.webp)



- Pinagsasama ng RAG ang pagkuha mula sa mapagkakatiwalaang datos at LLM generation, kaya tinitiyak na ang mga sagot ng AI ay tama, may kaugnayan, at nakaugat sa tunay na kaalaman ng negosyo.
- Hindi tulad ng purong LLMs, binabawasan ng RAG ang mga maling sagot (hallucinations) sa pamamagitan ng pag-angkla ng mga sagot sa tiyak na mga dokumento, database, o aprubadong nilalaman.
- Sinusuportahan ng RAG ang napapanahong impormasyon, kaya kayang sagutin ng AI ang mga tanong tungkol sa mga bagong pagbabago o espesyalisadong paksa na wala sa static na training data ng LLM.
- Ang pagpapanatili ng RAG system ay nangangailangan ng regular na pag-update ng datos, pagmamanman ng mga output, at paghasa ng mga retrieval method para sa pinakamainam na performance sa paglipas ng panahon.
Pinapayagan ng RAG ang mga organisasyon na magamit ang AI—na may mas kaunting panganib kaysa sa tradisyonal na paggamit ng LLM.
Lalong sumisikat ang retrieval-augmented generation habang mas maraming negosyo ang nagpapakilala ng AI solutions. Ang mga unang enterprise chatbot ay nagpakita ng mapanganib na pagkakamali at maling sagot.
Pinapayagan ng RAG ang mga kumpanya na magamit ang lakas ng LLMs habang nakaugat ang mga sagot sa kanilang partikular na kaalaman sa negosyo.
Ano ang retrieval-augmented generation?
Ang Retrieval-augmented generation (RAG) sa AI ay isang teknik na pinagsasama ang a) pagkuha ng kaugnay na panlabas na impormasyon at b) AI-generated na sagot, para mapabuti ang katumpakan at kaugnayan.
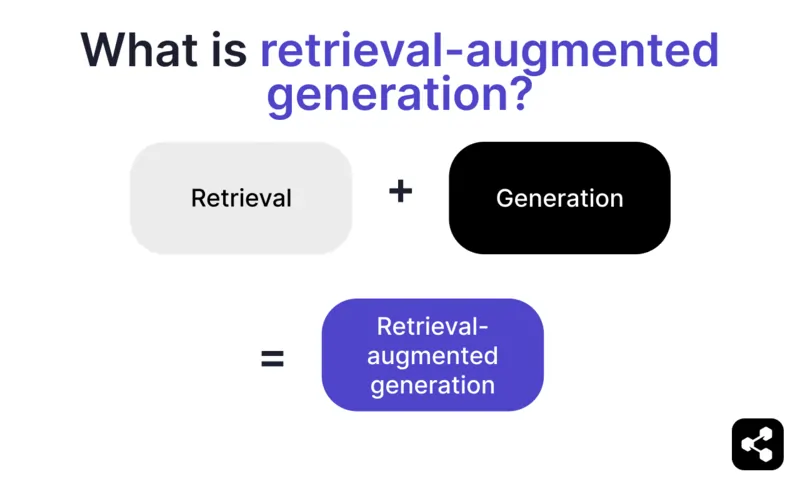
Sa halip na umasa lang sa generation ng large language models (LLMs), ang mga sagot mula sa RAG models ay nakabase sa knowledge base na itinakda ng AI agent builder – gaya ng webpage ng kumpanya o HR policy document.
Dalawang pangunahing hakbang ang ginagawa ng RAG:
1. Retrieval
Hinahanap ng modelo at kinukuha ang kaugnay na datos mula sa mga structured o unstructured na pinagmumulan (hal. database, PDF, HTML files, o iba pang dokumento). Maaaring structured (hal. mga talahanayan) o unstructured (hal. aprubadong websayt) ang mga ito.
2. Generation
Pagkatapos ng retrieval, ipapasok ang impormasyon sa LLM. Gagamitin ng LLM ang datos na ito upang bumuo ng natural na sagot sa wika ng tao, pinagsasama ang aprubadong datos at sariling kakayahan sa wika upang makalikha ng tama, makatao, at akmang sagot para sa brand.
Mga Halimbawa ng Paggamit ng RAG
Ano ang layunin ng RAG? Pinapahintulutan nito ang mga organisasyon na magbigay ng may kaugnayan, kapaki-pakinabang, at tamang output.
Direktang paraan ang RAG upang mabawasan ang panganib ng maling sagot o hallucinations mula sa LLM.
