



- ASR แปลงเสียงพูดเป็นข้อความด้วยการเรียนรู้ของเครื่อง ทำให้สั่งงานด้วยเสียงและถอดความแบบเรียลไทม์เป็นไปได้
- ระบบ ASR สมัยใหม่เปลี่ยนจากโมเดลโฟนีมแยกส่วน (HMM-GMM) มาเป็นโมเดลดีปเลิร์นนิ่งที่ทำนายคำทั้งคำ
- ประสิทธิภาพของ ASR วัดด้วยอัตราความผิดพลาดของคำ (WER) ซึ่งเกิดจากการแทนที่ การลบ หรือการแทรกคำ; WER ยิ่งต่ำ คุณภาพการถอดความยิ่งดี
- อนาคตของ ASR มุ่งเน้นไปที่การประมวลผลบนอุปกรณ์เพื่อความเป็นส่วนตัว และรองรับภาษาทรัพยากรต่ำ
คุณดูอะไรโดยไม่เปิดซับไตเติลครั้งสุดท้ายเมื่อไหร่?
เมื่อก่อนซับไตเติลเป็นตัวเลือก แต่ตอนนี้มันโผล่ในวิดีโอสั้นแทบทุกคลิปโดยที่เราไม่ทันสังเกต ซับไตเติลฝังแน่นในเนื้อหาจนบางทีเราลืมไปว่ามีอยู่
การรู้จำเสียงพูดอัตโนมัติ (ASR) — ความสามารถในการแปลงคำพูดเป็นข้อความอย่างรวดเร็วและแม่นยำโดยอัตโนมัติ — คือเทคโนโลยีที่อยู่เบื้องหลังการเปลี่ยนแปลงนี้
เมื่อเรานึกถึง เอเจนต์เสียง AI เราจะคิดถึงการเลือกใช้คำ น้ำเสียง และเสียงที่มันพูดออกมา
แต่สิ่งที่มักถูกลืมคือ ความลื่นไหลของการโต้ตอบขึ้นอยู่กับว่าบอทเข้าใจเราหรือไม่ และกว่าจะมาถึงจุดที่บอทเข้าใจคุณ แม้จะมีเสียง “เอ่อ” หรือ “อ่า” ในสภาพแวดล้อมที่มีเสียงรบกวน ก็ไม่ใช่เรื่องง่ายเลย
วันนี้เราจะพูดถึงเทคโนโลยีที่อยู่เบื้องหลังซับไตเติลเหล่านั้น: การรู้จำเสียงพูดอัตโนมัติ (ASR)
ขอแนะนำตัวเองหน่อย: ผมมีปริญญาโทด้านเทคโนโลยีเสียงพูด และเวลาว่างก็ชอบอ่านเรื่องใหม่ ๆ เกี่ยวกับ ASR หรือแม้แต่ ลงมือสร้างอะไรเอง
ผมจะอธิบายพื้นฐานของ ASR พาไปดูเทคโนโลยีข้างใน และลองคาดเดาว่าเทคโนโลยีนี้จะไปทางไหนต่อ
ASR คืออะไร?
การรู้จำเสียงพูดอัตโนมัติ (ASR) หรือ speech-to-text (STT) คือกระบวนการแปลงเสียงพูดเป็นข้อความด้วยเทคโนโลยีการเรียนรู้ของเครื่อง
เทคโนโลยีที่เกี่ยวข้องกับเสียงพูดมักจะผสาน ASR เข้าไปในบางส่วน เช่น การสร้างซับไตเติลวิดีโอ การถอดเสียงสนทนาลูกค้าเพื่อวิเคราะห์ หรือเป็นส่วนหนึ่งของ ผู้ช่วยเสียง เป็นต้น
อัลกอริทึม Speech-to-Text
เทคโนโลยีเบื้องหลังเปลี่ยนแปลงมาตลอดหลายปี แต่ทุกรุ่นล้วนประกอบด้วยสองส่วนหลัก ๆ คือ ข้อมูล และ โมเดล
สำหรับ ASR ข้อมูลคือเสียงพูดที่มีการระบุป้ายกำกับ – ไฟล์เสียงพร้อมข้อความถอดความที่ตรงกัน
