



- เครือข่ายประสาทเทียมเชิงลึก (DNN) คือระบบการเรียนรู้ของเครื่องที่ประกอบด้วยชั้นของโหนดที่เชื่อมต่อกัน ซึ่งเรียนรู้รูปแบบจากข้อมูลเพื่อนำไปสู่การทำนายผลลัพธ์
- DNN สามารถปรับการเชื่อมต่อภายในตามข้อผิดพลาดที่ผ่านมา ทำให้แม่นยำขึ้นเรื่อย ๆ ด้วยกระบวนการย้อนกลับ (backpropagation)
- ความก้าวหน้าด้านพลังประมวลผลและการเข้าถึงชุดข้อมูลขนาดใหญ่ ทำให้ DNN สามารถนำมาใช้จริงกับงานที่เกี่ยวข้องกับข้อมูลที่ไม่มีโครงสร้าง เช่น ข้อความ รูปภาพ และเสียง
- DNN ทำงานเหมือน “กล่องดำ” ที่มักไม่ชัดเจนว่าตัดสินใจอย่างไร
เครือข่ายประสาทเทียมเชิงลึกคืออะไร?
เครือข่ายประสาทเทียมเชิงลึก (DNN) เป็นโมเดลการเรียนรู้ของเครื่องที่เลียนแบบการประมวลผลข้อมูลของสมองมนุษย์ ต่างจากอัลกอริทึมแบบเดิมที่ทำตามกฎที่กำหนดไว้ DNN สามารถเรียนรู้รูปแบบจากข้อมูลและทำนายผลลัพธ์โดยอาศัยประสบการณ์ที่ผ่านมา — เหมือนกับมนุษย์
DNN เป็นรากฐานของการเรียนรู้เชิงลึก ใช้งานในแอปพลิเคชันอย่าง AI agents การรู้จำภาพ ผู้ช่วยเสียง AI chatbots
ตลาด AI ทั่วโลก — รวมถึงแอปพลิเคชันที่ขับเคลื่อนด้วยเครือข่ายประสาทเทียมเชิงลึก — จะ ทะลุ 500 พันล้านดอลลาร์ภายในปี 2027
สถาปัตยกรรมของเครือข่ายประสาทเทียมคืออะไร?
คำว่า “เชิงลึก” ใน DNN หมายถึงการมีหลายชั้นซ่อนอยู่ ทำให้เครือข่ายสามารถจดจำรูปแบบที่ซับซ้อนได้
เครือข่ายประสาทเทียมประกอบด้วยหลายชั้นของโหนดที่รับข้อมูลจากชั้นอื่นและสร้างผลลัพธ์จนได้ผลลัพธ์สุดท้าย
เครือข่ายประสาทเทียมประกอบด้วยชั้นของโหนด (หรือเซลล์ประสาท) แต่ละโหนดจะรับข้อมูล ประมวลผล และส่งต่อไปยังชั้นถัดไป
- ชั้นรับข้อมูล: ชั้นแรกที่รับข้อมูลดิบ (เช่น รูปภาพ ข้อความ)
- ชั้นซ่อน: ชั้นระหว่างชั้นรับข้อมูลและชั้นผลลัพธ์ ทำหน้าที่แปลงข้อมูลและตรวจจับรูปแบบ
- ชั้นผลลัพธ์: สร้างผลลัพธ์สุดท้าย
เครือข่ายประสาทเทียมสามารถมีชั้นซ่อนกี่ชั้นก็ได้: ยิ่งมีชั้นมาก ความซับซ้อนก็ยิ่งสูง เครือข่ายประสาทเทียมแบบดั้งเดิม มักมี 2 หรือ 3 ชั้นซ่อน ในขณะที่ เครือข่ายการเรียนรู้เชิงลึก อาจมีได้ถึง 150 ชั้นซ่อน
เครือข่ายประสาทเทียมต่างจากเครือข่ายประสาทเทียมเชิงลึกอย่างไร?
