



- L’ASR trasforma la voce in testo tramite machine learning, abilitando comandi vocali e trascrizione in tempo reale.
- I moderni sistemi ASR sono passati da modelli fonemici separati (HMM-GMM) a modelli di deep learning che prevedono intere parole.
- Le prestazioni ASR sono misurate tramite il Word Error Rate (WER), con errori dovuti a sostituzioni, cancellazioni o inserimenti; un WER più basso = migliore qualità della trascrizione.
- Il futuro dell’ASR punta sull’elaborazione on-device per la privacy e sul supporto alle lingue meno diffuse.
Quando è stata l’ultima volta che hai guardato qualcosa senza sottotitoli?
Un tempo erano opzionali, ora scorrono su tutti i video brevi, che lo vogliamo o no. I sottotitoli sono così integrati nei contenuti che ci si dimentica della loro presenza.
Il riconoscimento vocale automatico (ASR) — la capacità di convertire rapidamente e con precisione le parole pronunciate in testo — è la tecnologia che alimenta questo cambiamento.
Quando pensiamo a un agente vocale IA, consideriamo la scelta delle parole, il tono e la voce con cui parla.
Ma è facile dimenticare che la fluidità delle nostre interazioni dipende dalla capacità del bot di comprenderci. E arrivare a questo punto — il bot che ti capisce tra “ehm” e “uh” in un ambiente rumoroso — non è stato affatto semplice.
Oggi parleremo della tecnologia che alimenta quei sottotitoli: il riconoscimento automatico del parlato (ASR).
Permettimi di presentarmi: ho un master in tecnologia vocale e nel tempo libero mi piace approfondire le ultime novità in ASR e persino costruire progetti.
Ti spiegherò le basi dell'ASR, ti mostrerò cosa c'è dietro la tecnologia e azzarderò qualche ipotesi su dove potrebbe andare in futuro.
Cos’è l’ASR?
Il riconoscimento vocale automatico (ASR), o speech-to-text (STT), è il processo che converte la voce in testo scritto tramite tecnologia di machine learning.
Le tecnologie che coinvolgono la voce spesso integrano l'ASR in qualche modo; può essere usato per sottotitolare video, trascrivere interazioni di assistenza clienti per analisi, oppure come parte di un'interazione con un assistente vocale, solo per citarne alcuni.
Algoritmi speech-to-text
Le tecnologie di base sono cambiate nel tempo, ma tutte le versioni hanno sempre avuto due componenti fondamentali: dati e un modello.
Nel caso dell’ASR, i dati sono costituiti da parlato etichettato – file audio di lingua parlata e le relative trascrizioni.
Il modello è l’algoritmo utilizzato per prevedere la trascrizione dall’audio. I dati etichettati vengono usati per addestrare il modello, così che possa generalizzare su esempi vocali non visti.
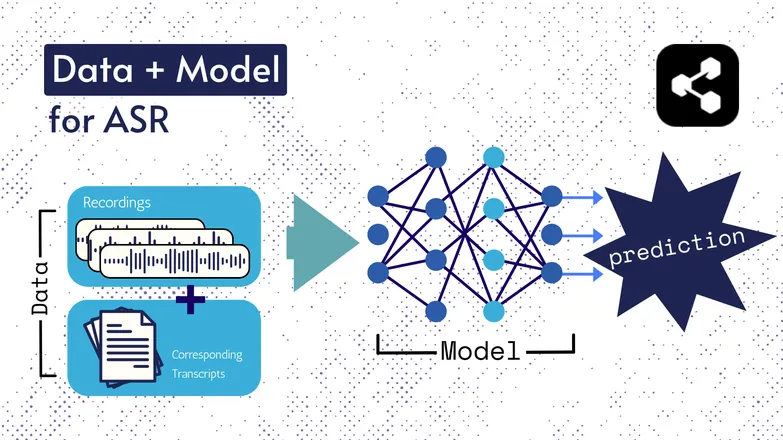
È un po’ come quando riesci a capire una serie di parole, anche se non le hai mai sentite in quell’ordine o sono pronunciate da uno sconosciuto.
Anche i tipi di modelli e le loro specifiche sono cambiati nel tempo, e tutti i progressi in velocità e accuratezza dipendono dalla dimensione e dalle caratteristiche dei dataset e dei modelli.
