


- Un réseau neuronal profond (DNN) est un système d'apprentissage automatique composé de couches de nœuds connectés qui apprennent des modèles dans les données pour faire des prédictions.
- Les DNN peuvent ajuster leurs connexions internes en fonction des erreurs passées, améliorant ainsi leur précision au fil du temps grâce à la rétropropagation.
- Les progrès de la puissance de calcul et l'accès à des ensembles massifs de données ont rendu les DNN pratiques pour les tâches impliquant des données non structurées telles que le texte, les images et l'audio.
- Les DNN fonctionnent comme des "boîtes noires" et il est souvent difficile de savoir comment ils parviennent à prendre des décisions.
Qu'est-ce qu'un réseau neuronal profond ?
Un réseau neuronal profond (RNP) est un type de modèle d'apprentissage automatique qui imite la façon dont le cerveau humain traite les informations. Contrairement aux algorithmes traditionnels qui suivent des règles prédéfinies, les réseaux neuronaux profonds peuvent apprendre des modèles à partir de données et faire des prédictions basées sur des expériences antérieures - tout comme nous.
Les DNN sont le fondement de l'apprentissage profond et alimentent des applications telles que les agents d'intelligence artificielle, la reconnaissance d'images, les assistants vocaux et les chatbots d'intelligence artificielle.
Le marché mondial de l'IA - y compris les applications alimentées par des réseaux neuronaux profonds - dépassera les 500 milliards de dollars d'ici 2027.
Qu'est-ce que l'architecture d'un réseau neuronal ?
Le terme "profond" dans DNN fait référence à la présence de plusieurs couches cachées, ce qui permet au réseau de reconnaître des modèles complexes.
Un réseau neuronal est composé de plusieurs couches de nœuds qui reçoivent des entrées d'autres couches et produisent une sortie jusqu'à ce qu'un résultat final soit atteint.
Un réseau neuronal se compose de couches de nœuds (neurones). Chaque nœud reçoit une entrée, la traite et la transmet à la couche suivante.
- Couche d'entrée: La première couche qui prend des données brutes (par exemple, des images, du texte).
- Couches cachées: Couches entre l'entrée et la sortie qui transforment les données et détectent les modèles.
- Couche de sortie: Elle produit la prédiction finale.
Les réseaux neuronaux peuvent comporter un nombre quelconque de couches cachées : plus le réseau comporte de couches de nœuds, plus il est complexe. Les réseaux neuronaux traditionnels sont généralement composés de 2 ou 3 couches cachées, tandis que les réseaux d'apprentissage profond peuvent comporter jusqu'à 150 couches cachées.
En quoi les réseaux neuronaux diffèrent-ils des réseaux neuronaux profonds ?
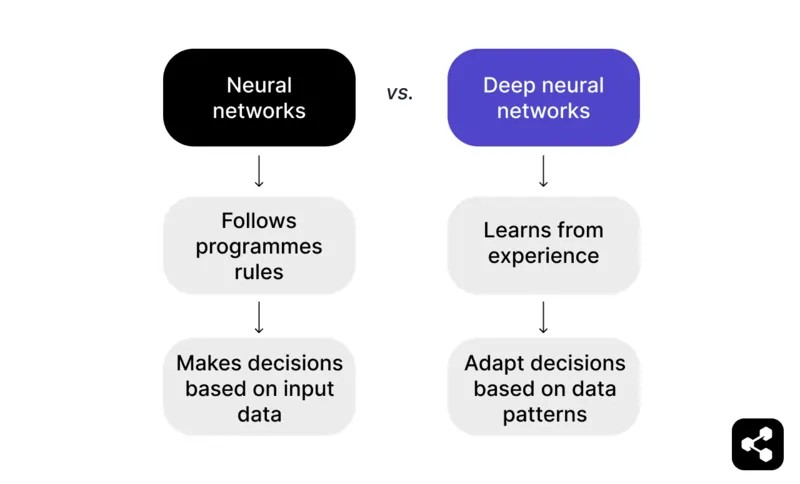
En bref : un réseau neuronal qui va au-delà des données d'entrée et peut apprendre à partir d'expériences antérieures devient un réseau neuronal profond.
Un réseau neuronal suit des règles programmées pour prendre des décisions basées sur des données d'entrée. Par exemple, dans un jeu d'échecs, un réseau neuronal peut suggérer des mouvements basés sur des tactiques et des stratégies prédéfinies, mais il est limité à ce que le programmeur a fourni.
