



- ASR menukar pertuturan kepada teks menggunakan pembelajaran mesin, membolehkan arahan suara dan transkripsi masa nyata.
- Sistem ASR moden telah beralih daripada model fonem berasingan (HMM-GMM) kepada model pembelajaran mendalam yang meramalkan keseluruhan perkataan.
- Prestasi ASR diukur dengan Kadar Ralat Perkataan (WER), dengan ralat datang daripada penggantian, penghapusan, atau penambahan; WER lebih rendah = kualiti transkripsi lebih baik.
- Masa depan ASR memberi tumpuan kepada pemprosesan dalam peranti untuk privasi dan sokongan untuk bahasa sumber rendah.
Bila kali terakhir anda menonton sesuatu tanpa sari kata?
Dulu ia pilihan, tapi kini ia sentiasa muncul dalam video pendek sama ada kita mahu atau tidak. Sari kata kini begitu sebati dalam kandungan sehingga kita terlupa ia ada di situ.
Pengecaman pertuturan automatik (ASR) — keupayaan untuk menukar perkataan yang dituturkan kepada teks dengan cepat dan tepat secara automatik — ialah teknologi yang mendorong perubahan ini.
Bila kita fikir tentang agen suara AI, kita fikir tentang pilihan perkataannya, cara ia menyampaikan, dan suara yang digunakan.
Tetapi mudah untuk terlupa bahawa kelancaran interaksi kita bergantung pada bot memahami kita. Dan untuk sampai ke tahap ini — bot memahami anda walaupun dengan “um” dan “ah” dalam suasana bising — bukanlah sesuatu yang mudah.
Hari ini, kami akan bincangkan teknologi di sebalik sari kata itu: pengecaman pertuturan automatik (ASR).
Izinkan saya memperkenalkan diri: Saya mempunyai ijazah sarjana dalam teknologi pertuturan, dan pada masa lapang saya suka membaca perkembangan terkini tentang ASR, malah membina sesuatu.
Saya akan terangkan asas ASR, lihat sedikit di sebalik tabir teknologinya, dan cuba ramalkan ke mana arah teknologi ini seterusnya.
Apa itu ASR?
Pengecaman pertuturan automatik (ASR), atau pertuturan-ke-teks (STT) ialah proses menukar pertuturan kepada teks bertulis menggunakan teknologi pembelajaran mesin.
Teknologi yang melibatkan pertuturan selalunya mengintegrasikan ASR dalam pelbagai cara; ia boleh digunakan untuk sari kata video, menyalin interaksi sokongan pelanggan untuk analisis, atau sebahagian daripada interaksi pembantu suara, sebagai contoh.
Algoritma Pertuturan-ke-Teks
Teknologi asasnya telah berubah sepanjang masa, tetapi semua versi terdiri daripada dua komponen dalam satu bentuk atau lain: data dan model.
Dalam konteks ASR, data ialah pertuturan berlabel – fail audio bahasa pertuturan dan transkripsi yang sepadan.
Model ialah algoritma yang digunakan untuk meramalkan transkripsi daripada audio. Data berlabel digunakan untuk melatih model, supaya ia boleh membuat generalisasi pada contoh pertuturan yang belum pernah dilihat.
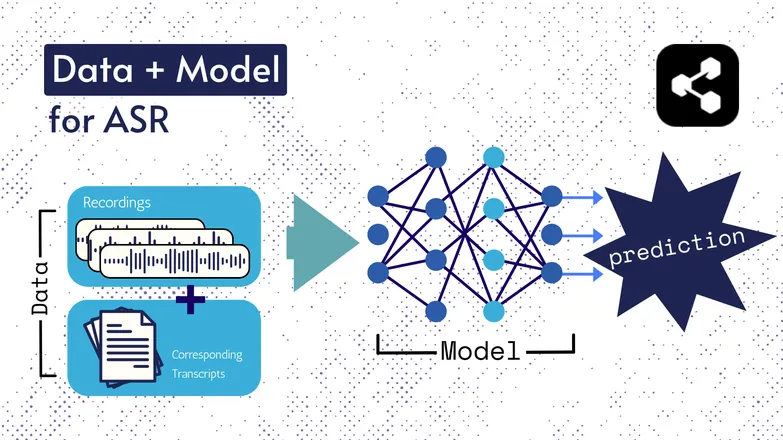
Ia hampir sama seperti bagaimana anda boleh memahami satu siri perkataan, walaupun anda tidak pernah mendengarnya dalam susunan tertentu, atau ia dituturkan oleh orang asing.