โมเดลคืออัลกอริทึมที่ใช้ทำนายข้อความถอดความจากเสียง โดยข้อมูลที่มีป้ายกำกับจะใช้ฝึกโมเดล เพื่อให้สามารถประมวลผลเสียงที่ไม่เคยเห็นมาก่อนได้
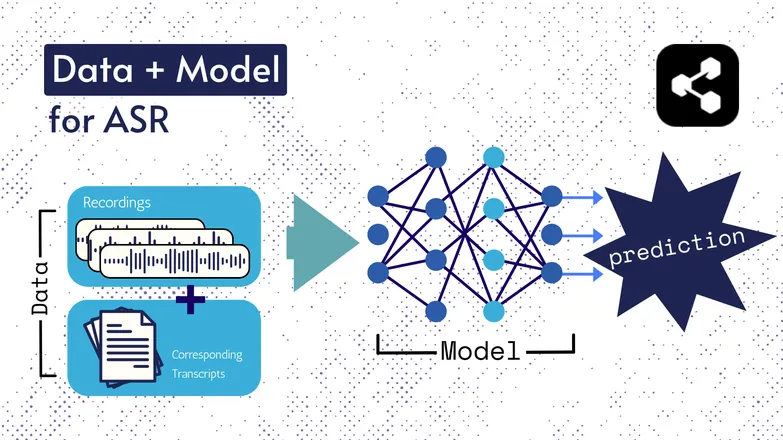
มันคล้ายกับที่คุณเข้าใจชุดคำ แม้ไม่เคยได้ยินคำนั้นเรียงกันมาก่อน หรือพูดโดยคนแปลกหน้า
อีกครั้ง ประเภทของโมเดลและรายละเอียดเปลี่ยนไปตามยุค และความก้าวหน้าด้านความเร็วและความแม่นยำก็ขึ้นอยู่กับขนาดและคุณสมบัติของชุดข้อมูลและโมเดล
เกร็ดเล็กน้อย: การสกัดคุณลักษณะ
ผมเคยพูดถึง คุณลักษณะ หรือการแทนค่า ในบทความเรื่อง text-to-speech ซึ่งใช้ในโมเดล ASR ทั้งอดีตและปัจจุบัน
การสกัดคุณลักษณะ — การแปลงเสียงพูดเป็นคุณลักษณะ — เป็นขั้นตอนแรกของแทบทุกกระบวนการ ASR
สรุปคือ คุณลักษณะเหล่านี้ มักจะเป็น สเปกโตรแกรม เกิดจากการคำนวณทางคณิตศาสตร์กับเสียงพูด และ แปลงเสียงพูดให้อยู่ในรูปแบบที่เน้นความคล้ายคลึงกันของคำพูด และลดความแตกต่างระหว่างผู้พูด
เช่นเดียวกับที่คำพูดเดียวกันที่พูดโดยคนสองคนจะมีสเปกโตรแกรมที่คล้ายกัน แม้เสียงของทั้งสองจะต่างกันมาก
ที่ผมเน้นเรื่องนี้เพราะจะพูดถึงโมเดลที่ “ทำนายข้อความถอดความจากเสียง” ซึ่งจริง ๆ แล้วโมเดลทำนายจาก คุณลักษณะ แต่คุณอาจนึกถึงการสกัดคุณลักษณะเป็นส่วนหนึ่งของโมเดลก็ได้
ASR ยุคแรก: HMM-GMM
Hidden markov models (HMMs) และ Gaussian mixture models (GMMs) คือโมเดลทำนายยุคก่อนที่ ดีปนิวรัลเน็ตเวิร์ก จะเข้ามาแทนที่
HMMs เคยเป็นเทคโนโลยีหลักของ ASR จนไม่นานมานี้
เมื่อได้ไฟล์เสียง HMM จะทำนายระยะเวลาของโฟนีม ส่วน GMM จะทำนายว่าเป็นโฟนีมอะไร
ฟังดูเหมือนสลับกัน และก็จริงประมาณนั้น เช่นว่า:
- HMM: “0.2 วินาทีแรกคือโฟนีมหนึ่งตัว”
- GMM: “โฟนีมนั้นคือ G เหมือนในคำว่า Gary”
การแปลงคลิปเสียงเป็นข้อความต้องมีส่วนประกอบเพิ่มเติมอีก เช่น:
- พจนานุกรมการออกเสียง: รายการคำในคลังศัพท์พร้อมการออกเสียงแต่ละคำ
- โมเดลภาษา: การจับคู่คำในคลังศัพท์และความน่าจะเป็นที่คำเหล่านั้นจะปรากฏร่วมกัน
ดังนั้น แม้ GMM จะทำนาย /f/ แทน /s/ โมเดลภาษาก็รู้ว่าผู้พูดน่าจะพูดว่า “a penny for your thoughts” ไม่ใช่ foughts
เราต้องมีส่วนประกอบเหล่านี้ เพราะพูดตรง ๆ ก็คือ ไม่มีส่วนไหนของกระบวนการนี้ที่ดีเป็นพิเศษ
