.webp)



- RAG combina il recupero da dati affidabili con la generazione LLM, garantendo che le risposte AI siano accurate, pertinenti e basate su conoscenze aziendali reali.
- A differenza dei soli LLM, RAG riduce le allucinazioni ancorando le risposte a documenti, database o contenuti approvati.
- Il metodo RAG supporta informazioni aggiornate, consentendo ai sistemi AI di rispondere a domande su cambiamenti recenti o argomenti di nicchia oltre i dati statici di addestramento di un LLM.
- Mantenere un sistema RAG richiede di aggiornare i dati, monitorare i risultati e perfezionare i metodi di recupero per garantire prestazioni ottimali nel tempo.
RAG permette alle organizzazioni di sfruttare l’AI – con meno rischi rispetto all’uso tradizionale degli LLM.
La retrieval-augmented generation sta diventando sempre più diffusa man mano che le aziende adottano soluzioni AI. I primi chatbot aziendali hanno mostrato errori rischiosi e allucinazioni.
RAG consente alle aziende di sfruttare la potenza degli LLM mantenendo le risposte generative ancorate alle conoscenze specifiche dell’azienda.
Cos’è la generazione aumentata dal recupero?
La generazione aumentata dal recupero (RAG) nell’AI è una tecnica che combina a) il recupero di informazioni esterne rilevanti e b) risposte generate dall’AI, migliorando accuratezza e pertinenza.
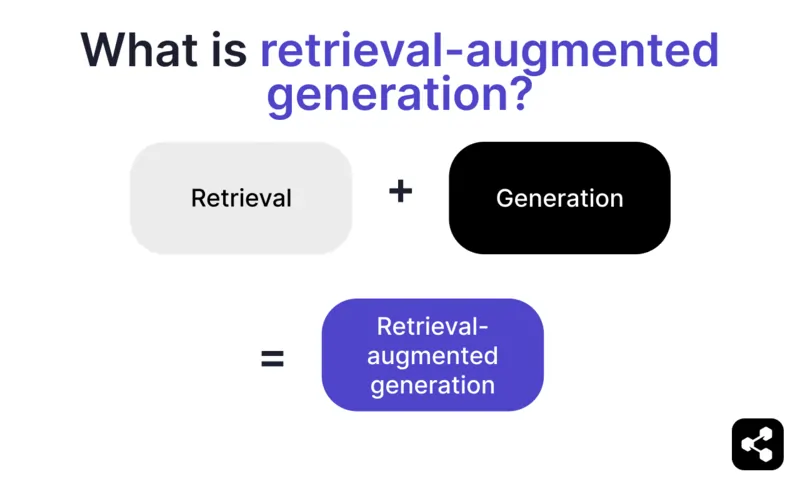
Invece di affidarsi solo alla generazione dei grandi modelli linguistici (LLM), le risposte dei modelli RAG sono basate su basi di conoscenza definite dal creatore dell’agente AI – come la pagina web di un’azienda o un documento di policy HR.
RAG opera in due fasi principali:
1. Recupero
Il modello cerca e recupera dati rilevanti da fonti strutturate o non strutturate (ad esempio database, PDF, file HTML o altri documenti). Queste fonti possono essere strutturate (ad esempio tabelle) o non strutturate (ad esempio siti web approvati).
2. Generazione
Dopo il recupero, le informazioni vengono inviate all’LLM. L’LLM utilizza queste informazioni per generare una risposta in linguaggio naturale, combinando i dati approvati con le sue capacità linguistiche per creare risposte accurate, naturali e in linea con il brand.
Esempi di casi d'uso RAG
A cosa serve il RAG? Permette alle organizzazioni di fornire risposte pertinenti, informative e accurate.
RAG è un modo diretto per ridurre il rischio di output LLM inaccurati o allucinazioni.
Esempio 1: Studio legale
Uno studio legale potrebbe utilizzare un RAG in un sistema AI per:
- Cerca giurisprudenza, precedenti e sentenze rilevanti nei database di documenti durante la ricerca.
- Genera riepiloghi dei casi estraendo i fatti chiave dai fascicoli e dalle sentenze precedenti.
- Fornisci automaticamente ai dipendenti aggiornamenti normativi rilevanti.
Esempio 2: Agenzia immobiliare
Un’agenzia immobiliare potrebbe utilizzare un RAG in un sistema AI per:
- Riepiloga i dati dalle cronologie delle transazioni immobiliari e dalle statistiche sui crimini di quartiere.
- Rispondi a domande legali sulle transazioni immobiliari citando le leggi e i regolamenti locali.
- Snellisci i processi di valutazione recuperando dati da report sulle condizioni degli immobili, tendenze di mercato e vendite storiche.
Esempio 3: Negozio e-commerce
Un e-commerce potrebbe usare un RAG in un sistema IA per:
- Raccogli informazioni sui prodotti, specifiche e recensioni dal database aziendale per informare raccomandazioni di prodotto personalizzate.
- Recupera la cronologia degli ordini per creare esperienze di acquisto personalizzate in base alle preferenze dell’utente.