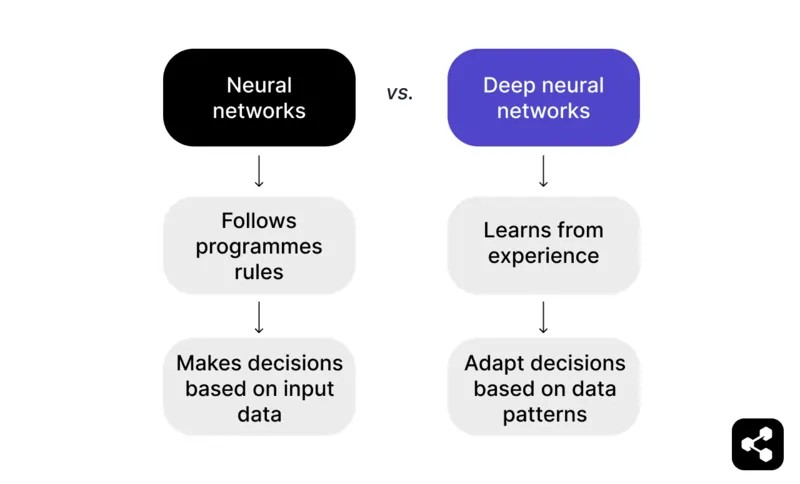
สรุป: เครือข่ายประสาทเทียมที่สามารถเรียนรู้จากประสบการณ์ ไม่ได้อาศัยแค่ข้อมูลขาเข้า จะกลายเป็นเครือข่ายประสาทเทียมเชิงลึก
เครือข่ายประสาทเทียมจะทำตามกฎที่ตั้งโปรแกรมไว้เพื่อตัดสินใจจากข้อมูลขาเข้า ตัวอย่างเช่น ในเกมหมากรุก เครือข่ายประสาทเทียมอาจแนะนำการเดินหมากตามกลยุทธ์ที่ตั้งไว้ แต่จะจำกัดอยู่แค่สิ่งที่โปรแกรมเมอร์กำหนด
แต่เครือข่ายประสาทเทียมเชิงลึกจะไปไกลกว่านั้นด้วยการเรียนรู้จากประสบการณ์ แทนที่จะอาศัยแต่กฎที่ตั้งไว้ DNN สามารถปรับการตัดสินใจตามรูปแบบที่พบในชุดข้อมูลขนาดใหญ่
ตัวอย่าง
ลองนึกภาพการเขียนโปรแกรมเพื่อแยกแยะสุนัขในภาพถ่าย เครือข่ายประสาทเทียมแบบดั้งเดิมต้องตั้งกฎชัดเจน เช่น ลักษณะขนหรือหาง แต่ DNN จะเรียนรู้จากภาพที่ติดป้ายกำกับนับพันภาพและพัฒนาความแม่นยำขึ้นเรื่อย ๆ — แม้ในกรณียาก ๆ โดยไม่ต้องเขียนโปรแกรมเพิ่ม
เครือข่ายประสาทเทียมเชิงลึกทำงานอย่างไร?
เริ่มต้น แต่ละเซลล์ประสาทในชั้นรับข้อมูลจะได้รับข้อมูลดิบ เช่น พิกเซลจากภาพหรือคำในประโยค และกำหนดค่าน้ำหนักให้กับข้อมูลนั้น เพื่อบอกว่าข้อมูลนี้สำคัญกับงานมากแค่ไหน
ค่าน้ำหนักต่ำ (น้อยกว่า 0.5) หมายถึงข้อมูลนั้นมีแนวโน้มว่าจะไม่เกี่ยวข้อง ข้อมูลที่มีค่าน้ำหนักเหล่านี้จะถูกส่งผ่านชั้นซ่อน ซึ่งเซลล์ประสาทจะปรับข้อมูลต่อไป กระบวนการนี้ดำเนินต่อไปหลายชั้นจนถึงชั้นผลลัพธ์ที่ให้การทำนายขั้นสุดท้าย
เครือข่ายประสาทเทียมเชิงลึกจะรู้ได้อย่างไรว่าคำตอบของตนถูกต้อง?
เครือข่ายประสาทเทียมเชิงลึกจะรู้ว่าคำตอบถูกต้องหรือไม่โดยเปรียบเทียบผลทำนายกับข้อมูลที่มีป้ายกำกับระหว่างการฝึก สำหรับแต่ละข้อมูลขาเข้า เครือข่ายจะตรวจสอบว่าคำทำนายตรงกับผลลัพธ์จริงหรือไม่ หากผิด จะคำนวณข้อผิดพลาดด้วยฟังก์ชันสูญเสีย (loss function) ซึ่งวัดว่าคำทำนายคลาดเคลื่อนจากผลลัพธ์จริงมากน้อยเพียงใด
จากนั้นเครือข่ายจะใช้ backpropagation เพื่อปรับค่าน้ำหนักของเซลล์ประสาทที่ทำให้เกิดข้อผิดพลาด กระบวนการนี้จะทำซ้ำในแต่ละรอบ
เครือข่ายประสาทเทียมมีประเภทใดบ้าง?
