.webp)



- RAG 結合了來自可信資料的檢索與 LLM 生成,確保 AI 回應準確、相關,並且根據真實的商業知識。
- 與純 LLM 不同,RAG 透過將答案錨定於特定文件、資料庫或經核准的內容,降低了產生虛構內容的風險。
- RAG 支援最新資訊,使 AI 系統能夠回答有關近期變動或 LLM 靜態訓練資料以外的特殊主題問題。
- 維護 RAG 系統需要保持資料更新、監控輸出結果,並持續優化檢索方法,以確保長期最佳效能。
RAG 讓企業能夠更安全地運用 AI,風險比傳統 LLM 使用方式更低。
隨著越來越多企業導入 AI 解決方案,檢索增強生成也越來越受歡迎。早期的 企業聊天機器人 曾出現過高風險錯誤與虛構內容。
RAG 讓公司能夠發揮 LLM 的威力,同時將生成內容建立在自身的商業知識上。
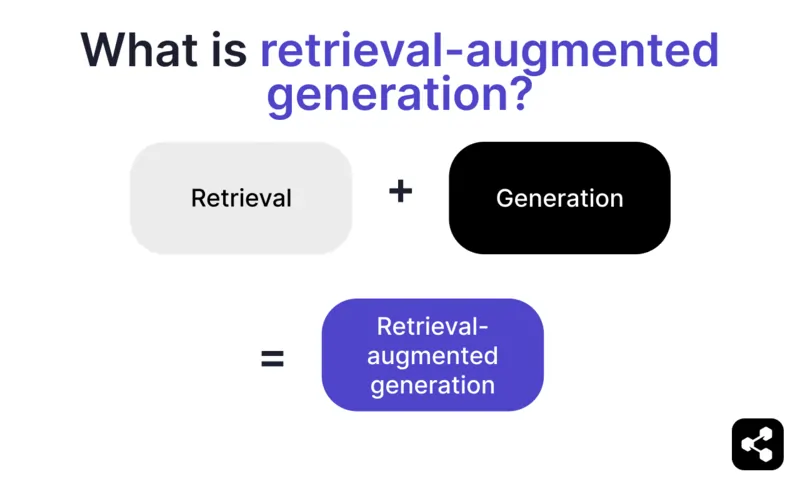
什麼是檢索增強生成?
AI 中的檢索增強生成(RAG)是一種結合「檢索外部相關資訊」與「AI 生成回應」的技術,能提升答案的準確性與相關性。
RAG 模型的回應不是單靠大型語言模型(LLM)生成,而是根據 AI 智能代理設定的知識庫(例如公司網頁或人資政策文件)來產生。
RAG 主要分為兩個步驟:
1. 檢索
模型會從結構化或非結構化來源(如資料庫、PDF、HTML 檔案或其他文件)搜尋並檢索相關資料。這些來源可以是結構化(如表格)或非結構化(如經核准的網站)。
2. 生成
檢索後,資訊會輸入到 LLM。LLM 利用這些資料,結合自身語言能力,生成自然、準確且符合品牌形象的回應。
RAG 應用案例
RAG 的重點是什麼?它讓組織能夠提供相關、有資訊性且準確的輸出。
RAG 是降低 LLM 不準確輸出或虛構內容風險的直接方法。
案例一:律師事務所
律師事務所可能會在 AI 系統中使用 RAG 來:
- 在研究時,從文件資料庫搜尋相關案例法、判例及法律裁決。
- 從案件檔案和過往判決中擷取關鍵事實,生成案件摘要。
- 自動向員工提供相關法規更新。
案例二:房仲公司
房仲公司可能會在 AI 系統中使用 RAG 來:
- 彙整房產交易歷史和社區犯罪統計資料。
- 透過引用當地房產法規,回答有關房產交易的法律問題。
- 從房屋狀況報告、市場趨勢和歷史銷售資料中擷取資訊,簡化估價流程。
案例三:電商商店
電商公司可能會在 AI 系統中使用 RAG 來:
- 從公司資料庫收集產品資訊、規格和評論,提供個人化產品推薦。
- 檢索訂單歷史,打造符合用戶偏好的客製化購物體驗。
- 透過檢索顧客分群資料並結合近期購買行為,生成精準的電子郵件行銷活動。