Halimbawa 1: Law Firm
Maaaring gumamit ang isang law firm ng RAG sa AI system upang:
- Maghanap ng kaugnay na mga batas ng kaso, precedent, at legal na desisyon mula sa mga database ng dokumento habang nagsasaliksik.
- Bumuo ng buod ng kaso sa pamamagitan ng pagkuha ng mahahalagang detalye mula sa mga file ng kaso at mga naunang desisyon.
- Awtomatikong magbigay sa mga empleyado ng mga kaugnay na update sa regulasyon.
Halimbawa 2: Real Estate Agency
Maaaring gumamit ang isang real estate agency ng RAG sa AI system upang:
- Ibuod ang datos mula sa kasaysayan ng mga transaksyon sa ari-arian at istatistika ng krimen sa paligid.
- Sagutin ang mga legal na tanong tungkol sa transaksyon ng ari-arian sa pamamagitan ng pagsipi ng lokal na batas at regulasyon.
- Pabilisin ang appraisal process sa pamamagitan ng pagkuha ng datos mula sa mga ulat ng kondisyon ng ari-arian, galaw ng merkado, at kasaysayan ng bentahan.
Halimbawa 3: E-Commerce Store
Maaaring gumamit ang isang e-commerce ng RAG sa AI system upang:
- Kunin ang impormasyon ng produkto, mga detalye, at mga review mula sa database ng kumpanya upang magbigay ng personalisadong rekomendasyon ng produkto.
- Kunin ang kasaysayan ng order upang makabuo ng karanasan sa pamimili na akma sa kagustuhan ng user.
- Bumuo ng mga targeted na email campaign sa pamamagitan ng pagkuha ng datos ng customer segmentation at pagsasama nito sa mga pinakabagong pattern ng pagbili.
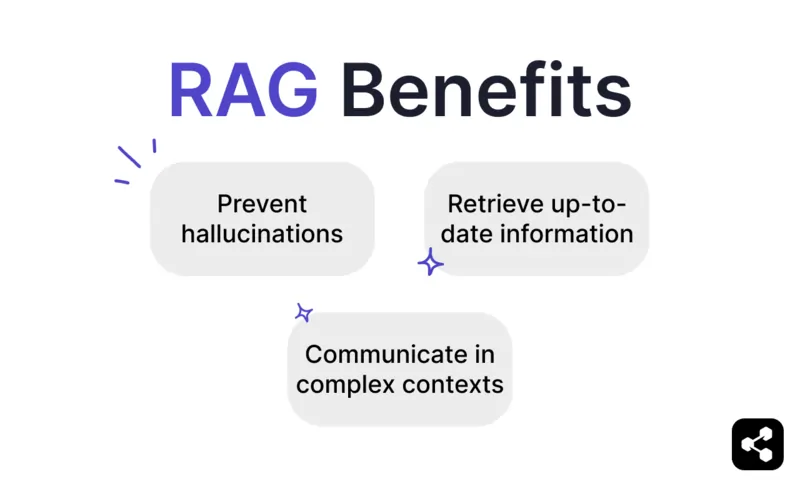
Mga Benepisyo ng RAG
Alam ng sinumang gumamit ng ChatGPT o Claude na kakaunti ang built-in na safeguards ng LLMs.
Kung walang tamang pagmamanman, maaari silang maglabas ng maling o mapanganib na impormasyon, kaya hindi sila mapagkakatiwalaan para sa paggamit sa totoong mundo.
Nag-aalok ang RAG ng solusyon sa pamamagitan ng pagbatay ng mga sagot sa mapagkakatiwalaan at napapanahong datos, kaya malaki ang nababawas na panganib.
Iwasan ang hallucinations at pagkakamali
Madalas maglabas ng hallucinations ang tradisyonal na language models—mga sagot na mukhang tama ngunit mali o walang kaugnayan.
Binabawasan ng RAG ang hallucinations sa pamamagitan ng pagbatay ng mga sagot sa mapagkakatiwalaan at napapanahong datos.
Tinitiyak ng retrieval step na tumutukoy ang modelo sa tama at napapanahong impormasyon, kaya malaki ang nababawas na posibilidad ng hallucinations at tumataas ang pagiging mapagkakatiwalaan.
Kunin ang napapanahong impormasyon
Bagamat malakas na kasangkapan ang LLMs para sa maraming gawain, hindi nila kayang magbigay ng tama at napapanahong impormasyon tungkol sa bihira o bagong datos—pati na ang espesipikong kaalaman ng negosyo.