เครือข่ายประสาทเทียมเชิงลึกพัฒนาตัวเองอย่างไรเมื่อเวลาผ่านไป?
เครือข่ายประสาทเทียมเชิงลึกจะพัฒนาตัวเองโดยเรียนรู้จากข้อผิดพลาด เมื่อมันทำนายผล เช่น การระบุปัญหาลูกค้าหรือแนะนำสินค้า มันจะตรวจสอบว่าคำตอบถูกหรือไม่ หากผิด ระบบจะปรับตัวเองให้ดีขึ้นในครั้งถัดไป
ตัวอย่างเช่น ในฝ่ายบริการลูกค้า DNN อาจทำนายวิธีแก้ไขปัญหา หากทำนายผิด มันจะเรียนรู้จากความผิดพลาดนั้นและเก่งขึ้นในการแก้ปัญหาคล้ายกันในอนาคต ในงานขาย DNN อาจเรียนรู้ว่าลูกค้าแบบไหนมีโอกาสปิดการขายสูง โดยวิเคราะห์ดีลที่ผ่านมาและปรับปรุงคำแนะนำให้ดีขึ้นเรื่อย ๆ
ดังนั้น ทุกครั้งที่มีการใช้งาน DNN จะยิ่งแม่นยำและเชื่อถือได้มากขึ้น
เครือข่ายประสาทเทียมเชิงลึกคิดต่างจากมนุษย์หรือไม่?
แต่โมเดลการเรียนรู้เชิงลึกมักทำงานเหมือน 'กล่องดำ' คือมนุษย์ไม่สามารถอธิบายได้ง่าย ๆ ว่ามันตัดสินใจอย่างไร นักวิจัย AI อย่าง Cynthia Rudin จากมหาวิทยาลัย Duke อธิบาย ว่าความสามารถในการตีความเป็นสิ่งสำคัญต่อการนำ AI ไปใช้ในสถานการณ์ที่มีความเสี่ยงสูงอย่างมีจริยธรรม
นักวิจัยพยายามสร้างภาพให้เห็นว่าเครือข่ายประมวลผลภาพอย่างไร แต่สำหรับงานที่ซับซ้อนกว่า เช่น ภาษา หรือการทำนายทางการเงิน เหตุผลเบื้องหลังยังคงซ่อนอยู่ แม้อัลกอริทึมเหล่านี้จะดูใหม่ แต่หลายอย่างถูกพัฒนามานานแล้ว ความก้าวหน้าด้านข้อมูลและพลังประมวลผลคือสิ่งที่ทำให้ใช้งานได้จริงในปัจจุบัน
ทำไมเครือข่ายประสาทเทียมเชิงลึกถึงได้รับความนิยมมากขึ้น?
1. พลังประมวลผลที่ดีขึ้น
หนึ่งในเหตุผลหลักที่ DNN ได้รับความนิยมคือพลังประมวลผลที่เร็วขึ้นและต้นทุนต่ำลง พลังประมวลผลช่วยให้การฝึกโมเดลรวดเร็ว “การเกิดขึ้นของฮาร์ดแวร์เฉพาะทาง เช่น GPU และ TPU ทำให้สามารถฝึกเครือข่ายที่มีพารามิเตอร์นับพันล้านได้จริง”
2. การมีชุดข้อมูลขนาดใหญ่เพิ่มขึ้น
อีกปัจจัยสำคัญคือการมีชุดข้อมูลขนาดใหญ่ ซึ่งจำเป็นต่อการเรียนรู้ของ DNN เมื่อธุรกิจสร้างข้อมูลมากขึ้น DNN ก็สามารถค้นหารูปแบบที่ซับซ้อนซึ่งโมเดลแบบเดิมไม่สามารถจัดการได้
3. การประมวลผลข้อมูลที่ไม่มีโครงสร้างดีขึ้น
ความสามารถในการจัดการข้อมูลที่ไม่มีโครงสร้าง เช่น ข้อความ รูปภาพ และเสียง ยังเปิดโอกาสใหม่ ๆ ในงานอย่างแชทบอท ระบบแนะนำ และการวิเคราะห์เชิงคาดการณ์
เครือข่ายประสาทเทียมสามารถทำงานกับข้อมูลที่ไม่มีโครงสร้างได้หรือไม่?