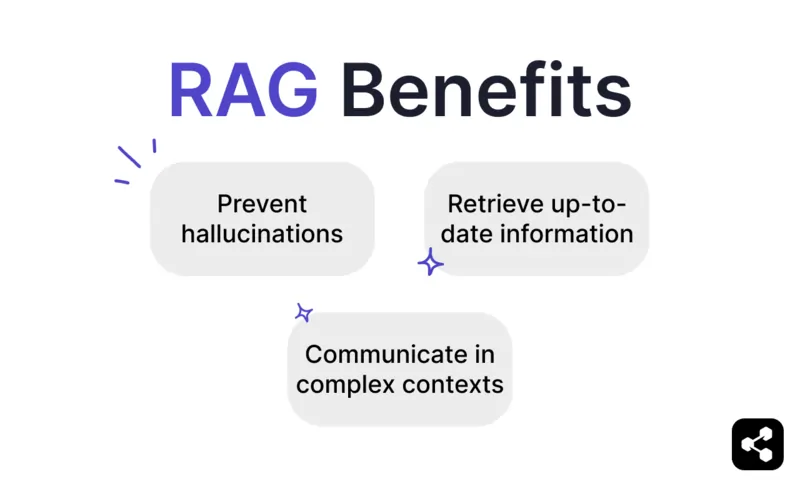
RAG 的優點
任何曾經詢問過 ChatGPT 或 Claude 的人都知道,LLM 內建的防護措施非常有限。
如果缺乏適當監督,LLM 可能產生不準確甚至有害的資訊,導致在實際應用中不可靠。
RAG 透過將回應建立在可信且最新的資料來源上,大幅降低這些風險。
防止虛構內容與錯誤
傳統語言模型經常產生虛構內容——這些回應聽起來合理,實際上卻不正確或無關。
RAG 透過根據可靠且高度相關的資料來源生成回應,減少虛構內容的發生。
檢索步驟確保模型參考的是準確且最新的資訊,顯著降低虛構內容的機率並提升可靠性。
檢索最新資訊
雖然 LLM 適用於許多任務,但無法提供罕見或最新資訊——包括專屬於企業的知識。
但 RAG 讓模型能從任何來源即時取得資訊,包括網站、表格或資料庫。
只要真實資料來源有更新,模型就能回應最新資訊。
能在複雜情境下溝通
傳統 LLM 的另一個弱點是容易遺失上下文資訊。
LLM 難以在冗長或複雜對話中維持上下文,常導致回應不完整或片段化。
但 RAG 模型能直接從語意相關的資料來源擷取資訊,提升對上下文的理解。
針對用戶需求提供額外資訊——例如配備產品型錄的銷售聊天機器人——RAG 讓 AI 助手能參與具上下文的對話。
RAG 如何運作?
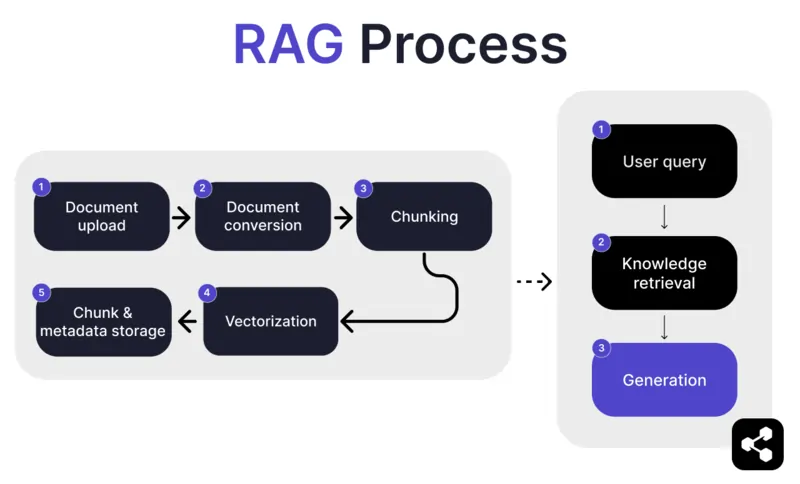
1. 文件上傳
首先,建立者會將文件或檔案上傳到 AI 助手的資料庫。檔案可以是網頁、PDF 或其他支援格式,這些都會成為 AI 的知識來源之一。
2. 文件轉換
由於檔案類型眾多——如 PDF、網頁等——系統會將這些檔案轉換為標準化的文字格式,方便 AI 處理並檢索相關資訊。
3. 分段與儲存
轉換後的文件會被拆分成較小且易於管理的片段。這些片段會儲存在資料庫中,讓 AI 助手在查詢時能有效搜尋並檢索相關內容。
4. 用戶提問
知識庫建立完成後,用戶可以向 AI 助手提問。系統會利用 自然語言處理(NLP) 技術來理解用戶的問題。
5. 知識檢索
AI 助手會在儲存的片段中搜尋,利用檢索演算法找出最能回答用戶問題的相關資訊。
6. 生成回應
最後,AI 助手會將檢索到的資訊與語言模型能力結合,根據提問與取得的資料,生成連貫且符合上下文的答案。
進階 RAG 功能
如果你不是開發者,可能會驚訝地發現,不是所有 RAG 都一樣。
不同系統會根據需求、應用場景或技術能力,建立不同的 RAG 模型。
有些 AI 平台會提供進階的 RAG 功能,進一步提升 AI 軟體的準確性與可靠性。
語意分段 vs. 單純分段