Nota veloce: Estrazione delle caratteristiche
Ho parlato di feature, o rappresentazioni nel mio articolo sul text-to-speech. Sono utilizzate nei modelli ASR, sia passati che attuali.
L’estrazione delle caratteristiche — ovvero la conversione della voce in elementi utili — è il primo passo in quasi tutte le pipeline ASR.
In breve, queste caratteristiche, spesso spettrogrammi, sono il risultato di un calcolo matematico applicato al parlato e trasformano il parlato in un formato che enfatizza le somiglianze all’interno di un enunciato e minimizza le differenze tra i vari parlanti.
Cioè, la stessa frase pronunciata da 2 persone diverse avrà spettrogrammi simili, indipendentemente da quanto siano diverse le loro voci.
Lo sottolineo per chiarire che parlerò di modelli che “predicono trascrizioni dal parlato”. Tecnicamente non è corretto; i modelli predicono a partire da feature. Ma puoi considerare l’estrazione delle feature come parte del modello.
ASR iniziale: HMM-GMM
Hidden Markov Models (HMMs) e Gaussian Mixture Models (GMMs) sono modelli predittivi precedenti all’avvento delle reti neurali profonde.
Gli HMM hanno dominato l’ASR fino a poco tempo fa.
Dato un file audio, l’HMM prevederebbe la durata di un fonema e il GMM prevederebbe il fonema stesso.
Sembra un controsenso, e in un certo senso lo è, tipo:
- HMM: “I primi 0,2 secondi sono un fonema.”
- GMM: “Quel fonema è una G, come in Gary.”
Convertire una clip audio in testo richiederebbe alcuni componenti aggiuntivi, ovvero:
- Un dizionario di pronuncia: un elenco esaustivo delle parole nel vocabolario, con le rispettive pronunce.
- Un modello linguistico: combinazioni di parole nel vocabolario e le loro probabilità di co-occorrenza.
Quindi, anche se il GMM prevede /f/ invece di /s/, il modello linguistico sa che è molto più probabile che il parlante abbia detto “a penny for your thoughts”, non foughts.
Avevamo tutte queste parti perché, per dirla chiaramente, nessuna parte di questa pipeline era particolarmente valida.
L’HMM sbagliava gli allineamenti, il GMM confondeva suoni simili: /s/ e /f/, /p/ e /t/, e non parliamo nemmeno delle vocali.
E poi il modello linguistico sistemerebbe il caos di fonemi incoerenti in qualcosa di più simile a una lingua.
ASR end-to-end con Deep Learning
Molte delle parti di una pipeline ASR sono state da allora consolidate.
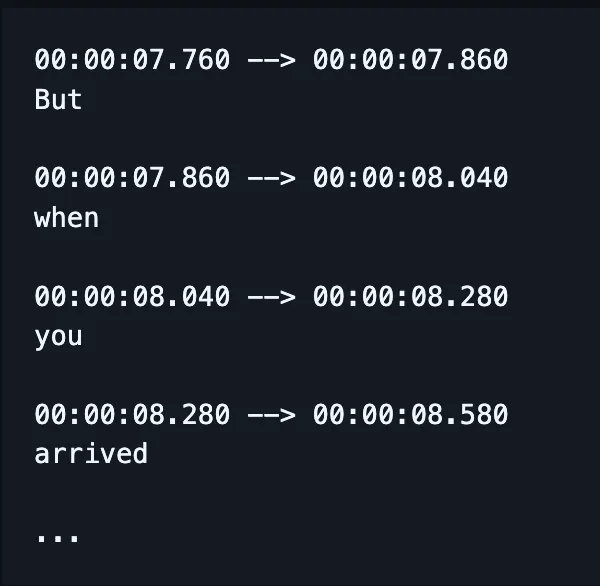
Invece di addestrare modelli separati per gestire ortografia, allineamento e pronuncia, un unico modello riceve l’audio e restituisce (si spera) le parole scritte correttamente e, oggi, anche i timestamp.
(Anche se spesso le implementazioni correggono, o “ri-valutano”, questo output con un modello linguistico aggiuntivo.)
Questo non significa che fattori diversi — come allineamento e ortografia — non ricevano attenzione specifica. Esistono ancora numerose pubblicazioni dedicate a soluzioni per problemi molto mirati.