HMM มักทำนายตำแหน่งผิด GMM ก็แยกเสียงที่คล้ายกันไม่ออก เช่น /s/ กับ /f/, /p/ กับ /t/ และอย่าให้พูดถึงสระเลย
แล้วโมเดลภาษาก็จะมาช่วยแก้ไขโฟนีมที่ไม่ปะติดปะต่อให้กลายเป็นภาษาที่อ่านรู้เรื่อง
ASR แบบ End-to-End ด้วย Deep Learning
หลายส่วนในกระบวนการ ASR ถูกผนวกรวมเข้าด้วยกันแล้ว
แทนที่จะฝึกโมเดลแยกกันสำหรับการสะกด การจัดตำแหน่ง และการออกเสียง ตอนนี้ใช้โมเดลเดียวรับเสียงเข้าและให้ผลลัพธ์เป็นคำที่สะกดถูกต้อง (หรือควรจะเป็น) และปัจจุบันยังมีการระบุเวลาประกอบด้วย
(แม้ว่าการใช้งานจริงมักจะมีการตรวจสอบหรือ “รีสกอร์” ผลลัพธ์นี้ด้วยโมเดลภาษาเพิ่มเติม)
แต่ก็ไม่ได้หมายความว่าปัจจัยต่าง ๆ เช่น การจัดตำแหน่งและการสะกด จะไม่ได้รับความสนใจเฉพาะด้าน ยังมีงานวิจัยจำนวนมากที่มุ่งแก้ไขปัญหาเฉพาะจุดเหล่านี้
เช่น นักวิจัยคิดค้นวิธีปรับโครงสร้างโมเดลเพื่อเน้นปัจจัยเฉพาะของประสิทธิภาพ เช่น:
- ดีโคเดอร์ RNN-Transducer ที่อิงกับผลลัพธ์ก่อนหน้าเพื่อปรับปรุงการสะกดคำ
- การลดขนาดข้อมูลด้วยคอนโวลูชันเพื่อลดผลลัพธ์ว่างเปล่า ทำให้การจัดตำแหน่งดีขึ้น
ผมรู้ว่ามันฟังดูงง ๆ แค่อธิบายล่วงหน้าเผื่อหัวหน้าจะถามว่า “ขอยกตัวอย่างง่าย ๆ ได้ไหม?”
คำตอบคือไม่ได้
ไม่ได้จริง ๆ
วัดประสิทธิภาพ ASR อย่างไร?
ถ้า ASR ทำงานแย่ คุณจะรู้ได้ทันที
ผมเคยเห็น caramelization ถูกถอดเสียงเป็น communist Asians หรือ Crispiness กลายเป็น Chris p — คุณคงเข้าใจแล้ว
ตัวชี้วัดที่ใช้สะท้อนข้อผิดพลาดในเชิงคณิตศาสตร์คือ word error rate (WER) สูตรของ WER คือ:
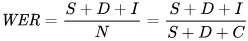
โดยที่:
- S คือจำนวน การแทนที่ (คำที่เปลี่ยนในข้อความที่ทำนายเพื่อให้ตรงกับข้อความอ้างอิง)
- D คือจำนวน การลบ (คำที่หายไปจากผลลัพธ์เมื่อเทียบกับข้อความอ้างอิง)
- I คือจำนวน การแทรก (คำที่เพิ่มเข้ามาในผลลัพธ์เมื่อเทียบกับข้อความอ้างอิง)
- N คือจำนวนคำทั้งหมดในข้อความอ้างอิง
เช่น ถ้าข้อความอ้างอิงคือ “the cat sat.”
- ถ้าโมเดลให้ผลลัพธ์ว่า “the cat sank” นั่นคือการแทนที่
- ถ้าโมเดลให้ผลลัพธ์ว่า “cat sat” นั่นคือการลบ
- ถ้าโมเดลให้ผลลัพธ์ว่า “the cat has sat” นั่นคือการแทรก
ASR ใช้ทำอะไรได้บ้าง?
