.webp)



- La RAG combine la récupération de données fiables avec la génération par LLM, garantissant des réponses d’IA précises, pertinentes et fondées sur la connaissance réelle de l’entreprise.
- Contrairement aux LLM purs, la RAG réduit les hallucinations en ancrant les réponses dans des documents, bases de données ou contenus validés.
- La RAG permet d’accéder à des informations à jour, offrant à l’IA la capacité de répondre à des questions sur des changements récents ou des sujets de niche qui dépassent les données d’entraînement statiques d’un LLM.
- Maintenir un système RAG implique de garder les données à jour, de surveiller les résultats et d’affiner les méthodes de récupération pour garantir les meilleures performances dans le temps.
La RAG permet aux organisations d’exploiter l’IA – avec moins de risques qu’une utilisation classique des LLM.
La génération augmentée par récupération gagne en popularité à mesure que les entreprises adoptent l’IA. Les premiers chatbots d’entreprise ont connu des erreurs risquées et des hallucinations.
La RAG permet aux entreprises de bénéficier de la puissance des LLM tout en ancrant les réponses générées dans leur propre savoir métier.
Qu’est-ce que la génération augmentée par récupération ?
La génération augmentée par récupération (RAG) en IA combine a) la récupération d’informations externes pertinentes et b) des réponses générées par l’IA, pour améliorer la précision et la pertinence.
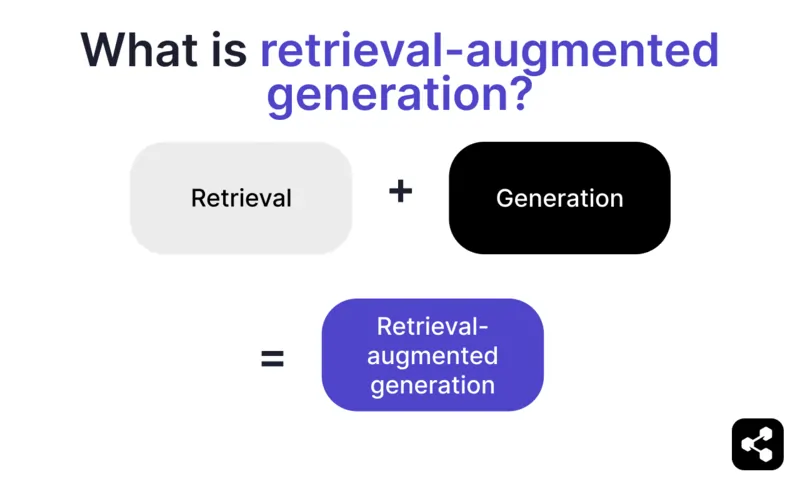
Au lieu de s’appuyer uniquement sur la génération des grands modèles de langage (LLM), les réponses des modèles RAG s’appuient sur des bases de connaissances définies par le créateur de l’agent IA – comme une page web d’entreprise ou un document RH.
La RAG fonctionne en deux étapes principales :
1. Récupération
Le modèle recherche et récupère des données pertinentes à partir de sources structurées ou non structurées (par exemple, bases de données, PDF, fichiers HTML ou autres documents). Ces sources peuvent être structurées (ex. : tableaux) ou non structurées (ex. : sites web validés).
2. Génération
Après la récupération, l’information est transmise au LLM. Le LLM utilise ces données pour générer une réponse en langage naturel, combinant les informations validées avec ses propres capacités linguistiques pour produire des réponses précises, naturelles et conformes à la marque.
Exemples d’utilisation de la RAG
Quel est l’intérêt de la RAG ? Elle permet aux organisations de fournir des réponses pertinentes, informatives et fiables.
La RAG est un moyen direct de réduire le risque de réponses inexactes ou d’hallucinations des LLM.
Exemple 1 : Cabinet d’avocats
Un cabinet d’avocats pourrait utiliser la RAG dans un système d’IA pour :
- Rechercher des jurisprudences, précédents et décisions juridiques dans des bases de documents lors de recherches.
- Générer des résumés de dossiers en extrayant les faits clés à partir des dossiers et décisions antérieures.
- Fournir automatiquement aux employés des mises à jour réglementaires pertinentes.
Exemple 2 : Agence immobilière
Une agence immobilière pourrait utiliser la RAG dans un système d’IA pour :
- Synthétiser les données issues des historiques de transactions et des statistiques de criminalité du quartier.
- Répondre à des questions juridiques sur les transactions immobilières en citant les lois et règlements locaux.
- Optimiser les processus d’estimation en récupérant des données issues des rapports d’état des biens, des tendances du marché et des ventes passées.
Exemple 3 : Boutique e-commerce
Un site e-commerce pourrait utiliser la RAG dans un système d’IA pour :
- Rassembler des informations produits, spécifications et avis depuis la base de données de l’entreprise afin de proposer des recommandations personnalisées.
- Récupérer l’historique des commandes pour générer des expériences d’achat adaptées aux préférences de chaque utilisateur.
- Créer des campagnes d’e-mails ciblées en récupérant les données de segmentation clients et en les combinant avec les derniers achats.