Cioè, i ricercatori trovano modi per modificare l’architettura di un modello puntando a specifici fattori delle sue prestazioni, come ad esempio:
- Un decoder RNN-Transducer condizionato sulle uscite precedenti per migliorare l’ortografia.
- Downsampling convoluzionale per limitare output vuoti e migliorare l’allineamento.
So che è una sciocchezza. Sto solo anticipando la domanda del mio capo: “puoi farmi un esempio in parole semplici?”
La risposta è no.
No, non posso.
Come si misura la performance nell’ASR?
Quando l’ASR non funziona bene, te ne accorgi.
Ho visto caramelization trascritto come comunisti asiatici. Crispiness come Chris p — hai capito.
La metrica che usiamo per riflettere matematicamente gli errori è il word error rate (WER). La formula del WER è:
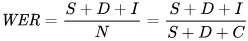
Dove:
- S è il numero di sostituzioni (parole cambiate nel testo previsto per farlo corrispondere al testo di riferimento)
- D è il numero di eliminazioni (parole mancanti nell’output rispetto al testo di riferimento)
- I è il numero di inserimenti (parole aggiuntive nell’output rispetto al testo di riferimento)
- N è il numero totale di parole nel riferimento
Ad esempio, la frase di riferimento è “the cat sat”.
- Se il modello restituisce “il gatto affondò”, si tratta di una sostituzione.
- Se il modello produce “cat sat”, si tratta di una cancellazione.
- Se restituisce “il gatto si è seduto”, si tratta di un'inserzione (inserimento).
Quali sono le applicazioni dell’ASR?
ASR è uno strumento molto utile.
Ha anche contribuito a migliorare la qualità della vita grazie a maggiore sicurezza, accessibilità ed efficienza in settori cruciali.
Sanità
Quando dico ai medici che faccio ricerca sul riconoscimento vocale, rispondono “ah, come Dragon.”
Prima dell’arrivo dell’AI generativa in sanità, i medici prendevano appunti verbali a 30 parole al minuto con un vocabolario limitato.
L’ASR ha avuto un enorme successo nel ridurre il burnout diffuso tra i medici.
I medici devono bilanciare montagne di scartoffie con la necessità di occuparsi dei pazienti. Già nel 2018, i ricercatori sollecitavano l’uso della trascrizione digitale nelle consultazioni per migliorare la capacità dei medici di fornire cure.
Questo perché dover documentare le consulenze a posteriori non solo riduce il tempo a disposizione con i pazienti, ma è anche molto meno accurato rispetto ai riassunti delle trascrizioni delle vere consultazioni.
Case intelligenti
Ho una battuta che faccio spesso.
Quando voglio spegnere la luce ma non ho voglia di alzarmi, batto le mani due volte di seguito — come se avessi un clapper.
Il mio partner non ride mai.
Le case intelligenti attivate dalla voce sembrano sia futuristiche che eccessivamente lussuose. O almeno così pare.
Certo, sono comodi, ma in molti casi rendono possibili cose che altrimenti non sarebbero accessibili.
Un ottimo esempio è il consumo energetico: apportare piccole modifiche a luci e termostato sarebbe impossibile durante la giornata se dovessi alzarti ogni volta per regolare una manopola.
L’attivazione vocale rende più semplici queste piccole modifiche e coglie le sfumature del linguaggio umano.
Ad esempio, dici “puoi renderlo un po’ più fresco?” L’assistente usa l’elaborazione del linguaggio naturale per tradurre la richiesta in una modifica della temperatura, considerando molti altri dati: la temperatura attuale, le previsioni meteo, i dati di utilizzo del termostato di altri utenti, ecc.
Fai la tua parte umana e lascia che il computer si occupi delle cose da computer.
Direi che è molto più semplice che dover indovinare di quanti gradi abbassare il riscaldamento basandoti sulle tue sensazioni.
Ed è anche più efficiente dal punto di vista energetico: ci sono testimonianze di famiglie che hanno ridotto il consumo energetico dell’80% grazie all’illuminazione intelligente attivata dalla voce, solo per fare un esempio.
Customer Support
Ne abbiamo parlato nel settore sanitario, ma la trascrizione e il riassunto sono molto più efficaci rispetto a riassunti retroattivi delle interazioni fatti dalle persone.
Anche in questo caso, fa risparmiare tempo ed è più preciso. Quello che impariamo continuamente è che le automazioni liberano tempo per permettere alle persone di svolgere meglio il proprio lavoro.
