.webp)



- RAG combina la recuperación de datos confiables con la generación de LLM, asegurando que las respuestas de la IA sean precisas, relevantes y fundamentadas en el conocimiento real de la empresa.
- A diferencia de los LLM puros, RAG reduce las alucinaciones al fundamentar las respuestas en documentos, bases de datos o contenidos aprobados específicos.
- RAG permite acceder a información actualizada, lo que posibilita que los sistemas de IA respondan preguntas sobre cambios recientes o temas especializados que van más allá de los datos estáticos de entrenamiento de un LLM.
- Mantener un sistema RAG implica actualizar los datos, monitorear los resultados y mejorar los métodos de recuperación para lograr el mejor desempeño a lo largo del tiempo.
RAG permite a las organizaciones aprovechar la IA con menos riesgo que el uso tradicional de LLM.
La generación aumentada por recuperación está ganando popularidad a medida que más empresas implementan soluciones de IA. Los primeros chatbots empresariales cometieron errores riesgosos y generaron alucinaciones.
RAG permite a las empresas aprovechar el poder de los LLM mientras fundamentan la generación de respuestas en el conocimiento específico de su negocio.
¿Qué es la generación aumentada por recuperación?
La generación aumentada por recuperación (RAG) en IA es una técnica que combina a) la recuperación de información externa relevante y b) respuestas generadas por IA, mejorando la precisión y relevancia.
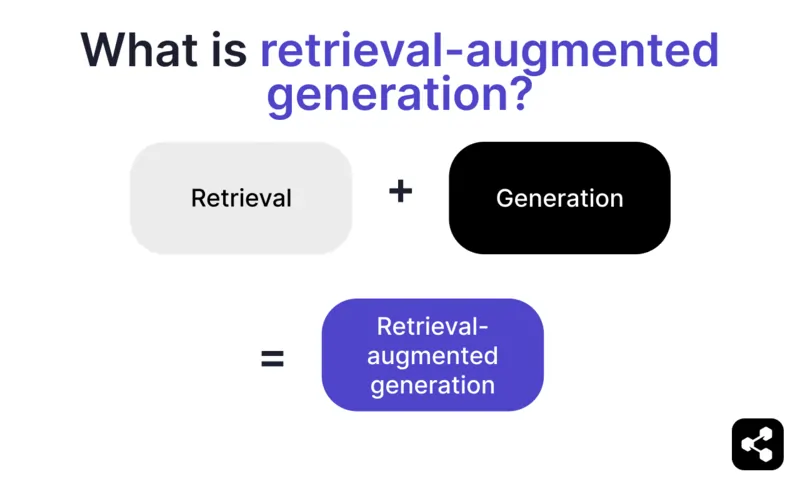
En lugar de depender únicamente de la generación de los modelos de lenguaje grande (LLM), las respuestas de los modelos RAG se basan en bases de conocimientos definidas por el creador del agente de IA, como la página web de una empresa o un documento de políticas de RRHH.
RAG funciona en dos pasos principales:
1. Recuperación
El modelo busca y recupera datos relevantes de fuentes estructuradas o no estructuradas (por ejemplo, bases de datos, archivos PDF, archivos HTML u otros documentos). Estas fuentes pueden ser estructuradas (como tablas) o no estructuradas (como sitios web aprobados).
2. Generación
Después de la recuperación, la información se introduce en el LLM. El LLM utiliza esa información para generar una respuesta en lenguaje natural, combinando los datos aprobados con su capacidad lingüística para crear respuestas precisas, naturales y alineadas con la marca.
Ejemplos de casos de uso de RAG
¿Para qué sirve RAG? Permite a las organizaciones ofrecer respuestas relevantes, informativas y precisas.
RAG es una forma directa de reducir el riesgo de respuestas inexactas o alucinaciones de los LLM.
Ejemplo 1: Despacho de abogados
Un despacho de abogados podría usar RAG en un sistema de IA para:
- Buscar jurisprudencia, precedentes y sentencias relevantes en bases de datos de documentos durante la investigación.
- Generar resúmenes de casos extrayendo los hechos clave de expedientes y sentencias anteriores.
- Proporcionar automáticamente a los empleados actualizaciones regulatorias relevantes.
Ejemplo 2: Agencia inmobiliaria
Una agencia inmobiliaria podría usar RAG en un sistema de IA para:
- Resumir datos de historiales de transacciones de propiedades y estadísticas de criminalidad en barrios.
- Responder preguntas legales sobre transacciones inmobiliarias citando leyes y normativas locales.
- Optimizar procesos de tasación extrayendo datos de informes de condición de propiedades, tendencias del mercado y ventas históricas.
Ejemplo 3: Tienda de comercio electrónico
Una tienda de comercio electrónico podría usar RAG en un sistema de IA para:
- Recopilar información de productos, especificaciones y reseñas de la base de datos de la empresa para ofrecer recomendaciones personalizadas.
- Recuperar el historial de pedidos para generar experiencias de compra adaptadas a las preferencias del usuario.