Sekali lagi, jenis model dan butirannya telah berubah dari masa ke masa, dan semua kemajuan dari segi kelajuan dan ketepatan bergantung pada saiz dan spesifikasi set data serta model.
Sisipan Ringkas: Pengekstrakan Ciri
Saya pernah bincangkan tentang ciri, atau representasi dalam artikel saya mengenai teks-ke-pertuturan. Ia digunakan dalam model ASR dahulu dan sekarang.
Pengekstrakan ciri — menukar pertuturan kepada ciri — ialah langkah pertama dalam hampir semua proses ASR.
Ringkasnya, ciri ini, selalunya spektrogram, adalah hasil pengiraan matematik ke atas pertuturan, dan menukar pertuturan kepada format yang menekankan persamaan dalam satu ujaran, dan meminimumkan perbezaan antara penutur.
Maksudnya, ujaran yang sama dituturkan oleh 2 penutur berbeza akan menghasilkan spektrogram yang serupa, walaupun suara mereka berbeza.
Saya sebutkan ini supaya anda tahu bahawa saya akan bercakap tentang model “meramalkan transkripsi daripada pertuturan”. Sebenarnya, model meramalkan daripada ciri. Tetapi anda boleh anggap komponen pengekstrakan ciri sebagai sebahagian daripada model.
ASR Awal: HMM-GMM
Model markov tersembunyi (HMM) dan model campuran Gaussian (GMM) ialah model ramalan sebelum rangkaian neural mendalam mengambil alih.
HMM menguasai ASR sehingga baru-baru ini.
Diberikan satu fail audio, HMM akan meramalkan tempoh fonem, dan GMM akan meramalkan fonem itu sendiri.
Kedengaran seperti terbalik, dan memang agak begitu, contohnya:
- HMM: “0.2 saat pertama ialah satu fonem.”
- GMM: “Fonem itu ialah G, seperti dalam Gary.”
Menukar klip audio kepada teks memerlukan beberapa komponen tambahan, iaitu:
- Kamus sebutan: senarai lengkap perkataan dalam perbendaharaan kata, bersama sebutan masing-masing.
- Model bahasa: Gabungan perkataan dalam perbendaharaan kata, dan kebarangkalian ia muncul bersama.
Jadi walaupun GMM meramalkan /f/ berbanding /s/, model bahasa tahu lebih besar kemungkinan penutur berkata “a penny for your thoughts”, bukan foughts.
Kita ada semua bahagian ini kerana, terus terang, tiada satu pun bahagian dalam proses ini yang benar-benar bagus.
HMM akan salah meramalkan penjajaran, GMM akan keliru antara bunyi yang serupa: /s/ dan /f/, /p/ dan /t/, dan jangan sebut tentang vokal.
Kemudian model bahasa akan membetulkan kekeliruan fonem menjadi sesuatu yang lebih menyerupai bahasa.
ASR Hujung-ke-Hujung dengan Pembelajaran Mendalam
Banyak bahagian dalam proses ASR kini telah digabungkan.
Kini, daripada melatih model berasingan untuk ejaan, penjajaran, dan sebutan, satu model sahaja menerima pertuturan dan mengeluarkan (diharapkan) perkataan yang dieja dengan betul, dan kini juga, cap masa.
(Walaupun pelaksanaan sering membetulkan, atau “menilai semula” output ini dengan model bahasa tambahan.)
Ini tidak bermakna faktor berbeza — seperti penjajaran dan ejaan — tidak diberi perhatian khusus. Masih banyak kajian tertumpu kepada penyelesaian isu-isu yang sangat khusus.
Maksudnya, penyelidik mencari cara untuk mengubah seni bina model bagi menangani faktor prestasi tertentu, seperti:
- Penyahkod RNN-Transducer yang bergantung pada output sebelumnya untuk memperbaiki ejaan.
- Pensampelan konvolusi untuk menghadkan output kosong, memperbaiki penjajaran.
Saya tahu ini kedengaran mengarut. Saya cuma mendahului bos saya yang mungkin akan tanya “boleh beri contoh mudah?”
Jawapannya tidak.
Tidak boleh.
Bagaimana Prestasi ASR Diukur?
Bila ASR gagal, anda memang perasan.
Saya pernah lihat caramelization ditranskripsi sebagai communist Asians. Crispiness jadi Chris p — anda faham maksudnya.
