.webp)



- يجمع RAG بين الاسترجاع من بيانات موثوقة وتوليد النماذج اللغوية، مما يضمن أن تكون استجابات الذكاء الاصطناعي دقيقة وذات صلة ومستندة إلى معرفة أعمال حقيقية.
- على عكس النماذج اللغوية البحتة، يقلل RAG من الهلوسة من خلال ربط الإجابات بمستندات أو قواعد بيانات أو محتوى معتمد محدد.
- يدعم RAG المعلومات المحدثة، مما يمكّن أنظمة الذكاء الاصطناعي من الإجابة عن الأسئلة المتعلقة بالتغييرات الأخيرة أو المواضيع المتخصصة التي تتجاوز بيانات تدريب النماذج الثابتة.
- يتطلب الحفاظ على نظام RAG تحديث البيانات باستمرار، ومراقبة المخرجات، وتحسين طرق الاسترجاع لتحقيق أفضل أداء مع مرور الوقت.
يسمح RAG للمؤسسات بالاستفادة من الذكاء الاصطناعي مع تقليل المخاطر مقارنة باستخدام النماذج اللغوية التقليدية.
أصبح التوليد المعزز بالاسترجاع أكثر شيوعًا مع إدخال المزيد من الشركات لحلول الذكاء الاصطناعي. شهدت الدردشات المؤسسية المبكرة أخطاءً خطيرة وهلوسات.
يتيح RAG للشركات الاستفادة من قوة النماذج اللغوية الكبيرة مع ربط المخرجات التوليدية بمعرفة أعمالهم الخاصة.
ما هو التوليد المعزز بالاسترجاع؟
التوليد المعزز بالاسترجاع (RAG) في الذكاء الاصطناعي هو تقنية تجمع بين أ) استرجاع المعلومات الخارجية ذات الصلة و ب) الردود التي يولدها الذكاء الاصطناعي، مما يحسن الدقة والملاءمة.
بدلاً من الاعتماد فقط على توليد النماذج اللغوية الكبيرة (LLMs)، تستند إجابات نماذج RAG إلى قواعد معرفية يحددها منشئ وكيل الذكاء الاصطناعي – مثل صفحة شركة أو وثيقة سياسة الموارد البشرية.
يعمل RAG عبر خطوتين رئيسيتين:
1. الاسترجاع
يبحث النموذج ويسترجع بيانات ذات صلة من مصادر منظمة أو غير منظمة (مثل قواعد البيانات، ملفات PDF، ملفات HTML، أو مستندات أخرى). يمكن أن تكون هذه المصادر منظمة (مثل الجداول) أو غير منظمة (مثل المواقع الإلكترونية المعتمدة).
2. التوليد
بعد الاسترجاع، تُدخل المعلومات إلى النموذج اللغوي الكبير. يستخدم النموذج هذه المعلومات لتوليد استجابة بلغة طبيعية، حيث يدمج البيانات المعتمدة مع قدراته اللغوية لإنتاج ردود دقيقة وطبيعية ومتوافقة مع هوية العلامة التجارية.
أمثلة على استخدامات RAG
ما الهدف من RAG؟ يتيح للمؤسسات تقديم مخرجات ذات صلة ومعلوماتية ودقيقة.
يعد RAG طريقة مباشرة لتقليل مخاطر المخرجات غير الدقيقة أو الهلوسات في النماذج اللغوية الكبيرة.
مثال 1: مكتب محاماة
قد يستخدم مكتب محاماة نظام RAG في الذكاء الاصطناعي من أجل:
- البحث عن القوانين السابقة، والسوابق القضائية، والأحكام القانونية ذات الصلة من قواعد بيانات المستندات أثناء البحث.
- توليد ملخصات القضايا من خلال استخراج الحقائق الرئيسية من ملفات القضايا والأحكام السابقة.
- توفير تحديثات تنظيمية ذات صلة للموظفين بشكل تلقائي.
مثال 2: وكالة عقارية
قد تستخدم وكالة عقارية نظام RAG في الذكاء الاصطناعي من أجل:
- تلخيص بيانات من سجلات معاملات العقارات وإحصائيات الجريمة في الأحياء.