- Genera campagne email mirate recuperando dati di segmentazione dei clienti e combinandoli con i modelli di acquisto recenti.
Vantaggi del RAG
Come sa chiunque abbia interrogato ChatGPT o Claude, gli LLM hanno poche protezioni integrate.
Senza un’adeguata supervisione, possono generare informazioni errate o persino dannose, rendendoli inaffidabili per l’uso reale.
RAG offre una soluzione ancorando le risposte a fonti di dati affidabili e aggiornate, riducendo notevolmente questi rischi.
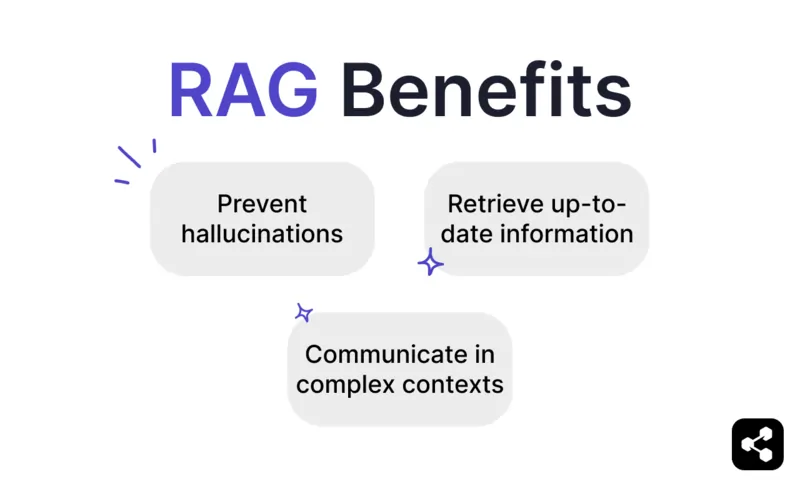
Previeni allucinazioni e imprecisioni
I modelli linguistici tradizionali spesso generano allucinazioni: risposte che sembrano convincenti ma sono errate o irrilevanti.
RAG riduce le allucinazioni basando le risposte su fonti di dati affidabili e altamente pertinenti.
La fase di recupero garantisce che il modello faccia riferimento a informazioni accurate e aggiornate, riducendo notevolmente il rischio di allucinazioni e aumentando l’affidabilità.
Recupera informazioni aggiornate
Sebbene gli LLM siano uno strumento potente per molti compiti, non sono in grado di fornire informazioni accurate su dati rari o recenti – inclusa la conoscenza aziendale su misura.
Ma RAG permette al modello di recuperare informazioni in tempo reale da qualsiasi fonte, inclusi siti web, tabelle o database.
Questo garantisce che, finché la fonte ufficiale viene aggiornata, il modello risponderà con informazioni sempre aggiornate.
Comunicare in contesti complessi
Un’altra debolezza dell’uso tradizionale degli LLM è la perdita di informazioni contestuali.
Gli LLM fanno fatica a mantenere il contesto in conversazioni lunghe o complesse. Questo spesso porta a risposte incomplete o frammentate.
Ma un modello RAG consente la consapevolezza del contesto attingendo direttamente da fonti di dati semanticamente collegate.
Con informazioni aggiuntive mirate alle esigenze degli utenti – come un chatbot di vendita dotato di catalogo prodotti – RAG consente agli agenti AI di partecipare a conversazioni contestuali.
Come funziona il RAG?
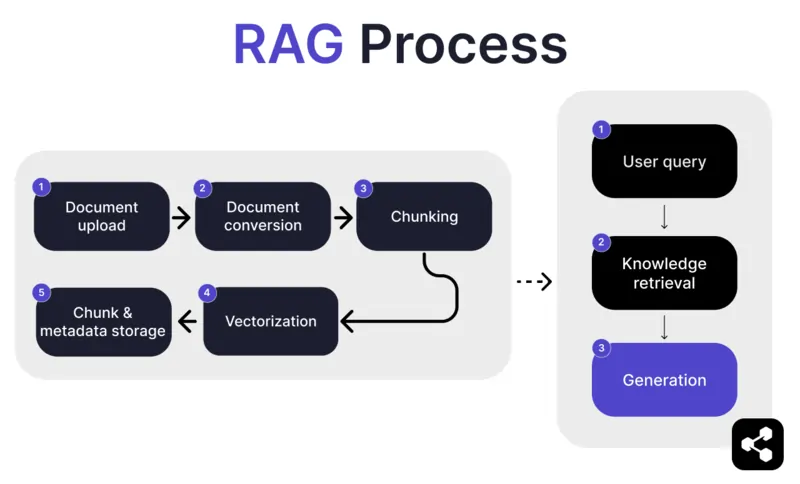
1. Caricamento documenti
Per prima cosa, il builder carica un documento o file nella libreria dell’agente IA. Il file può essere una pagina web, un PDF o un altro formato supportato, che andrà a costituire parte della knowledge base dell’IA.
2. Conversione di documenti
Poiché esistono molti tipi di file – PDF, pagine web, ecc. – il sistema converte questi file in un formato di testo standardizzato, facilitando l’elaborazione da parte dell’AI e il recupero delle informazioni rilevanti.