Metod yang digunakan untuk mengukur ralat secara matematik ialah kadar ralat perkataan (WER). Formula WER ialah:
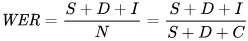
Di mana:
- S ialah bilangan penggantian (perkataan yang diubah dalam teks ramalan untuk sepadan dengan teks rujukan)
- D ialah bilangan penghapusan (perkataan yang tiada dalam output, berbanding teks rujukan)
- I ialah bilangan penambahan (perkataan tambahan dalam output, berbanding teks rujukan)
- N ialah jumlah keseluruhan perkataan dalam teks rujukan
Sebagai contoh, jika teks rujukan ialah “the cat sat.”
- Jika model mengeluarkan “the cat sank”, itu ialah penggantian.
- Jika model mengeluarkan “cat sat”, itu ialah penghapusan.
- Jika ia mengeluarkan “the cat has sat”, itu ialah penambahan.
Apakah Aplikasi ASR?
ASR ialah alat yang berguna.
Ia juga membantu meningkatkan kualiti hidup kita melalui keselamatan, kebolehcapaian, dan kecekapan yang lebih baik dalam industri penting.
Penjagaan Kesihatan
Bila saya beritahu doktor bahawa saya buat penyelidikan tentang pengecaman pertuturan, mereka akan kata “oh, macam Dragon.”
Sebelum adanya AI generatif dalam penjagaan kesihatan, doktor mencatat nota secara lisan pada kadar 30 perkataan seminit dengan perbendaharaan kata yang terhad.
ASR telah sangat berjaya mengurangkan keletihan melampau yang dialami oleh doktor.
Doktor perlu mengimbangi timbunan kerja kertas dengan keperluan untuk melayani pesakit mereka. Seawal tahun 2018, penyelidik telah memohon penggunaan transkripsi digital dalam konsultasi untuk meningkatkan keupayaan doktor memberikan rawatan.
Ini kerana mendokumentasikan konsultasi secara retroaktif bukan sahaja mengurangkan masa bersama pesakit, malah ia juga jauh kurang tepat berbanding ringkasan transkripsi konsultasi sebenar.
Rumah Pintar
Saya ada satu jenaka yang selalu saya buat.
Bila saya mahu tutup lampu tapi malas nak bangun, saya tepuk tangan dua kali dengan cepat — seolah-olah saya ada alat tepuk tangan automatik.
Pasangan saya tak pernah ketawa.
Rumah pintar yang diaktifkan suara terasa seperti masa depan dan pada masa yang sama agak berlebihan. Atau begitulah nampaknya.
Memang, ia memudahkan, tetapi dalam banyak kes ia membolehkan perkara yang sebelum ini tidak dapat dilakukan.
Contoh yang baik ialah penggunaan tenaga: membuat pelarasan kecil pada lampu dan termostat akan menjadi tidak praktikal jika anda perlu bangun dan melarasnya sepanjang hari.
Aktivasi suara bermakna pelarasan kecil ini bukan sahaja lebih mudah, malah ia memahami nuansa percakapan manusia.
Sebagai contoh, anda berkata "boleh sejukkan sedikit?" Pembantu akan menggunakan pemprosesan bahasa semula jadi untuk menterjemahkan permintaan anda kepada perubahan suhu, dengan mengambil kira pelbagai data lain: suhu semasa, ramalan cuaca, data penggunaan termostat pengguna lain, dan sebagainya.
Anda lakukan bahagian manusia, dan biarkan bahagian komputer diuruskan oleh komputer.
Saya rasa itu jauh lebih mudah daripada anda perlu teka berapa darjah nak turunkan suhu berdasarkan rasa anda.
Dan ia juga lebih cekap tenaga: terdapat laporan keluarga mengurangkan penggunaan tenaga sehingga 80% dengan pencahayaan pintar yang diaktifkan suara, sebagai contoh.
Sokongan Pelanggan
Kita sudah bincangkan ini dalam penjagaan kesihatan, tetapi transkripsi dan ringkasan jauh lebih berkesan daripada orang membuat ringkasan selepas interaksi.
Sekali lagi, ia menjimatkan masa dan lebih tepat. Apa yang kita pelajari berulang kali ialah automasi membebaskan masa supaya orang boleh melakukan kerja mereka dengan lebih baik.
Dan ini paling ketara dalam sokongan pelanggan, di mana sokongan pelanggan yang dipertingkatkan ASR mempunyai kadar penyelesaian panggilan pertama 25% lebih tinggi.
Transkripsi dan ringkasan membantu mengautomasikan proses mencari penyelesaian berdasarkan sentimen dan pertanyaan pelanggan.
Pembantu Dalam Kereta
Kita menumpang contoh daripada pembantu rumah pintar di sini, tetapi ia memang patut disebut.