單純分段是指將文件依固定長度切割,例如每 500 字為一段,不考慮內容意義或上下文。
語意分段則是根據內容將文件切割成有意義的段落。
它會考慮自然斷點,如段落或主題,確保每個片段都包含完整且有意義的資訊。
強制引用來源
對於需要自動化高風險對話的產業——如金融或醫療——引用來源能提升用戶對資訊的信任感。
開發者可以設定 RAG 模型,要求所有提供的資訊都必須附上來源。
例如,員工詢問 AI 聊天機器人有關健康福利時,機器人可以回覆並附上相關員工福利文件的連結。
打造專屬的 RAG AI 助手
結合最新 LLM 的強大能力與你的企業專屬知識。
Botpress 是一個靈活且可無限擴充的 AI 聊天機器人平台。
它讓用戶能針對任何應用場景打造各類 AI 助手或聊天機器人——並且擁有市場上最先進的 RAG 系統。
將你的聊天機器人整合到任何平台或通路,或從我們的預建整合庫中選擇。可參考 Botpress YouTube 頻道的教學影片,或 Botpress Academy 的免費課程開始。
立即開始打造,完全免費。
常見問題
1. RAG 與微調 LLM 有什麼不同?
RAG(檢索增強生成)與微調不同,因為 RAG 保持原始 LLM 不變,並在執行時透過檢索相關文件來注入外部知識。微調則是利用訓練資料修改模型權重,這需要更多運算資源,且每次更新都必須重新進行。
2. 哪些類型的資料來源不適合用於 RAG?
不適合用於 RAG 的資料來源包括非文字格式,例如掃描文件、以圖片為主的 PDF、沒有逐字稿的音訊檔案,以及過時或內容互相矛盾的資料。這些資料類型會降低檢索內容的準確性。
3. RAG 和像提示工程這類的情境學習技術相比,有什麼不同?
RAG 與 prompt engineering 不同之處在於,RAG 會在查詢時從大型索引知識庫中檢索相關內容,而不是依賴靜態、手動嵌入在提示中的範例。這讓 RAG 更容易擴充,且能隨時維持最新知識,無需重新訓練。
4. 我可以將 RAG 與第三方大型語言模型(如 OpenAI、Anthropic 或 Mistral)一起使用嗎?
可以,你可以將 RAG 與 OpenAI、Anthropic、Mistral 或其他 LLM 搭配使用,只要獨立處理檢索流程,並透過 API 將檢索到的內容傳送給 LLM。只要 LLM 支援透過提示接收上下文,RAG 就能與其搭配運作,與模型本身無關。
5. 啟用 RAG 的 AI 助理需要持續維護哪些事項?
啟用 RAG 的 AI 助理需要持續維護,包括更新知識庫中的新文件或修正內容、定期重新索引資料、評估檢索品質、調整分段大小與嵌入方法,以及監控助理回應是否出現偏移或幻覺等問題。