ASR เป็นเครื่องมือที่มีประโยชน์มาก
มันยังช่วยยกระดับคุณภาพชีวิตของเรา ทั้งด้านความปลอดภัย การเข้าถึง และประสิทธิภาพในอุตสาหกรรมสำคัญ ๆ
สุขภาพ
เวลาผมบอกหมอว่าผมวิจัยเรื่องการรู้จำเสียงพูด เขามักจะพูดว่า “อ๋อ แบบ Dragon ใช่ไหม”
ก่อนที่เราจะมี AI เชิงสร้างสรรค์ในวงการสาธารณสุข แพทย์ต้องจดบันทึกด้วยวาจาที่ความเร็ว 30 คำต่อนาที ด้วยคำศัพท์ที่จำกัด
ASR ประสบความสำเร็จอย่างมากในการช่วยลดภาวะหมดไฟที่แพทย์ต้องเผชิญ
แพทย์ต้องรับมือกับเอกสารจำนวนมหาศาลควบคู่กับการดูแลผู้ป่วย ตั้งแต่ปี 2018 นักวิจัยได้ เรียกร้องให้ใช้การถอดเสียงดิจิทัล ในการปรึกษา เพื่อช่วยให้แพทย์ดูแลผู้ป่วยได้ดีขึ้น
เพราะการต้องบันทึกการปรึกษาย้อนหลัง ไม่เพียงแต่ทำให้เสียเวลาอยู่กับผู้ป่วยน้อยลง แต่ยังแม่นยำน้อยกว่าการสรุปจากการถอดเสียงของการสนทนาจริงมาก
บ้านอัจฉริยะ
ผมมีมุกตลกอันหนึ่ง
เวลาผมอยากปิดไฟแต่ไม่อยากลุก ผมจะตบมือสองครั้งติดกัน เหมือนกับมีเครื่องปิดไฟอัตโนมัติ
แฟนผมไม่เคยขำเลย
บ้านอัจฉริยะที่สั่งงานด้วยเสียงดูเหมือนจะล้ำยุคและฟุ่มเฟือยเกินไป หรืออย่างน้อยก็รู้สึกแบบนั้น
แน่นอนว่ามันสะดวก แต่ในหลายกรณี มันทำให้เราทำสิ่งที่ปกติทำไม่ได้
ตัวอย่างที่ดีคือการใช้พลังงาน: การปรับแสงหรืออุณหภูมิเล็กน้อยตลอดวันคงเป็นไปไม่ได้ถ้าต้องลุกไปหมุนปุ่มเองทุกครั้ง
การสั่งงานด้วยเสียงทำให้การปรับเล็กๆ น้อยๆ เหล่านี้ง่ายขึ้น และยังเข้าใจความละเอียดอ่อนของภาษามนุษย์ด้วย
เช่น ถ้าคุณพูดว่า “ช่วยปรับให้เย็นลงอีกนิดได้ไหม” ผู้ช่วยจะใช้ การประมวลผลภาษาธรรมชาติ แปลคำขอของคุณเป็นการเปลี่ยนอุณหภูมิ โดยคำนึงถึงข้อมูลอื่นๆ เช่น อุณหภูมิปัจจุบัน พยากรณ์อากาศ ข้อมูลการใช้เทอร์โมสแตทของผู้ใช้อื่น ฯลฯ
คุณทำในส่วนของมนุษย์ แล้วปล่อยให้คอมพิวเตอร์จัดการเรื่องเทคนิค
ผมว่าแบบนี้ง่ายกว่าที่คุณต้องเดาเองว่าจะลดอุณหภูมิกี่องศาตามความรู้สึก
และยังประหยัดพลังงานมากขึ้นด้วย: มีรายงานว่าครอบครัวบางครอบครัว ลดการใช้พลังงานได้ถึง 80% ด้วยระบบไฟอัจฉริยะที่สั่งงานด้วยเสียง เช่นในตัวอย่างนี้
บริการลูกค้า
เราได้พูดถึงเรื่องนี้ในวงการสาธารณสุขแล้ว แต่การถอดเสียงและสรุปผลมีประสิทธิภาพกว่าการให้คนมาสรุปย้อนหลังมาก
อีกครั้ง มันช่วยประหยัดเวลาและแม่นยำกว่า สิ่งที่เราเรียนรู้ซ้ำแล้วซ้ำอีกคือระบบอัตโนมัติช่วยให้คนทำงานได้ดีขึ้น