- الإجابة عن الأسئلة القانونية المتعلقة بمعاملات العقارات من خلال الاستشهاد بالقوانين واللوائح المحلية للعقارات.
- تسريع عمليات التقييم العقاري من خلال جمع البيانات من تقارير حالة العقار، واتجاهات السوق، والمبيعات التاريخية.
مثال 3: متجر تجارة إلكترونية
قد يستخدم متجر تجارة إلكترونية نظام RAG في الذكاء الاصطناعي من أجل:
- جمع معلومات المنتجات والمواصفات والتقييمات من قاعدة بيانات الشركة لتقديم توصيات منتجات مخصصة.
- استرجاع سجل الطلبات لتوليد تجارب تسوق مخصصة بناءً على تفضيلات المستخدم.
- توليد حملات بريد إلكتروني مستهدفة من خلال استرجاع بيانات تقسيم العملاء ودمجها مع أنماط الشراء الأخيرة.
فوائد RAG
كما يعلم كل من استخدم ChatGPT أو Claude، فإن النماذج اللغوية الكبيرة لديها حماية محدودة للغاية.
بدون إشراف مناسب، قد تنتج معلومات غير دقيقة أو حتى ضارة، مما يجعلها غير موثوقة للاستخدام في الواقع العملي.
يقدم RAG حلاً من خلال ربط الاستجابات بمصادر بيانات موثوقة ومحدثة، مما يقلل هذه المخاطر بشكل كبير.
منع الهلوسة والأخطاء
غالبًا ما تولد النماذج اللغوية التقليدية هلوسات — أي استجابات تبدو مقنعة لكنها غير صحيحة أو غير ذات صلة.
يقلل RAG من الهلوسة من خلال ربط الاستجابات بمصادر بيانات موثوقة وذات صلة عالية.
تضمن خطوة الاسترجاع أن النموذج يستند إلى معلومات دقيقة ومحدثة، مما يقلل بشكل كبير من احتمال الهلوسة ويزيد من الموثوقية.
استرجاع المعلومات المحدثة
على الرغم من أن النماذج اللغوية الكبيرة أداة قوية للعديد من المهام، إلا أنها غير قادرة على تقديم معلومات دقيقة حول البيانات النادرة أو الحديثة – بما في ذلك المعرفة الخاصة بالأعمال.
لكن RAG يسمح للنموذج بجلب المعلومات في الوقت الفعلي من أي مصدر، بما في ذلك المواقع الإلكترونية أو الجداول أو قواعد البيانات.
هذا يضمن أنه طالما تم تحديث مصدر الحقيقة، سيستجيب النموذج بمعلومات محدثة.
التواصل في سياقات معقدة
ضعف آخر في استخدام النماذج اللغوية التقليدية هو فقدان المعلومات السياقية.
تواجه النماذج اللغوية صعوبة في الحفاظ على السياق في المحادثات الطويلة أو المعقدة، مما يؤدي غالبًا إلى استجابات غير مكتملة أو مجزأة.
لكن نموذج RAG يسمح بالحفاظ على الوعي بالسياق من خلال جلب المعلومات مباشرة من مصادر بيانات مترابطة دلاليًا.
مع معلومات إضافية موجهة خصيصًا لاحتياجات المستخدمين – مثل روبوت دردشة مبيعات مزود بكتالوج المنتجات – يتيح RAG للوكلاء الذكيين المشاركة في محادثات سياقية.