Avantages de la RAG
Comme toute personne ayant interrogé ChatGPT ou Claude le sait, les LLM intègrent peu de garde-fous.
Sans supervision adéquate, ils peuvent produire des informations inexactes, voire dangereuses, ce qui les rend peu fiables pour des usages réels.
La RAG apporte une solution en ancrant les réponses sur des sources de données fiables et à jour, réduisant ainsi considérablement ces risques.
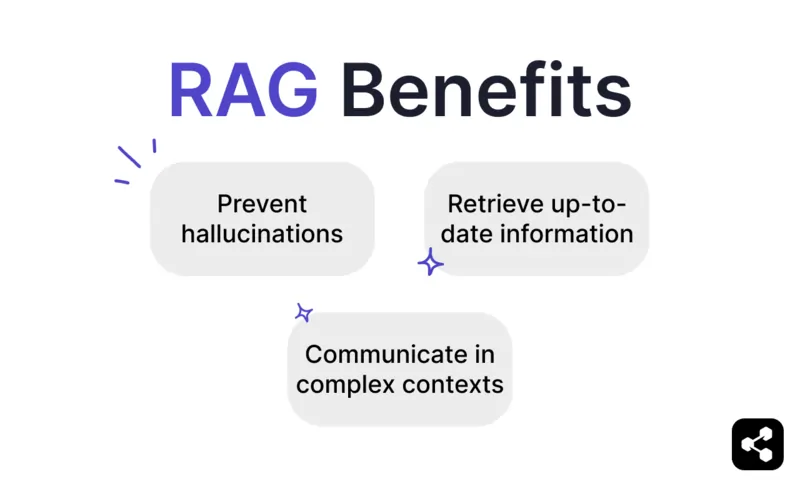
Éviter les hallucinations et les erreurs
Les modèles de langage traditionnels génèrent souvent des hallucinations : des réponses convaincantes mais incorrectes ou hors sujet.
La RAG limite ces hallucinations en s’appuyant sur des sources de données fiables et très pertinentes.
L’étape de récupération garantit que le modèle s’appuie sur des informations exactes et à jour, ce qui réduit fortement le risque d’hallucinations et améliore la fiabilité.
Accéder à des informations à jour
Bien que les LLM soient puissants pour de nombreuses tâches, ils ne peuvent pas fournir d’informations précises sur des sujets rares ou récents – y compris des connaissances métier spécifiques.
Mais la RAG permet au modèle d’aller chercher des informations en temps réel depuis n’importe quelle source, y compris des sites web, des tableaux ou des bases de données.
Cela garantit que, tant que la source de référence est actualisée, le modèle répondra avec des informations à jour.
Communiquer dans des contextes complexes
Une autre faiblesse des LLM traditionnels est la perte d’informations contextuelles.
Les LLM ont du mal à maintenir le contexte lors de conversations longues ou complexes, ce qui aboutit souvent à des réponses incomplètes ou fragmentées.
Mais un modèle RAG permet de conserver le contexte en puisant directement dans des sources de données sémantiquement liées.
Avec des informations supplémentaires ciblées sur les besoins des utilisateurs – comme un chatbot de vente doté d’un catalogue produits – la RAG permet aux agents IA de participer à des échanges contextualisés.
Comment fonctionne la RAG ?
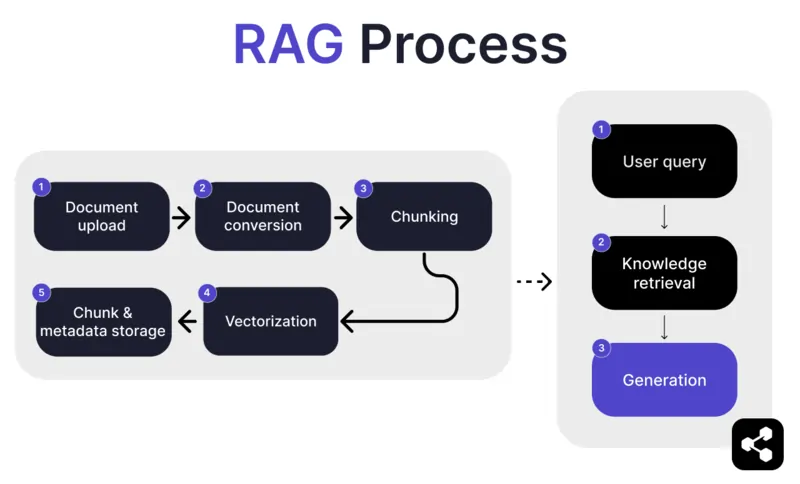
1. Import de document
Tout d’abord, le créateur importe un document ou un fichier dans la bibliothèque de son agent IA. Le fichier peut être une page web, un PDF ou un autre format pris en charge, et il vient enrichir la base de connaissances de l’IA.
2. Conversion du document
Comme il existe de nombreux types de fichiers – PDF, pages web, etc. – le système convertit ces fichiers dans un format texte standardisé, ce qui facilite leur traitement et la récupération d’informations pertinentes par l’IA.