และไม่มีที่ไหนที่เรื่องนี้จะจริงไปกว่าการบริการลูกค้า ซึ่งการสนับสนุนลูกค้าที่ใช้ ASR มีอัตราการแก้ไขปัญหาได้ในการโทรครั้งแรกสูงขึ้น 25%
การถอดเสียงและสรุปผลช่วยให้กระบวนการหาทางแก้ไขตามความรู้สึกและคำถามของลูกค้าเป็นไปโดยอัตโนมัติ
ผู้ช่วยในรถยนต์
เราต่อยอดจากผู้ช่วยในบ้าน แต่นี่ก็ควรพูดถึง
การรู้จำเสียงช่วยลดภาระทางสมองและสิ่งรบกวนสายตาสำหรับผู้ขับขี่
และเมื่อสิ่งรบกวนเป็นสาเหตุของ การชนกันสูงถึง 30% การนำเทคโนโลยีนี้มาใช้จึงเป็นเรื่องที่ควรทำเพื่อความปลอดภัย
พยาธิวิทยาด้านการพูด
ASR ถูกใช้มานานแล้วในฐานะ เครื่องมือประเมินและรักษาความผิดปกติด้านการพูด
อย่าลืมว่าคอมพิวเตอร์ไม่ได้แค่ทำงานแทนมนุษย์ แต่ยังทำสิ่งที่มนุษย์ทำไม่ได้ด้วย
การรู้จำเสียงสามารถจับความละเอียดอ่อนของเสียงพูดที่หูมนุษย์แทบแยกไม่ออก ตรวจพบลักษณะเฉพาะของเสียงที่ผิดปกติซึ่งอาจมองข้ามไป
อนาคตของ ASR
STT พัฒนาจนดีมากจนเราแทบไม่รู้สึกถึงมันแล้ว
แต่เบื้องหลัง นักวิจัยยังคงทำงานอย่างหนักเพื่อให้มันทรงพลังและเข้าถึงง่ายยิ่งขึ้น — และสังเกตได้น้อยลง
ผมเลือกแนวโน้มที่น่าตื่นเต้นบางอย่างที่ใช้ประโยชน์จากความก้าวหน้าใน ASR พร้อมแทรกความเห็นของตัวเองไว้บ้าง
การรู้จำเสียงบนอุปกรณ์
ASR ส่วนใหญ่ทำงานบนคลาวด์ คุณคงเคยได้ยินมาแล้ว นั่นหมายถึง โมเดลทำงานบนคอมพิวเตอร์ระยะไกล ที่อื่น
พวกเขาทำแบบนี้เพราะตัวประมวลผลในโทรศัพท์ของคุณอาจไม่สามารถรันโมเดลขนาดใหญ่ของพวกเขาได้ หรืออาจใช้เวลานานมากในการถอดเสียง
ดังนั้นเสียงของคุณจึงถูกส่งผ่านอินเทอร์เน็ตไปยังเซิร์ฟเวอร์ระยะไกลที่มี GPU ขนาดใหญ่เกินกว่าจะพกใส่กระเป๋าได้ GPU จะรันโมเดล ASR แล้วส่งผลถอดเสียงกลับมายังอุปกรณ์ของคุณ
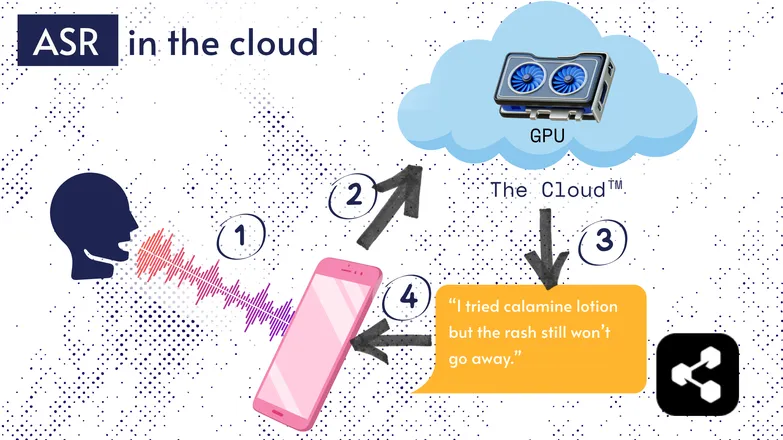
ด้วยเหตุผลด้านประสิทธิภาพพลังงานและความปลอดภัย (ไม่ใช่ทุกคนอยากให้ข้อมูลส่วนตัวลอยอยู่ในไซเบอร์สเปซ) จึงมีงานวิจัยมากมายเพื่อทำให้โมเดลเล็กพอจะรันบนอุปกรณ์ของคุณได้โดยตรง ไม่ว่าจะเป็นโทรศัพท์ คอมพิวเตอร์ หรือเบราว์เซอร์
ผมเองก็เคยเขียน วิทยานิพนธ์เกี่ยวกับการลดขนาดโมเดล ASR เพื่อให้รันบนอุปกรณ์ได้ Picovoice เป็นบริษัทแคนาดาที่พัฒนา AI เสียงบนอุปกรณ์ที่หน่วงต่ำ ดูน่าสนใจทีเดียว
ASR บนอุปกรณ์ทำให้การถอดเสียงมีต้นทุนต่ำลง และอาจช่วยให้ชุมชนรายได้น้อยเข้าถึงได้
Transcript-First UI
ช่องว่างระหว่างเสียงกับข้อความถอดเสียงกำลังแคบลง หมายความว่าอย่างไร?