ได้ เครือข่ายประสาทเทียมสามารถทำงานกับข้อมูลที่ไม่มีโครงสร้างได้ และนี่คือจุดแข็งสำคัญของมัน
เครือข่ายประสาทเทียมที่ทำงานกับข้อมูลไม่มีโครงสร้างเรียกว่า การเรียนรู้แบบไม่มีผู้สอน ซึ่งถือเป็นเป้าหมายสูงสุดของการเรียนรู้ของเครื่อง และคล้ายกับวิธีที่มนุษย์เรียนรู้
อัลกอริทึมการเรียนรู้ของเครื่องแบบดั้งเดิมมักประมวลผลข้อมูลที่ไม่มีโครงสร้างได้ยาก เพราะต้องอาศัยการออกแบบฟีเจอร์ — การเลือกและดึงคุณสมบัติที่เกี่ยวข้องด้วยมือ ในทางตรงกันข้าม เครือข่ายประสาทเทียมสามารถเรียนรู้รูปแบบจากข้อมูลดิบได้โดยอัตโนมัติ โดยไม่ต้องอาศัยการปรับแต่งด้วยมือมากนัก
เครือข่ายประสาทเทียมเชิงลึกเรียนรู้จากการฝึกอย่างไร?
เครือข่ายประสาทเทียมเชิงลึกจะเรียนรู้โดยการทำนายผลลัพธ์และเปรียบเทียบกับคำตอบที่ถูกต้อง ตัวอย่างเช่น เมื่อประมวลผลภาพถ่าย มันจะทายว่าภาพนั้นมีสุนัขหรือไม่ และติดตามว่าทายถูกบ่อยแค่ไหน
เครือข่ายจะคำนวณความแม่นยำโดยตรวจสอบเปอร์เซ็นต์ของการทายที่ถูกต้อง และใช้ข้อมูลย้อนกลับนี้เพื่อปรับปรุงประสิทธิภาพ มันจะปรับค่าน้ำหนักของนิวรอนและดำเนินกระบวนการซ้ำ หากความแม่นยำดีขึ้นก็จะเก็บค่าน้ำหนักใหม่นั้นไว้ หากไม่ดีขึ้นก็จะลองปรับเปลี่ยนใหม่
กระบวนการนี้จะวนซ้ำหลายรอบจนกว่าเครือข่ายจะสามารถจดจำรูปแบบและทำนายผลได้อย่างแม่นยำ เมื่อถึงจุดนี้จะถือว่าเครือข่ายได้รับการฝึกจนสำเร็จแล้ว
ประหยัดเวลาเขียนโค้ด พร้อมผลลัพธ์ที่ดีกว่า
เครือข่ายประสาทเทียมได้ชื่อนี้เพราะมีความคล้ายคลึงกับวิธีการทำงานของสมองมนุษย์
เช่นเดียวกับสมอง อัลกอริทึมเครือข่ายประสาทจะใช้โครงข่ายของนิวรอนหรือตัวเชื่อมโยง ซึ่งนิวรอนเหล่านี้เป็นฟังก์ชันย่อย ๆ (หรือจะมองว่าเป็นเครื่องจักรเล็ก ๆ ก็ได้) ที่รับอินพุตและสร้างเอาต์พุต นิวรอนเหล่านี้จะถูกจัดเรียงเป็นชั้น ๆ โดยเอาต์พุตของนิวรอนในแต่ละชั้นจะกลายเป็นอินพุตของนิวรอนในชั้นถัดไป จนกระทั่งนิวรอนในชั้นนอกสุดของเครือข่ายสร้างผลลัพธ์สุดท้าย
ดังนั้นจึงมีชั้นของนิวรอน โดยแต่ละนิวรอนจะรับอินพุตและสร้างเอาต์พุตในขอบเขตจำกัด เช่นเดียวกับสมองมนุษย์ ชั้นแรก (หรือชั้นอินพุต) จะรับข้อมูลเข้า และชั้นสุดท้าย (หรือชั้นเอาต์พุต) จะส่งผลลัพธ์ออกมา
การเรียกอัลกอริทึมประเภทนี้ว่า “เครือข่ายประสาทเทียม” ถูกต้องหรือไม่?