3. Découpage et stockage
Le document converti est ensuite découpé en morceaux plus petits et gérables, appelés « chunks ». Ces morceaux sont stockés dans une base de données, permettant à l’agent IA de rechercher et de récupérer efficacement les sections pertinentes lors d’une requête.
4. Requête utilisateur
Une fois la base de connaissances en place, un utilisateur peut poser une question à l’agent IA. La requête est traitée grâce au traitement du langage naturel (NLP) pour comprendre la demande de l’utilisateur.
5. Récupération des connaissances
L’agent IA parcourt les morceaux stockés, utilisant des algorithmes de récupération pour trouver les informations les plus pertinentes dans les documents importés afin de répondre à la question de l’utilisateur.
6. Génération
Enfin, l’agent IA génère une réponse en combinant les informations récupérées avec ses capacités de langage, pour fournir une réponse cohérente et contextuellement adaptée à la question et aux données trouvées.
Fonctionnalités avancées de la RAG
Si vous n’êtes pas développeur, vous serez peut-être surpris d’apprendre que toutes les RAG ne se valent pas.
Chaque système construit son modèle RAG différemment, selon ses besoins, son cas d’usage ou ses compétences.
Certaines plateformes d’IA proposent des fonctionnalités RAG avancées qui peuvent encore améliorer la précision et la fiabilité de votre solution IA.
Découpage sémantique vs découpage naïf
Le découpage naïf consiste à diviser un document en morceaux de taille fixe, par exemple en sections de 500 mots, sans tenir compte du sens ou du contexte.
Le découpage sémantique, à l’inverse, segmente le document en parties cohérentes selon le contenu.
Il prend en compte les coupures naturelles, comme les paragraphes ou les sujets, pour que chaque morceau contienne une information complète et cohérente.
Citations obligatoires
Pour les secteurs qui automatisent des conversations à risque avec l’IA – comme la finance ou la santé – les citations renforcent la confiance des utilisateurs dans les informations reçues.
Les développeurs peuvent configurer leurs modèles RAG pour fournir une citation pour chaque information transmise.
Par exemple, si un employé demande à un chatbot IA des informations sur les avantages santé, le chatbot peut répondre et fournir un lien vers le document correspondant.
Créer un agent IA RAG sur mesure
Associez la puissance des derniers LLM à la connaissance unique de votre entreprise.
Botpress est une plateforme de chatbot IA flexible et entièrement extensible.
Elle permet de créer tout type d’agent IA ou de chatbot pour n’importe quel usage – et propose le système RAG le plus avancé du marché.
Intégrez votre chatbot à n’importe quelle plateforme ou canal, ou choisissez parmi notre bibliothèque d’intégrations prêtes à l’emploi. Lancez-vous avec les tutoriels de la chaîne YouTube Botpress ou les cours gratuits de Botpress Academy.
Commencez à créer dès aujourd’hui. C’est gratuit.
FAQ
1. En quoi la RAG est-elle différente de l’ajustement fin d’un LLM ?
La génération augmentée par récupération (RAG) diffère de l’ajustement fin, car RAG ne modifie pas le LLM d’origine et injecte des connaissances externes à l’exécution en récupérant des documents pertinents. L’ajustement fin modifie les poids du modèle à l’aide de données d’entraînement, ce qui demande plus de ressources et doit être répété à chaque mise à jour.
2. Quels types de sources de données ne conviennent pas au RAG ?
Les sources de données inadaptées à RAG incluent les formats non textuels comme les documents scannés, les PDF basés sur des images, les fichiers audio sans transcription, ainsi que les contenus obsolètes ou contradictoires. Ces types de données réduisent la précision du contexte récupéré.
3. Comment le RAG se compare-t-il aux techniques d'apprentissage en contexte comme l'ingénierie de prompts ?
RAG se distingue de l'ingénierie de prompt en récupérant, au moment de la requête, du contenu pertinent dans une vaste base de connaissances indexée, au lieu de s'appuyer sur des exemples statiques intégrés manuellement dans le prompt. Cela permet à RAG de mieux passer à l'échelle et de rester à jour sans réentraîner le modèle.
4. Puis-je utiliser le RAG avec des LLM tiers comme OpenAI, Anthropic ou Mistral ?
Oui, vous pouvez utiliser RAG avec des LLM proposés par OpenAI, Anthropic, Mistral ou d'autres fournisseurs, en gérant indépendamment la chaîne de récupération et en envoyant le contexte récupéré au LLM via son API. RAG est indépendant du modèle, tant que le LLM accepte un contexte via les prompts.
5. À quoi ressemble la maintenance continue d’un agent IA utilisant RAG ?
La maintenance continue d’un agent IA utilisant RAG consiste à mettre à jour la base de connaissances avec de nouveaux documents ou des corrections, réindexer régulièrement le contenu, évaluer la qualité de la récupération, ajuster la taille des segments et les méthodes d'embedding, et surveiller les réponses de l’agent pour détecter toute dérive ou hallucination.