โปรแกรมตัดต่อวิดีโออย่าง Premiere Pro และ Descript ให้คุณนำทางไฟล์เสียงผ่านข้อความถอดเสียง: คลิกที่คำไหนก็จะไปยังเวลานั้นในคลิปทันที
ต้องอัดหลายรอบใช่ไหม? เลือกอันที่ชอบแล้วลบอันอื่นออกได้เหมือนในโปรแกรมแก้ไขข้อความ ระบบจะตัดต่อวิดีโอให้โดยอัตโนมัติ
การตัดต่อแบบนี้ด้วยคลื่นเสียงอย่างเดียวเป็นเรื่องน่าหงุดหงิดมาก แต่ถ้ามีโปรแกรมที่ใช้ข้อความถอดเสียงก็ง่ายสุดๆ
ในทำนองเดียวกัน บริการส่งข้อความอย่าง WhatsApp ก็กำลังถอดเสียงโน้ตเสียงของคุณ และให้คุณเลื่อนดูผ่านข้อความได้ ลากนิ้วไปที่คำไหน ก็จะไปยังส่วนนั้นของไฟล์เสียงทันที

เรื่องตลก: ผมเคยสร้างอะไรแบบนี้ ประมาณหนึ่งสัปดาห์ก่อนที่ Apple จะเปิดตัวฟีเจอร์คล้ายกัน
ตัวอย่างเหล่านี้แสดงให้เห็นว่าเทคโนโลยีเบื้องหลังที่ซับซ้อนช่วยให้แอปพลิเคชันสำหรับผู้ใช้ปลายทางเรียบง่ายและใช้งานง่ายขึ้นได้อย่างไร
ความเท่าเทียม การมีส่วนร่วม และภาษาทรัพยากรต่ำ
การต่อสู้ยังไม่จบ
ASR ใช้ได้ดีในภาษาอังกฤษและภาษาใหญ่ๆ ที่มีทรัพยากรเพียงพอ แต่ไม่ใช่กับภาษาทรัพยากรต่ำ
ยังมีช่องว่างสำหรับภาษาถิ่น กลุ่มเสียงผิดปกติ และปัญหาอื่นๆ เกี่ยวกับ ความเท่าเทียมในเทคโนโลยีเสียง
ขอโทษที่ทำให้บรรยากาศดีๆ สะดุด ส่วนนี้ชื่อว่า “อนาคต” ของ ASR และผมเลือกที่จะมองไปข้างหน้าเพื่ออนาคตที่เราภูมิใจได้
ถ้าเราจะก้าวไปข้างหน้า เราควรไปด้วยกัน ไม่อย่างนั้นความเหลื่อมล้ำในสังคมจะยิ่งเพิ่มขึ้น
เริ่มใช้ ASR ได้แล้ววันนี้
ไม่ว่าธุรกิจของคุณจะเป็นแบบไหน การใช้ ASR ก็เป็นทางเลือกที่ควรทำ — แต่คุณอาจสงสัยว่าจะเริ่มต้นอย่างไร จะติดตั้ง ASR ได้อย่างไร? จะส่งต่อข้อมูลนั้นไปยังเครื่องมืออื่นได้อย่างไร?