Ngunit pinapayagan ng RAG ang modelo na kumuha ng real-time na impormasyon mula sa anumang pinagmumulan, kabilang ang websayt, talahanayan, o database.
Tinitiyak nito na basta't updated ang source of truth, magbibigay ang modelo ng napapanahong impormasyon.
Makipag-usap sa komplikadong konteksto
Isa pang kahinaan ng tradisyonal na LLM ay ang pagkawala ng konteksto.
Nahihirapan ang LLMs na panatilihin ang konteksto sa mahaba o komplikadong usapan. Madalas, nagreresulta ito sa hindi kumpleto o putol-putol na sagot.
Ngunit pinapayagan ng RAG model ang context awareness sa pamamagitan ng direktang pagkuha ng impormasyon mula sa magkakaugnay na pinagmumulan ng datos.
Sa dagdag na impormasyong nakatuon sa pangangailangan ng user—tulad ng sales chatbot na may kasamang katalogo ng produkto—nagagawa ng RAG na makipag-usap ang AI agents sa kontekstuwal na usapan.
Paano gumagana ang RAG?
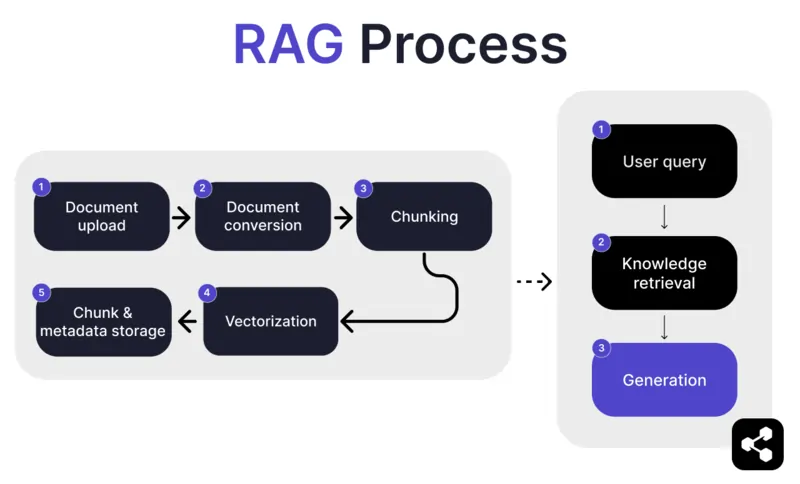
1. Pag-upload ng Dokumento
Una, ina-upload ng tagabuo ang dokumento o file sa library ng AI agent. Maaaring websayt, PDF, o iba pang suportadong format ang file, na nagiging bahagi ng kaalaman ng AI.
2. Pag-convert ng Dokumento
Dahil maraming uri ng file—PDF, websayt, atbp.—kinokonvert ng sistema ang mga ito sa iisang format ng teksto, upang mas madali para sa AI na iproseso at kunin ang kaugnay na impormasyon.
3. Pag-chunk at Imbakan
Hinahati ang na-convert na dokumento sa maliliit at madaling pamahalaang bahagi o chunks. Iniimbak ang mga chunk na ito sa database, kaya mabilis na mahahanap at makukuha ng AI agent ang mga kaugnay na bahagi kapag may tanong.
4. Query ng User
Kapag na-setup na ang knowledge base, maaaring magtanong ang user sa AI agent. Pinoproseso ang tanong gamit ang natural language processing (NLP) para maintindihan ang tanong ng user.
5. Pagkuha ng Kaalaman
Hahanapin ng AI agent sa mga nakaimbak na chunk gamit ang retrieval algorithms ang pinaka-kaugnay na impormasyon mula sa mga na-upload na dokumento na makakasagot sa tanong ng user.
6. Generation
Sa huli, bubuo ang AI agent ng sagot sa pamamagitan ng pagsasama ng nakuha nitong impormasyon at kakayahan ng language model, para makagawa ng malinaw at akmang sagot batay sa query at datos.
Mga Advanced na Tampok ng RAG
Kung hindi ka developer, maaaring magulat ka na hindi pare-pareho ang lahat ng RAG.
Magkakaiba ang mga sistema sa paggawa ng RAG models, depende sa pangangailangan, gamit, o kakayahan.
May ilang AI platform na nag-aalok ng mga advanced na tampok ng RAG na lalo pang nagpapahusay sa katumpakan at pagiging mapagkakatiwalaan ng iyong AI software.
