bahagian yang relevan dengan lebih cekap semasa pertanyaan.
4. Pertanyaan Pengguna
Selepas pangkalan pengetahuan disediakan, pengguna boleh bertanya soalan kepada ejen AI. Pertanyaan ini diproses menggunakan pemprosesan bahasa semula jadi (NLP) untuk memahami apa yang diminta oleh pengguna.
5. Pengambilan Pengetahuan
Ejen AI mencari dalam bahagian-bahagian yang disimpan, menggunakan algoritma pengambilan untuk mendapatkan maklumat paling relevan daripada dokumen yang dimuat naik bagi menjawab soalan pengguna.
6. Penjanaan
Akhir sekali, ejen AI akan menjana jawapan dengan menggabungkan maklumat yang diambil dengan keupayaan model bahasanya, menghasilkan jawapan yang koheren dan tepat mengikut konteks berdasarkan pertanyaan dan data yang diambil.
Ciri Lanjutan RAG
Jika anda bukan pembangun, anda mungkin terkejut mengetahui bahawa tidak semua RAG adalah sama.
Sistem yang berbeza akan membina model RAG yang berbeza, bergantung pada keperluan, kes penggunaan, atau tahap kemahiran mereka.
Sesetengah platform AI menawarkan ciri RAG lanjutan yang boleh meningkatkan lagi ketepatan dan kebolehpercayaan perisian AI anda.
Pemecahan semantik vs pemecahan naif
Pemecahan naif ialah apabila dokumen dibahagikan kepada bahagian bersaiz tetap, seperti memotong teks kepada bahagian 500 perkataan, tanpa mengira makna atau konteks.
Pemecahan semantik pula membahagikan dokumen kepada bahagian yang bermakna berdasarkan kandungan.
Ia mengambil kira pemisah semula jadi, seperti perenggan atau topik, memastikan setiap bahagian mengandungi maklumat yang koheren.
Sitasi wajib
Untuk industri yang mengautomasikan perbualan berisiko tinggi dengan AI – seperti kewangan atau penjagaan kesihatan – sitasi boleh membantu meningkatkan kepercayaan pengguna apabila menerima maklumat.
Pembangun boleh mengarahkan model RAG mereka untuk menyediakan sitasi bagi setiap maklumat yang dihantar.
Sebagai contoh, jika pekerja bertanya kepada chatbot AI tentang faedah kesihatan, chatbot boleh membalas dan memberikan pautan ke dokumen faedah pekerja yang berkaitan.
Bina Ejen AI RAG Tersuai
Gabungkan kekuatan LLM terkini dengan pengetahuan unik perusahaan anda.
Botpress ialah platform chatbot AI yang fleksibel dan boleh diperluas tanpa had.
Ia membolehkan pengguna membina apa-apa jenis ejen AI atau chatbot untuk sebarang kegunaan – dan menawarkan sistem RAG paling canggih di pasaran.
Integrasikan chatbot anda ke mana-mana platform atau saluran, atau pilih daripada pustaka integrasi sedia ada kami. Mulakan dengan tutorial di saluran YouTube Botpress atau kursus percuma dari Botpress Academy.
Mula membina hari ini. Ia percuma.
Soalan Lazim
1. Bagaimana RAG berbeza daripada penalaan khusus LLM?
RAG (Retrieval-Augmented Generation) berbeza daripada penalaan semula (fine-tuning) kerana RAG mengekalkan LLM asal tanpa perubahan dan menyuntik pengetahuan luaran semasa operasi dengan mendapatkan dokumen yang berkaitan. Penalaan semula pula mengubah berat model menggunakan data latihan, memerlukan lebih banyak kuasa pengkomputeran dan perlu diulang setiap kali ada kemas kini.
2. Apakah jenis sumber data yang tidak sesuai untuk RAG?
Sumber data yang tidak sesuai untuk RAG termasuk format bukan teks seperti dokumen yang diimbas, PDF berasaskan imej, fail audio tanpa transkrip, serta kandungan yang lapuk atau bercanggah. Jenis data ini boleh mengurangkan ketepatan konteks yang diperoleh.
3. Bagaimanakah RAG berbanding dengan teknik pembelajaran dalam konteks seperti kejuruteraan prompt?
RAG berbeza daripada kejuruteraan prompt kerana ia mendapatkan kandungan berkaitan daripada pangkalan pengetahuan yang besar dan terindeks semasa pertanyaan, bukannya bergantung pada contoh statik yang dimasukkan secara manual dalam prompt. Ini membolehkan RAG berskala lebih baik dan mengekalkan pengetahuan yang terkini tanpa perlu melatih semula model.
4. Bolehkah saya menggunakan RAG dengan LLM pihak ketiga seperti OpenAI, Anthropic, atau Mistral?
Ya, anda boleh menggunakan RAG dengan LLM daripada OpenAI, Anthropic, Mistral, atau lain-lain dengan menguruskan proses pengambilan maklumat secara berasingan dan menghantar konteks yang diperoleh kepada LLM melalui API mereka. RAG tidak bergantung pada jenis model selagi LLM tersebut menyokong penerimaan input konteks melalui prompt.
5. Apakah yang terlibat dalam penyelenggaraan berterusan untuk ejen AI yang menggunakan RAG?
Penyelenggaraan berterusan untuk ejen AI berasaskan RAG termasuk mengemas kini pangkalan pengetahuan dengan dokumen baru atau yang telah diperbetulkan, melakukan pengindeksan semula secara berkala, menilai kualiti pengambilan maklumat, melaras saiz pecahan dan kaedah embedding, serta memantau respons ejen untuk isu seperti penyimpangan atau halusinasi.