E questo è particolarmente vero nell’assistenza clienti, dove il supporto potenziato dall’ASR registra un tasso di risoluzione al primo contatto superiore del 25%.
Trascrizione e sintesi automatizzano il processo di individuazione di una soluzione in base al sentimento e alla richiesta del cliente.
Assistenti in auto
Qui ci appoggiamo agli assistenti domestici, ma vale la pena menzionarli.
Il riconoscimento vocale riduce il carico cognitivo e le distrazioni visive per i conducenti.
E considerando che le distrazioni sono responsabili di fino al 30% degli incidenti, adottare questa tecnologia è una scelta ovvia per la sicurezza.
Logopedia
L’ASR viene utilizzato da tempo come strumento per valutare e trattare le patologie del linguaggio.
È utile ricordare che le macchine non solo automatizzano i compiti, ma fanno anche cose che gli esseri umani non possono fare.
Il riconoscimento vocale può rilevare sfumature nel parlato quasi impercettibili all’orecchio umano, cogliendo dettagli di una pronuncia alterata che altrimenti passerebbero inosservati.
Il futuro dell’ASR
La STT è diventata così affidabile che ormai non ci pensiamo più.
Ma dietro le quinte, i ricercatori stanno lavorando per renderla ancora più potente, accessibile — e meno percepibile.
Ho selezionato alcune tendenze interessanti che sfruttano i progressi nell'ASR, aggiungendo alcune mie considerazioni.
Riconoscimento vocale sul dispositivo
La maggior parte delle soluzioni ASR funziona nel cloud. Sicuramente l’hai già sentito. Significa che il modello gira su un computer remoto, da qualche altra parte.
Lo fanno perché il piccolo processore del tuo telefono non può necessariamente eseguire il loro enorme modello, o ci metterebbe troppo a trascrivere qualsiasi cosa.
Invece, il tuo audio viene inviato, tramite internet, a un server remoto dotato di una GPU troppo pesante da portare in tasca. La GPU esegue il modello ASR e restituisce la trascrizione al tuo dispositivo.
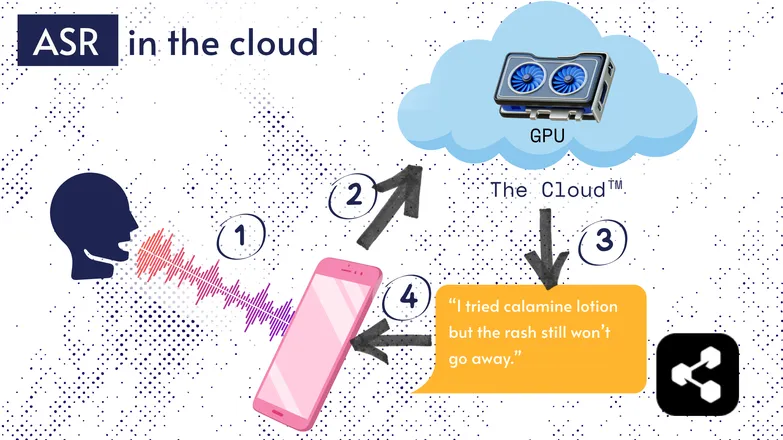
Per motivi di efficienza energetica e sicurezza (non tutti vogliono che i propri dati personali circolino liberamente online), molte ricerche sono state dedicate a rendere i modelli abbastanza compatti da funzionare direttamente sul tuo dispositivo, che sia uno smartphone, un computer o un browser.
Ho scritto una tesi sulla quantizzazione dei modelli ASR per eseguirli on-device. Picovoice è un’azienda canadese che sviluppa IA vocale a bassa latenza su dispositivo, e sembra interessante.
L’ASR on-device rende la trascrizione disponibile a costi inferiori, con il potenziale di servire comunità a basso reddito.
Interfaccia Transcript-First
Il divario tra audio e trascrizioni si sta riducendo. Cosa significa?
I video editor come Premiere Pro e Descript ti permettono di navigare nelle registrazioni tramite la trascrizione: clicca su una parola e vai direttamente al timestamp.
Hai dovuto fare più tentativi? Scegli il tuo preferito ed elimina gli altri, proprio come in un editor di testo. Il video viene tagliato automaticamente per te.