Semantic vs naive chunking
Ang naive chunking ay kapag hinati ang dokumento sa pantay-pantay na laki, tulad ng paghati ng teksto kada 500 salita, kahit walang pakialam sa kahulugan o konteksto.
Ang semantic chunking naman ay paghahati ng dokumento batay sa makabuluhang bahagi ayon sa nilalaman.
Isinasaalang-alang nito ang natural na paghinto, tulad ng talata o paksa, para masigurong bawat chunk ay may buo at malinaw na impormasyon.
Obligatory na mga citation
Para sa mga industriyang nag-a-automate ng sensitibong usapan gamit ang AI—tulad ng pananalapi o kalusugan—makakatulong ang citations para mapalakas ang tiwala ng user sa impormasyong natatanggap nila.
Maaaring utusan ng mga developer ang kanilang RAG models na magbigay ng citation para sa anumang impormasyong ipinapadala.
Halimbawa, kung magtanong ang empleyado sa AI chatbot tungkol sa health benefits, maaaring sumagot ang chatbot at magbigay ng link sa kaugnay na dokumento ng employee benefits.
Bumuo ng Custom na RAG AI Agent
Pagsamahin ang lakas ng pinakabagong LLMs at ang natatanging kaalaman ng iyong negosyo.
Ang Botpress ay isang nababagay at walang katapusang mapapalawak na AI chatbot platform.
Pinapayagan nito ang mga user na bumuo ng kahit anong uri ng AI agent o chatbot para sa anumang gamit—at nag-aalok ng pinaka-advanced na RAG system sa merkado.
I-integrate ang iyong chatbot sa anumang platform o channel, o pumili mula sa aming pre-built integration library. Magsimula gamit ang mga tutorial mula sa Botpress YouTube channel o sa mga libreng kurso ng Botpress Academy.
Simulan ang paggawa ngayon. Libre ito.
FAQs
1. Ano ang pinagkaiba ng RAG sa fine-tuning ng LLM?
Ang RAG (Retrieval-Augmented Generation) ay naiiba sa fine-tuning dahil nananatiling hindi binabago ang orihinal na LLM at nagdadagdag ng panlabas na kaalaman sa mismong oras ng paggamit sa pamamagitan ng pagkuha ng mga kaugnay na dokumento. Sa fine-tuning, binabago ang mga timbang ng modelo gamit ang training data, na nangangailangan ng mas malaking compute at inuulit tuwing may update.
2. Anong mga uri ng pinagkukunan ng datos ang hindi angkop para sa RAG?
Hindi angkop para sa RAG ang mga pinagkukunan ng datos na hindi teksto gaya ng mga na-scan na dokumento, PDF na larawan ang nilalaman, audio file na walang transcript, at mga lumang o magkasalungat na impormasyon. Nakakabawas ito sa katumpakan ng nakukuhang konteksto.
3. Paano inihahambing ang RAG sa mga teknik ng in-context learning tulad ng prompt engineering?
Iba ang RAG sa prompt engineering dahil kumukuha ito ng kaugnay na nilalaman mula sa malawak na naka-index na base ng kaalaman tuwing may tanong, imbes na umasa sa mga static at mano-manong halimbawa sa prompt. Dahil dito, mas madaling palawakin ang RAG at napapanatili nitong bago ang kaalaman nang hindi na kailangang i-retrain.
4. Maaari ko bang gamitin ang RAG kasama ang mga third-party na LLM tulad ng OpenAI, Anthropic, o Mistral?
Oo, maaari mong gamitin ang RAG sa mga LLM mula sa OpenAI, Anthropic, Mistral, o iba pa sa pamamagitan ng hiwalay na paghawak sa retrieval pipeline at pagpapadala ng nakuha mong konteksto sa LLM gamit ang API nito. Model-agnostic ang RAG basta't tumatanggap ng contextual input ang LLM sa pamamagitan ng prompt.
5. Ano ang anyo ng patuloy na pagmintina ng isang RAG-enabled na AI agent?
Kasama sa patuloy na maintenance ng isang RAG-enabled na AI agent ang pag-update ng knowledge base gamit ang mga bagong o naiwastong dokumento, regular na pag-reindex ng nilalaman, pagsusuri ng kalidad ng retrieval, pag-aayos ng laki ng chunk at paraan ng embedding, at pagmamanman sa mga sagot ng agent para sa mga isyu ng paglihis o maling sagot.