- Crear campañas de correo electrónico segmentadas recuperando datos de segmentación de clientes y combinándolos con patrones de compra recientes.
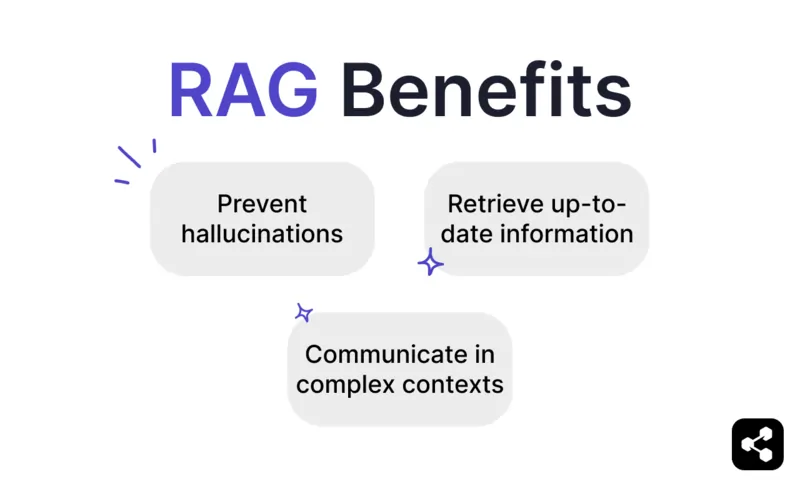
Ventajas de RAG
Como cualquiera que haya consultado ChatGPT o Claude sabe, los LLMs tienen pocas salvaguardas integradas.
Sin la supervisión adecuada, pueden generar información inexacta o incluso dañina, lo que los hace poco confiables para implementaciones reales.
RAG ofrece una solución al fundamentar las respuestas en fuentes de datos confiables y actualizadas, reduciendo significativamente estos riesgos.
Previene alucinaciones e imprecisiones
Los modelos de lenguaje tradicionales suelen generar alucinaciones: respuestas que suenan convincentes pero son incorrectas o irrelevantes.
RAG reduce las alucinaciones al fundamentar las respuestas en fuentes de datos confiables y altamente relevantes.
El paso de recuperación garantiza que el modelo consulte información precisa y actualizada, lo que disminuye considerablemente la posibilidad de alucinaciones y aumenta la confiabilidad.
Recupera información actualizada
Aunque los LLMs son una herramienta poderosa para muchas tareas, no pueden proporcionar información precisa sobre datos recientes o poco comunes, incluyendo conocimiento empresarial específico.
Pero RAG permite que el modelo obtenga información en tiempo real de cualquier fuente, como sitios web, tablas o bases de datos.
Esto asegura que, siempre que la fuente de verdad esté actualizada, el modelo responderá con información vigente.
Comunica en contextos complejos
Otra debilidad del uso tradicional de LLMs es la pérdida de información contextual.
Los LLMs tienen dificultades para mantener el contexto en conversaciones largas o complejas, lo que suele resultar en respuestas incompletas o fragmentadas.
Pero un modelo RAG permite mantener el contexto al extraer información directamente de fuentes de datos semánticamente relacionadas.
Con información adicional dirigida específicamente a las necesidades del usuario – como un chatbot de ventas con un catálogo de productos – RAG permite que los agentes de IA participen en conversaciones contextuales.
¿Cómo funciona RAG?
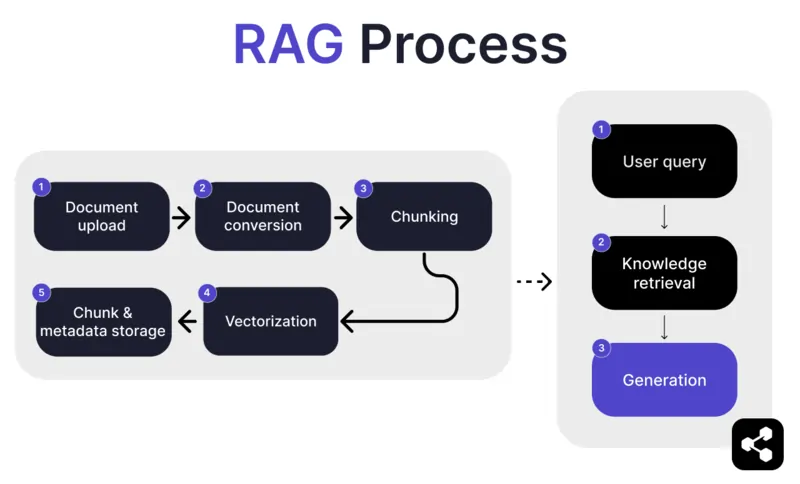
1. Carga de documentos
Primero, el creador sube un documento o archivo a la biblioteca del agente de IA. El archivo puede ser una página web, un PDF u otro formato compatible, y pasa a formar parte de la base de conocimientos de la IA.