كيف يعمل RAG؟
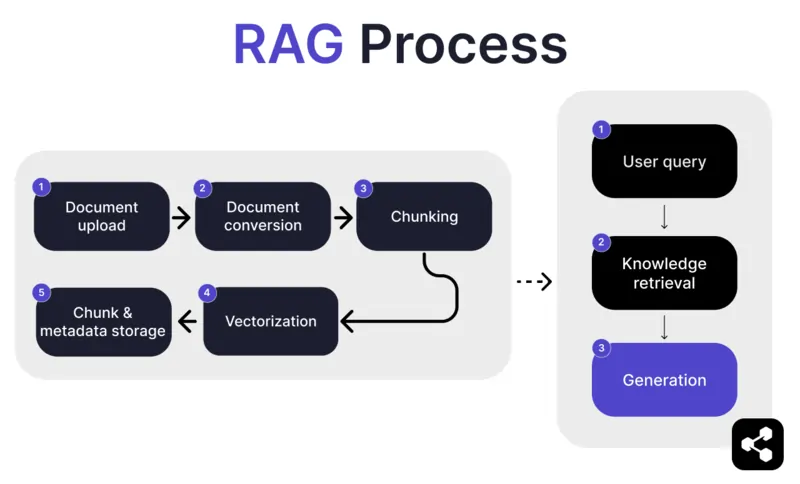
1. رفع المستندات
أولاً، يقوم المنشئ برفع مستند أو ملف إلى مكتبة وكيل الذكاء الاصطناعي الخاص به. يمكن أن يكون الملف صفحة ويب أو PDF أو أي صيغة مدعومة أخرى، ليصبح جزءًا من قاعدة معرفة الذكاء الاصطناعي.
2. تحويل المستندات
نظرًا لتعدد أنواع الملفات – مثل PDF أو صفحات الويب – يقوم النظام بتحويل هذه الملفات إلى صيغة نصية موحدة، مما يسهل على الذكاء الاصطناعي معالجتها واسترجاع المعلومات ذات الصلة منها.
3. تقسيم وتخزين
يتم بعد ذلك تقسيم المستند المحول إلى أجزاء أصغر يمكن إدارتها، أو ما يسمى "قطع". تُخزن هذه القطع في قاعدة بيانات، مما يسمح لوكيل الذكاء الاصطناعي بالبحث بكفاءة واسترجاع الأقسام ذات الصلة أثناء الاستعلام.
4. استعلام المستخدم
بعد إعداد قواعد المعرفة، يمكن للمستخدم طرح سؤال على وكيل الذكاء الاصطناعي. تتم معالجة الاستعلام باستخدام معالجة اللغة الطبيعية (NLP) لفهم ما يطلبه المستخدم.
5. استرجاع المعرفة
يبحث وكيل الذكاء الاصطناعي في القطع المخزنة، مستخدمًا خوارزميات الاسترجاع للعثور على أكثر المعلومات صلة من المستندات المرفوعة والتي يمكن أن تجيب على سؤال المستخدم.
6. التوليد
أخيرًا، سيقوم وكيل الذكاء الاصطناعي بتوليد استجابة من خلال دمج المعلومات المسترجعة مع قدراته في النماذج اللغوية، ليصيغ إجابة متماسكة ودقيقة سياقيًا بناءً على الاستعلام والبيانات المسترجعة.
ميزات RAG المتقدمة
إذا لم تكن مطورًا، قد يفاجئك أن ليس كل أنظمة RAG متساوية.
ستبني الأنظمة المختلفة نماذج RAG مختلفة حسب الحاجة أو حالة الاستخدام أو مستوى المهارة.
بعض منصات الذكاء الاصطناعي تقدم ميزات RAG متقدمة يمكن أن تعزز دقة وموثوقية برنامجك الذكي بشكل أكبر.
التقسيم الدلالي مقابل التقسيم البسيط
التقسيم البسيط هو عندما يتم تقسيم المستند إلى أجزاء ذات حجم ثابت، مثل تقطيع النص إلى أقسام من 500 كلمة بغض النظر عن المعنى أو السياق.
أما التقسيم الدلالي، فيقسم المستند إلى أقسام ذات معنى بناءً على المحتوى.
يراعي التقسيم الدلالي الفواصل الطبيعية مثل الفقرات أو المواضيع، مما يضمن أن كل جزء يحتوي على معلومة متماسكة.
الاستشهادات الإلزامية
بالنسبة للقطاعات التي تعتمد على أتمتة المحادثات عالية المخاطر بالذكاء الاصطناعي – مثل المالية أو الرعاية الصحية – يمكن أن تساعد الاستشهادات في تعزيز ثقة المستخدمين عند تلقي المعلومات.