Pengecaman suara mengurangkan beban kognitif dan gangguan visual untuk pemandu.
Dan dengan gangguan menyumbang kepada sehingga 30% perlanggaran, penggunaan teknologi ini jelas penting untuk keselamatan.
Patologi Pertuturan
ASR telah lama digunakan sebagai alat untuk menilai dan merawat patologi pertuturan.
Penting untuk diingat bahawa mesin bukan sekadar mengautomasikan tugas, ia juga melakukan perkara yang manusia tak mampu.
Pengecaman pertuturan boleh mengesan kehalusan dalam pertuturan yang hampir tidak dapat didengar oleh telinga manusia, menangkap butiran pertuturan yang terjejas yang mungkin terlepas pandang.
Masa Depan ASR
STT kini sudah cukup baik sehingga kita jarang memikirkannya lagi.
Tetapi di belakang tabir, penyelidik masih berusaha keras untuk menjadikannya lebih berkuasa dan mudah diakses — dan kurang ketara.
Saya pilih beberapa trend menarik yang memanfaatkan kemajuan dalam ASR, dan selitkan juga pandangan saya sendiri.
Pengecaman Suara Dalam Peranti
Kebanyakan penyelesaian ASR dijalankan di awan. Saya pasti anda pernah dengar sebelum ini. Maksudnya model dijalankan pada komputer jauh, di tempat lain.
Mereka lakukan ini kerana pemproses kecil pada telefon anda mungkin tidak mampu menjalankan model besar mereka, atau ia akan mengambil masa yang lama untuk transkripsi apa-apa.
Sebaliknya, audio anda dihantar melalui internet ke pelayan jauh yang menjalankan GPU yang terlalu berat untuk dibawa ke mana-mana. GPU menjalankan model ASR, dan menghantar kembali transkripsi ke peranti anda.
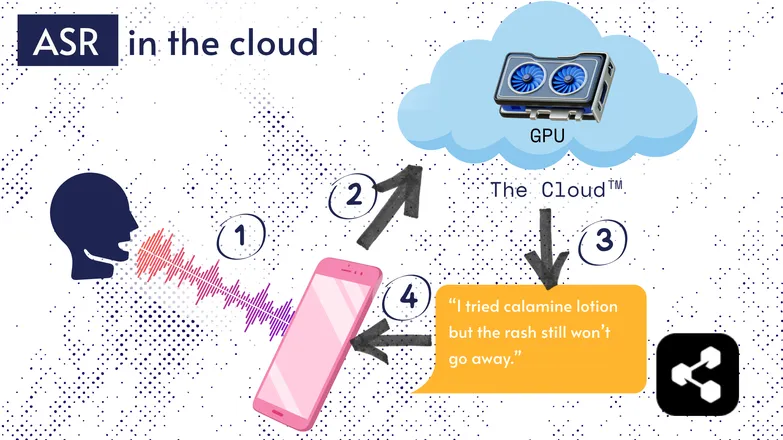
Atas sebab kecekapan tenaga dan keselamatan (tidak semua orang mahu data peribadi mereka tersebar di internet), banyak penyelidikan telah dijalankan untuk menjadikan model cukup padat supaya boleh dijalankan terus pada peranti anda, sama ada telefon, komputer, atau enjin pelayar.
Saya sendiri pernah menulis tesis tentang kuantisasi model ASR supaya ia boleh dijalankan pada peranti. Picovoice ialah syarikat Kanada yang membina AI suara dalam peranti dengan latensi rendah, dan mereka nampak menarik.
ASR dalam peranti membolehkan transkripsi tersedia dengan kos lebih rendah, berpotensi memberi manfaat kepada komuniti berpendapatan rendah.
Antara Muka Transkrip-Dahulu
Jurang antara audio dan transkripsi semakin mengecil. Apa maksudnya?
Penyunting video seperti Premiere Pro dan Descript membolehkan anda menavigasi rakaman anda melalui transkrip: klik pada perkataan dan ia membawa anda ke cap masa.
Perlu buat beberapa rakaman? Pilih yang paling anda suka dan padamkan yang lain, seperti dalam penyunting teks. Ia akan memangkas video anda secara automatik untuk anda.
Sangat menyusahkan untuk menyunting dengan hanya gelombang audio, tetapi sangat mudah apabila anda menggunakan penyunting berasaskan transkrip.
Begitu juga, perkhidmatan mesej seperti WhatsApp kini menyalin nota suara anda dan membolehkan anda melayari rakaman tersebut melalui teks. Leret jari pada perkataan, anda akan dibawa ke bahagian rakaman itu.