การเรียกอัลกอริทึมนี้ว่า 'เครือข่ายประสาทเทียมเชิงลึก' ถือเป็นการสร้างแบรนด์ที่ได้ผล แม้อาจทำให้คาดหวังสูงเกินไป แม้จะทรงพลัง แต่อัลกอริทึมเหล่านี้ก็ยังซับซ้อนน้อยกว่าสมองมนุษย์มาก อย่างไรก็ตาม นักวิจัยยังคงพัฒนาโครงสร้างเครือข่ายประสาทเพื่อมุ่งสู่ปัญญาประดิษฐ์ทั่วไปที่คล้ายมนุษย์
ทั้งนี้ มีบางคนพยายามสร้างสมองขึ้นใหม่โดยใช้เครือข่ายประสาทเทียมที่ซับซ้อนมาก หวังว่าจะสามารถจำลองความฉลาดแบบมนุษย์ในการพัฒนา bot ได้ แล้วเครือข่ายประสาทเทียมและเทคนิค machine learning ช่วยแก้ปัญหาการรู้จำสุนัขของเราได้อย่างไร?
แทนที่จะต้องกำหนดลักษณะของสุนัขด้วยตนเอง อัลกอริทึมเครือข่ายประสาทเทียมเชิงลึกสามารถค้นหาคุณสมบัติสำคัญและจัดการกับกรณีพิเศษต่าง ๆ ได้เองโดยไม่ต้องเขียนโปรแกรมเพิ่ม
คำถามที่พบบ่อย
1. ใช้เวลานานแค่ไหนในการฝึกเครือข่ายประสาทเทียมเชิงลึก?
ระยะเวลาในการฝึกเครือข่ายประสาทเทียมเชิงลึกขึ้นอยู่กับขนาดของชุดข้อมูลและความซับซ้อนของโมเดล หากโมเดลไม่ซับซ้อนอาจฝึกเสร็จในไม่กี่นาทีบนแล็ปท็อป แต่ถ้าเป็นโมเดลขนาดใหญ่ เช่น GPT หรือ ResNet อาจต้องใช้เวลาหลายวันหรือหลายสัปดาห์โดยใช้ GPU หรือ TPU ประสิทธิภาพสูง
2. สามารถฝึก DNN บนคอมพิวเตอร์ส่วนตัวได้หรือไม่?
ได้ คุณสามารถฝึกเครือข่ายประสาทเทียมเชิงลึกบนคอมพิวเตอร์ส่วนตัวได้หากชุดข้อมูลมีขนาดเล็กและโมเดลไม่ซับซ้อนมาก อย่างไรก็ตาม หากต้องฝึกโมเดลขนาดใหญ่หรือใช้ข้อมูลจำนวนมาก คุณจะต้องใช้เครื่องที่มี GPU หรือเข้าถึงแพลตฟอร์มคลาวด์ เช่น AWS หรือ Azure
3. DNN ที่ใช้ใน computer vision กับที่ใช้ใน natural language processing ต่างกันอย่างไร?
เครือข่ายประสาทเทียมเชิงลึกที่ใช้ใน computer vision จะใช้ชั้น convolutional (CNN) เพื่อประมวลผลข้อมูลพิกเซล ขณะที่โมเดล NLP จะใช้สถาปัตยกรรมอย่าง transformers, LSTM หรือ RNN เพื่อจัดการโครงสร้างลำดับและความหมายของภาษา ทั้งสองแบบใช้ deep learning แต่ถูกออกแบบให้เหมาะกับข้อมูลแต่ละประเภท
4. จะเลือกจำนวนชั้นซ่อนใน DNN อย่างไร?
การเลือกจำนวนชั้นซ่อนใน DNN ต้องอาศัยการทดลอง — ถ้ามีน้อยเกินไปอาจเรียนรู้ได้ไม่ดี แต่ถ้ามากเกินไปอาจเกิด overfit และฝึกช้า เริ่มต้นที่ 1–3 ชั้นสำหรับงานง่าย ๆ แล้วค่อยเพิ่มทีละชั้น พร้อมตรวจสอบประสิทธิภาพด้วย cross-validation หรือชุดทดสอบ
5. ความก้าวหน้าครั้งใหญ่ถัดไปในงานวิจัยเครือข่ายประสาทเทียมเชิงลึกคืออะไร?
ความก้าวหน้าที่คาดว่าจะเกิดขึ้นในงานวิจัยเครือข่ายประสาทเทียมเชิงลึก ได้แก่ เครือข่ายประสาทเทียมแบบ sparse (ช่วยลดต้นทุนการประมวลผล), neurosymbolic reasoning (ผสมผสานตรรกะกับ deep learning), เทคนิคการอธิบายผลลัพธ์ที่ดีขึ้น และสถาปัตยกรรมที่ประหยัดพลังงานมากขึ้นโดยเลียนแบบประสิทธิภาพของสมองมนุษย์ เช่น spiking neural networks