È davvero frustrante fare questo tipo di editing solo con la forma d’onda, ma diventa facilissimo con editor basati su trascrizione.
Allo stesso modo, servizi di messaggistica come WhatsApp stanno trascrivendo i tuoi messaggi vocali e ti permettono di scorrere il testo. Fai scorrere il dito su una parola e verrai portato a quel punto della registrazione.

Curiosità: ho effettivamente creato qualcosa di simile circa una settimana prima che Apple annunciasse una funzione analoga.
Questi esempi mostrano come tecnologie complesse sotto il cofano portino semplicità e intuitività alle applicazioni per l’utente finale.
Equità, Inclusione e Lingue a Basse Risorse
La battaglia non è ancora vinta.
L’ASR funziona molto bene in inglese e in altre lingue comuni e ben supportate. Non è necessariamente così per le lingue meno diffuse.
Esistono lacune per minoranze dialettali, parlato alterato e altre problematiche legate all’equità nella tecnologia vocale.
Scusa se rovino l’entusiasmo. Questa sezione si chiama “futuro” dell’ASR. E scelgo di guardare avanti verso un futuro di cui essere orgogliosi.
Se vogliamo progredire, dobbiamo farlo insieme, altrimenti rischiamo di aumentare le disuguaglianze sociali.
Inizia a usare ASR oggi stesso
Qualunque sia il tuo settore, usare l’ASR è una scelta ovvia — ma probabilmente ti stai chiedendo come iniziare. Come si implementa l’ASR? Come si trasferiscono quei dati ad altri strumenti?
Botpress include schede di trascrizione facili da usare. Possono essere integrate in un flusso drag-and-drop e arricchite con decine di integrazioni tra applicazioni e canali di comunicazione.
Inizia a costruire oggi. È gratis.
Domande frequenti
Quanto è preciso l’ASR moderno con accenti diversi e in ambienti rumorosi?
I sistemi ASR moderni sono molto precisi per gli accenti più comuni nelle principali lingue, raggiungendo tassi di errore inferiori al 10% in condizioni ottimali, ma la precisione diminuisce sensibilmente con accenti marcati, dialetti o molto rumore di fondo. Fornitori come Google e Microsoft addestrano i modelli su dati vocali diversificati, ma la trascrizione perfetta in ambienti rumorosi resta una sfida.
L’ASR è affidabile nella trascrizione di gergo tecnico o termini specifici di settore?
L’ASR è meno affidabile, senza personalizzazioni, per il gergo tecnico o i termini specifici di settore perché i dati di addestramento sono generalmente orientati al linguaggio comune; le parole sconosciute possono essere trascritte male o saltate. Tuttavia, le soluzioni aziendali permettono di aggiungere vocabolari personalizzati, modelli linguistici specifici e dizionari di pronuncia per migliorare il riconoscimento dei termini tecnici in settori come sanità, diritto o ingegneria.
Qual è la differenza tra strumenti ASR gratuiti e soluzioni di livello enterprise?
La differenza tra strumenti ASR gratuiti e soluzioni enterprise sta in accuratezza, scalabilità, personalizzazione e controlli sulla privacy: gli strumenti gratuiti spesso hanno tassi di errore più alti, supporto linguistico limitato e limiti d’uso, mentre le soluzioni enterprise offrono WER più basso, personalizzazione per settore, integrazioni, accordi sul livello di servizio (SLA) e solide funzionalità di sicurezza per la gestione di dati sensibili.
Come protegge l’ASR la privacy degli utenti e le informazioni sensibili durante la trascrizione?
L’ASR protegge la privacy degli utenti tramite crittografia durante la trasmissione dei dati e offre opzioni come l’esecuzione dei modelli sul dispositivo per evitare l’invio dei dati vocali a server esterni. Molti fornitori enterprise rispettano anche normative sulla privacy come GDPR o HIPAA e possono anonimizzare i dati per proteggere le informazioni sensibili.
Quanto sono costosi i servizi ASR cloud rispetto alle soluzioni on-device?
I servizi ASR basati su cloud di solito applicano tariffe per minuto audio o per fasce di utilizzo, con costi che vanno da 0,03 a oltre 1,00 dollari al minuto a seconda della precisione e delle funzionalità, mentre le soluzioni on-device prevedono costi di sviluppo iniziali e licenze.