Cerita lucu: Saya sebenarnya pernah bina sesuatu seperti ini kira-kira seminggu sebelum Apple mengumumkan ciri yang serupa.
Contoh-contoh ini menunjukkan bagaimana teknologi kompleks di belakang tabir membawa kesederhanaan dan kemudahan kepada aplikasi pengguna akhir.
Kesaksamaan, Inklusi, dan Bahasa Sumber Rendah
Perjuangan masih belum selesai.
ASR berfungsi dengan baik dalam bahasa Inggeris dan bahasa utama lain yang mempunyai sumber mencukupi. Itu tidak semestinya berlaku untuk bahasa sumber rendah.
Terdapat jurang untuk minoriti dialek, pertuturan terjejas, dan isu lain berkaitan kesaksamaan dalam teknologi suara.
Maaf jika merosakkan suasana. Bahagian ini dipanggil "masa depan" ASR. Dan saya memilih untuk menantikan masa depan yang boleh kita banggakan.
Jika kita mahu maju, kita harus lakukannya bersama, atau berisiko meningkatkan ketidaksamaan masyarakat.
Mula Guna ASR Hari Ini
Tak kira jenis perniagaan anda, menggunakan ASR memang pilihan bijak — cuma anda mungkin tertanya-tanya bagaimana untuk bermula. Bagaimana nak laksanakan ASR? Bagaimana nak salurkan data itu ke alat lain?
Botpress disertakan dengan kad transkripsi yang mudah digunakan. Ia boleh diintegrasikan ke dalam aliran seret dan lepas, serta diperkaya dengan puluhan integrasi merentasi aplikasi dan saluran komunikasi.
Mula bina hari ini. Ia percuma.
Soalan Lazim
Sejauh mana ketepatan ASR moden untuk pelbagai loghat dan persekitaran bising?
Sistem ASR moden sangat tepat untuk loghat biasa dalam bahasa utama, dengan kadar ralat perkataan (WER) di bawah 10% dalam keadaan bersih, tetapi ketepatan menurun dengan loghat berat, dialek, atau bunyi latar yang ketara. Penyedia seperti Google dan Microsoft melatih model mereka dengan data pertuturan yang pelbagai, namun transkripsi sempurna dalam persekitaran bising masih menjadi cabaran.
Adakah ASR boleh dipercayai untuk menyalin jargon khusus atau istilah industri?
ASR kurang boleh dipercayai secara lalai untuk jargon khusus atau istilah industri kerana data latihannya biasanya lebih kepada pertuturan umum; perkataan yang tidak dikenali boleh disalin salah atau tertinggal. Namun, penyelesaian perusahaan membenarkan penggunaan perbendaharaan kata khusus, model bahasa mengikut domain, dan kamus sebutan untuk meningkatkan pengecaman istilah teknikal dalam bidang seperti penjagaan kesihatan, undang-undang, atau kejuruteraan.
Apakah perbezaan antara alat ASR percuma dan penyelesaian peringkat perusahaan?
Perbezaan antara alat ASR percuma dan penyelesaian peringkat perusahaan terletak pada ketepatan, kebolehskalaan, penyesuaian, dan kawalan privasi: alat percuma selalunya mempunyai kadar ralat lebih tinggi, sokongan bahasa terhad, dan had penggunaan, manakala penyelesaian perusahaan menawarkan WER lebih rendah, penyesuaian khusus domain, integrasi, perjanjian tahap perkhidmatan (SLA), dan ciri keselamatan kukuh untuk pengendalian data sensitif.
Bagaimana ASR melindungi privasi pengguna dan maklumat sensitif semasa transkripsi?
ASR melindungi privasi pengguna melalui penyulitan semasa penghantaran data dan menawarkan pilihan seperti menjalankan model di peranti untuk mengelakkan penghantaran data suara ke pelayan luar. Kebanyakan penyedia perusahaan juga mematuhi peraturan privasi seperti GDPR atau HIPAA dan boleh menganonimkan data untuk melindungi maklumat sensitif.
Sejauh mana mahalnya perkhidmatan ASR berasaskan awan berbanding penyelesaian di peranti?
Perkhidmatan ASR berasaskan awan biasanya mengenakan caj mengikut minit audio atau per peringkat penggunaan, dengan kos antara $0.03–$1.00+ seminit bergantung pada ketepatan dan ciri, manakala penyelesaian pada peranti melibatkan kos pembangunan awal dan yuran pelesenan.