Botpress มาพร้อมการ์ดถอดเสียงที่ใช้งานง่าย สามารถนำไปใช้ใน flow แบบลากวาง และเชื่อมต่อกับแอปพลิเคชันและช่องทางสื่อสารต่างๆ ได้หลากหลาย
คำถามที่พบบ่อย
ASR สมัยใหม่แม่นยำแค่ไหนกับสำเนียงต่าง ๆ และสภาพแวดล้อมที่มีเสียงรบกวน?
ระบบ ASR สมัยใหม่มีความแม่นยำสูงสำหรับสำเนียงทั่วไปในภาษาหลัก ๆ โดยมีอัตราความผิดพลาดของคำ (WER) ต่ำกว่า 10% ในสภาพเสียงชัดเจน แต่ความแม่นยำจะลดลงอย่างเห็นได้ชัดเมื่อเจอสำเนียงหนัก ภาษาถิ่น หรือเสียงรบกวนมาก ผู้ให้บริการอย่าง Google และ Microsoft ฝึกโมเดลด้วยข้อมูลเสียงที่หลากหลาย แต่การถอดเสียงให้สมบูรณ์ในสภาพแวดล้อมที่มีเสียงรบกวนยังคงเป็นความท้าทาย
ASR เชื่อถือได้แค่ไหนในการถอดเสียงศัพท์เฉพาะหรือคำศัพท์เฉพาะอุตสาหกรรม?
ASR มักไม่แม่นยำมากนักกับศัพท์เฉพาะหรือคำศัพท์เฉพาะอุตสาหกรรม เพราะข้อมูลที่ใช้ฝึกส่วนใหญ่จะเป็นภาษาทั่วไป คำที่ไม่คุ้นเคยอาจถูกถอดผิดหรือข้ามไป อย่างไรก็ตาม โซลูชันสำหรับองค์กรสามารถเพิ่มคำศัพท์เฉพาะ โมเดลภาษาเฉพาะทาง และพจนานุกรมการออกเสียง เพื่อช่วยให้ระบบรู้จักคำเทคนิคในสายงานต่าง ๆ เช่น การแพทย์ กฎหมาย หรือวิศวกรรมได้ดีขึ้น
ความแตกต่างระหว่างเครื่องมือ ASR ฟรีกับโซลูชันระดับองค์กรคืออะไร?
ความแตกต่างระหว่างเครื่องมือ ASR ฟรีกับโซลูชันระดับองค์กรอยู่ที่ความแม่นยำ ความสามารถในการขยายตัว การปรับแต่ง และการควบคุมความเป็นส่วนตัว: เครื่องมือฟรีมักมีอัตราคำผิดสูง รองรับภาษาจำกัด และมีข้อจำกัดการใช้งาน ขณะที่โซลูชันองค์กรให้ WER ต่ำกว่า ปรับแต่งได้ตามสาขา เชื่อมต่อกับระบบอื่น มีข้อตกลง SLA และฟีเจอร์ความปลอดภัยสำหรับข้อมูลสำคัญ
ASR ปกป้องความเป็นส่วนตัวของผู้ใช้และข้อมูลสำคัญระหว่างการถอดเสียงอย่างไร?
ASR ปกป้องความเป็นส่วนตัวของผู้ใช้ด้วยการเข้ารหัสข้อมูลระหว่างการส่ง และมีตัวเลือกให้รันโมเดลบนอุปกรณ์โดยตรงเพื่อหลีกเลี่ยงการส่งข้อมูลเสียงไปยังเซิร์ฟเวอร์ภายนอก ผู้ให้บริการสำหรับองค์กรหลายรายยังปฏิบัติตามข้อบังคับด้านความเป็นส่วนตัว เช่น GDPR หรือ HIPAA และสามารถทำข้อมูลให้เป็นนิรนามเพื่อป้องกันข้อมูลสำคัญได้ด้วย
บริการ ASR บนคลาวด์มีค่าใช้จ่ายเทียบกับโซลูชันบนอุปกรณ์อย่างไร?
บริการ ASR บนคลาวด์มักคิดค่าบริการตามนาทีเสียงหรือแบ่งเป็นระดับการใช้งาน โดยมีค่าใช้จ่ายตั้งแต่ $0.03–$1.00+ ต่อนาที ขึ้นอยู่กับความแม่นยำและฟีเจอร์ ขณะที่โซลูชันบนอุปกรณ์จะมีค่าใช้จ่ายในการพัฒนาและค่าลิขสิทธิ์ล่วงหน้า