يمكن للمطورين توجيه نماذج RAG الخاصة بهم لتقديم استشهادات لأي معلومة يتم إرسالها.
على سبيل المثال، إذا طلب موظف من روبوت دردشة معلومات حول مزايا الموظفين الصحية، يمكن للروبوت الرد وتقديم رابط إلى مستند مزايا الموظفين ذي الصلة.
بناء وكيل ذكاء اصطناعي مخصص باستخدام RAG
اجمع بين قوة أحدث النماذج اللغوية الكبيرة ومعرفتك المؤسسية الفريدة.
Botpress منصة روبوتات ذكاء اصطناعي مرنة وقابلة للتوسعة بلا حدود.
تتيح للمستخدمين بناء أي نوع من وكلاء الذكاء الاصطناعي أو روبوتات الدردشة لأي حالة استخدام – وتوفر أكثر أنظمة RAG تقدمًا في السوق.
قم بدمج روبوت الدردشة الخاص بك مع أي منصة أو قناة، أو اختر من مكتبة التكاملات الجاهزة لدينا. ابدأ مع الدروس التعليمية على قناة Botpress على يوتيوب أو الدورات المجانية من Botpress Academy.
ابدأ البناء اليوم. إنها مجانية.
الأسئلة الشائعة
1. كيف يختلف RAG عن ضبط النماذج اللغوية الكبيرة؟
تُعد تقنية RAG (التوليد المعزز بالاسترجاع) مختلفة عن الضبط الدقيق، إذ تبقي RAG نموذج اللغة الكبير الأصلي دون تغيير وتضيف المعرفة الخارجية أثناء التنفيذ من خلال استرجاع المستندات ذات الصلة. أما الضبط الدقيق فيعدل أوزان النموذج باستخدام بيانات تدريبية، مما يتطلب موارد حسابية أكبر ويجب تكراره مع كل تحديث.
2. ما هي أنواع مصادر البيانات التي لا تناسب RAG؟
تشمل مصادر البيانات غير المناسبة لتقنية RAG الصيغ غير النصية مثل المستندات الممسوحة ضوئيًا، وملفات PDF المعتمدة على الصور، وملفات الصوت بدون نصوص مكتوبة، والمحتوى القديم أو المتعارض. هذه الأنواع من البيانات تقلل من دقة السياق المسترجع.
3. كيف يقارن RAG بتقنيات التعلم في السياق مثل هندسة التعليمات؟
تختلف تقنية RAG عن هندسة المحفزات في أنها تسترجع محتوى ذا صلة من قاعدة معرفة مفهرسة كبيرة عند الاستعلام، بدلاً من الاعتماد على أمثلة ثابتة ومدمجة يدويًا في المحفز. يتيح ذلك لـ RAG التوسع بشكل أفضل والحفاظ على معرفة محدثة دون الحاجة لإعادة تدريب النموذج.
4. هل يمكنني استخدام RAG مع نماذج اللغة الكبيرة من جهات خارجية مثل OpenAI أو Anthropic أو Mistral؟
نعم، يمكنك استخدام RAG مع نماذج اللغة الكبيرة من OpenAI أو Anthropic أو Mistral أو غيرها، وذلك من خلال إدارة عملية الاسترجاع بشكل مستقل وإرسال السياق المسترجع إلى النموذج عبر واجهة برمجة التطبيقات الخاصة به. تقنية RAG لا تعتمد على نوع النموذج طالما يدعم استقبال مدخلات سياقية عبر المحفزات.
5. كيف تبدو عملية الصيانة المستمرة لوكيل ذكاء اصطناعي يعمل بتقنية RAG؟
تشمل الصيانة المستمرة لوكيل ذكاء اصطناعي يعمل بتقنية RAG تحديث قاعدة المعرفة بمستندات جديدة أو مصححة، وإعادة فهرسة المحتوى بشكل دوري، وتقييم جودة الاسترجاع، وضبط حجم الأجزاء وطرق التضمين، ومراقبة استجابات الوكيل لرصد الانحراف أو المشكلات المتعلقة بالهلوسة.