3. Suddivisione e archiviazione
Il documento convertito viene poi suddiviso in parti più piccole e gestibili, o chunk. Questi chunk vengono archiviati in un database, consentendo all’agente IA di cercare e recuperare rapidamente le sezioni rilevanti durante una richiesta.
4. Richiesta utente
Dopo aver configurato le knowledge base, un utente può porre una domanda all’agente IA. La richiesta viene elaborata tramite natural language processing (NLP) per capire cosa sta chiedendo l’utente.
5. Recupero della conoscenza
L’agente AI cerca tra i frammenti archiviati, utilizzando algoritmi di recupero per trovare le informazioni più rilevanti nei documenti caricati e rispondere così alla domanda dell’utente.
6. Generazione
Infine, l’agente AI genererà una risposta combinando le informazioni recuperate con le sue capacità di linguaggio, creando una risposta coerente e contestualmente accurata in base alla domanda e ai dati recuperati.
Funzionalità RAG avanzate
Se non sei uno sviluppatore, potresti essere sorpreso di scoprire che non tutti i sistemi RAG sono uguali.
Ogni sistema costruirà modelli RAG diversi, in base alle proprie esigenze, casi d’uso o competenze.
Alcune piattaforme AI offrono funzionalità RAG avanzate che possono migliorare ulteriormente la precisione e l’affidabilità del tuo software AI.
Chunking semantico vs chunking ingenuo
Il chunking ingenuo consiste nel dividere un documento in parti di dimensione fissa, ad esempio sezioni da 500 parole, indipendentemente dal significato o dal contesto.
Il chunking semantico, invece, suddivide il documento in sezioni significative basate sul contenuto.
Tiene conto delle pause naturali, come paragrafi o argomenti, assicurando che ogni blocco contenga un’informazione coerente.
Citazioni obbligatorie
Per i settori che automatizzano conversazioni ad alto rischio con l’AI – come finanza o sanità – le citazioni possono aiutare a instaurare fiducia negli utenti quando ricevono informazioni.
Gli sviluppatori possono istruire i loro modelli RAG a fornire citazioni per qualsiasi informazione inviata.
Ad esempio, se un dipendente chiede a un chatbot AI informazioni sui benefit sanitari, il chatbot può rispondere e fornire un link al documento relativo ai benefit dei dipendenti.
Crea un agente IA RAG personalizzato
Combina la potenza degli ultimi LLM con la conoscenza unica della tua azienda.
Botpress è una piattaforma chatbot AI flessibile e infinitamente estendibile.
Permette agli utenti di creare qualsiasi tipo di agente AI o chatbot per qualsiasi esigenza – e offre il sistema RAG più avanzato sul mercato.
Integra il tuo chatbot su qualsiasi piattaforma o canale, oppure scegli dalla nostra libreria di integrazioni predefinite. Inizia con i tutorial sul canale YouTube di Botpress o con i corsi gratuiti della Botpress Academy.
Inizia a costruire oggi. È gratis.
Domande frequenti
1. In cosa RAG è diverso dal fine-tuning di un LLM?
RAG (Retrieval-Augmented Generation) è diverso dal fine-tuning perché RAG mantiene invariato l’LLM originale e inserisce conoscenza esterna in tempo reale recuperando documenti rilevanti. Il fine-tuning modifica i pesi del modello usando dati di addestramento, richiede più risorse e va ripetuto a ogni aggiornamento.
2. Quali tipi di fonti dati non sono adatti per il RAG?
Fonti di dati non adatte al RAG includono formati non testuali come documenti scannerizzati, PDF basati su immagini, file audio senza trascrizioni e contenuti obsoleti o contraddittori. Questi tipi di dati riducono l’accuratezza del contesto recuperato.
3. Come si confronta il RAG con tecniche di apprendimento in contesto come il prompt engineering?
RAG si differenzia dal prompt engineering perché recupera contenuti rilevanti da una vasta knowledge base indicizzata al momento della richiesta, invece di affidarsi a esempi statici inseriti manualmente nel prompt. Questo consente a RAG di essere più scalabile e mantenere conoscenze aggiornate senza necessità di riaddestramento.
4. Posso utilizzare il RAG con LLM di terze parti come OpenAI, Anthropic o Mistral?
Sì, puoi usare RAG con LLM di OpenAI, Anthropic, Mistral o altri gestendo la pipeline di recupero in modo indipendente e inviando il contesto recuperato all’LLM tramite la sua API. RAG è indipendente dal modello, purché l’LLM supporti l’invio di input contestuali tramite prompt.
5. Come si gestisce la manutenzione continua di un agente AI abilitato al RAG?
La manutenzione continua di un agente AI abilitato RAG include l’aggiornamento della knowledge base con nuovi o corretti documenti, la reindicizzazione periodica dei contenuti, la valutazione della qualità del recupero, la regolazione della dimensione dei blocchi e dei metodi di embedding, e il monitoraggio delle risposte dell’agente per individuare problemi di deriva o allucinazione.