2. Conversión de documentos
Como existen muchos tipos de archivos – PDFs, páginas web, etc. – el sistema convierte estos archivos a un formato de texto estandarizado, facilitando que la IA los procese y recupere información relevante.
3. Segmentación y almacenamiento
El documento convertido se divide en partes más pequeñas y manejables, o segmentos. Estos segmentos se almacenan en una base de datos, lo que permite al agente de IA buscar y recuperar eficientemente las secciones relevantes durante una consulta.
4. Consulta del usuario
Una vez configuradas las bases de conocimiento, un usuario puede hacerle una pregunta al agente de IA. La consulta se procesa usando procesamiento de lenguaje natural (PLN) para entender lo que el usuario solicita.
5. Recuperación de conocimiento
El agente de IA busca entre los segmentos almacenados, utilizando algoritmos de recuperación para encontrar la información más relevante de los documentos subidos que pueda responder la pregunta del usuario.
6. Generación
Por último, el agente de IA genera una respuesta combinando la información recuperada con las capacidades de su modelo de lenguaje, elaborando una respuesta coherente y precisa según la consulta y los datos recuperados.
Funciones avanzadas de RAG
Si no eres desarrollador, puede que te sorprenda saber que no todos los RAG son iguales.
Diferentes sistemas construirán distintos modelos RAG, según sus necesidades, casos de uso o nivel de habilidad.
Algunas plataformas de IA ofrecen funciones avanzadas de RAG que pueden mejorar aún más la precisión y confiabilidad de tu software de IA.
Segmentación semántica vs segmentación simple
La segmentación simple consiste en dividir un documento en partes de tamaño fijo, como secciones de 500 palabras, sin importar el significado o el contexto.
La segmentación semántica, en cambio, divide el documento en secciones significativas según el contenido.
Tiene en cuenta divisiones naturales, como párrafos o temas, asegurando que cada segmento contenga información coherente.
Citas obligatorias
Para sectores que automatizan conversaciones de alto riesgo con IA – como finanzas o salud – las citas pueden ayudar a generar confianza en los usuarios al recibir información.
Los desarrolladores pueden configurar sus modelos RAG para que proporcionen citas en toda la información enviada.
Por ejemplo, si un empleado le pide a un chatbot información sobre beneficios de salud, el chatbot puede responder y proporcionar un enlace al documento relevante de beneficios para empleados.
Crea un agente de IA RAG personalizado
Combina el poder de los últimos LLMs con el conocimiento único de tu empresa.
Botpress es una plataforma de chatbots de IA flexible y totalmente extensible.
Permite a los usuarios crear cualquier tipo de agente de IA o chatbot para cualquier caso de uso, y ofrece el sistema RAG más avanzado del mercado.
Integra tu chatbot en cualquier plataforma o canal, o elige de nuestra biblioteca de integraciones preconstruidas. Comienza con tutoriales en el canal de YouTube de Botpress o con cursos gratuitos en Botpress Academy.
Empieza a construir hoy. Es gratis.
Preguntas frecuentes
1. ¿En qué se diferencia RAG del ajuste fino de un LLM?
RAG (Generación aumentada por recuperación) se diferencia del ajuste fino porque RAG mantiene el LLM original sin cambios e incorpora conocimiento externo en tiempo real recuperando documentos relevantes. El ajuste fino modifica los pesos del modelo usando datos de entrenamiento, lo que requiere más recursos y debe repetirse con cada actualización.
2. ¿Qué tipos de fuentes de datos no son adecuadas para RAG?
Las fuentes de datos no adecuadas para RAG incluyen formatos que no son texto, como documentos escaneados, archivos PDF basados en imágenes, archivos de audio sin transcripción y contenido desactualizado o contradictorio. Estos tipos de datos reducen la precisión del contexto recuperado.
3. ¿Cómo se compara RAG con técnicas de aprendizaje en contexto como la ingeniería de prompts?
RAG se diferencia del prompt engineering porque recupera contenido relevante de una base de conocimientos indexada en el momento de la consulta, en lugar de depender de ejemplos estáticos insertados manualmente en el prompt. Esto permite que RAG escale mejor y mantenga el conocimiento actualizado sin necesidad de reentrenar.
4. ¿Puedo usar RAG con LLMs de terceros como OpenAI, Anthropic o Mistral?
Sí, puedes usar RAG con LLMs de OpenAI, Anthropic, Mistral u otros gestionando el proceso de recuperación de manera independiente y enviando el contexto recuperado al LLM a través de su API. RAG es independiente del modelo siempre que el LLM acepte entradas contextuales mediante prompts.
5. ¿Cómo es el mantenimiento continuo de un agente de IA habilitado con RAG?
El mantenimiento continuo de un agente de IA con RAG incluye actualizar la base de conocimientos con documentos nuevos o corregidos, reindexar el contenido periódicamente, evaluar la calidad de la recuperación, ajustar el tamaño de los fragmentos y los métodos de embedding, y monitorear las respuestas del agente para detectar desviaciones o alucinaciones.