Mais un réseau neuronal profond va plus loin en apprenant par l'expérience. Au lieu de s'appuyer uniquement sur des règles prédéfinies, un réseau neuronal profond peut ajuster ses décisions en fonction des modèles qu'il reconnaît dans de vastes ensembles de données.
Exemple
Imaginez que vous écriviez un programme pour reconnaître des chiens sur des photos. Un réseau neuronal traditionnel nécessiterait des règles explicites pour identifier des caractéristiques telles que la fourrure ou la queue. Un réseau neuronal DNN, en revanche, apprendrait à partir de milliers d'images étiquetées et améliorerait sa précision au fil du temps, traitant même les cas difficiles sans programmation supplémentaire.
Comment fonctionne un réseau neuronal profond ?
Tout d'abord, chaque neurone de la couche d'entrée reçoit un élément de données brutes, comme les pixels d'une image ou les mots d'une phrase, et attribue un poids à cette entrée, indiquant sa pertinence pour la tâche.
Un poids faible (inférieur à 0,5) signifie que l'information a moins de chances d'être pertinente. Ces entrées pondérées sont transmises à des couches cachées, où les neurones ajustent encore l'information. Ce processus se poursuit sur plusieurs couches jusqu'à ce que la couche de sortie fournisse une prédiction finale.
Comment un réseau neuronal profond peut-il savoir s'il a raison ?
Un réseau neuronal profond sait s'il a raison en comparant ses prédictions à des données étiquetées pendant la formation. Pour chaque entrée, le réseau vérifie si sa prédiction correspond au résultat réel. S'il se trompe, le réseau calcule l'erreur à l'aide d'une fonction de perte, qui mesure l'écart entre la prédiction et le résultat.
Le réseau utilise ensuite la rétropropagation pour ajuster les poids des neurones qui ont contribué à l'erreur. Ce processus se répète à chaque itération.
Quels sont les différents types de réseaux neuronaux ?
Comment un réseau neuronal profond s'améliore-t-il au fil du temps ?
Un réseau neuronal profond s'améliore au fil du temps en apprenant de ses erreurs. Lorsqu'il fait une prédiction - comme identifier un problème de client ou recommander un produit - il vérifie s'il avait raison. Si ce n'est pas le cas, le système s'adapte pour s'améliorer la prochaine fois.
Par exemple, dans le domaine de l'assistance à la clientèle, un réseau DNN peut prédire comment résoudre un ticket. Si la prédiction est erronée, il apprend de cette erreur et s'améliore pour résoudre des tickets similaires à l'avenir. Dans le domaine de la vente, un réseau DNN pourrait apprendre quels prospects se convertissent le mieux en analysant les transactions passées, ce qui lui permettrait d'améliorer ses recommandations au fil du temps.
Ainsi, à chaque interaction, le réseau DNN devient plus précis et plus fiable.
Les réseaux neuronaux profonds pensent-ils différemment des humains ?
Mais les modèles d'apprentissage profond fonctionnent souvent comme une "boîte noire", ce qui signifie que les humains ne peuvent pas facilement interpréter la manière dont ils prennent leurs décisions. Comme l 'explique Cynthia Rudin, chercheuse en IA à l'université Duke, l'interprétabilité est cruciale pour le déploiement éthique des systèmes d'IA, en particulier dans les environnements à fort enjeu.
Les chercheurs ont tenté de visualiser la manière dont les réseaux traitent les images, mais pour les tâches plus complexes, comme le langage ou les prédictions financières, la logique reste cachée. Si ces algorithmes semblent nouveaux, nombre d'entre eux ont été mis au point il y a plusieurs dizaines d'années. Ce sont les progrès en matière de données et de puissance de calcul qui les rendent pratiques aujourd'hui.
Pourquoi les réseaux neuronaux profonds sont-ils de plus en plus populaires ?
1. Amélioration de la puissance de traitement
L'une des principales raisons de l'essor des DNN est que la puissance de traitement est plus rapide et moins chère. La puissance de calcul a fait toute la différence dans la réalisation d'une convergence rapide. "L'essor du matériel spécialisé, comme les unités de traitement graphique (GPU) et les unités de traitement tensoriel (TPU), a permis d'entraîner des réseaux avec des milliards de paramètres."
2. Disponibilité croissante des ensembles de données
Un autre facteur clé est la disponibilité de grands ensembles de données, dont les réseaux neuronaux profonds ont besoin pour apprendre efficacement. Les entreprises générant de plus en plus de données, les réseaux neuronaux profonds peuvent mettre en évidence des schémas complexes que les modèles traditionnels ne peuvent pas traiter.
3. Amélioration du traitement des données non structurées
Leur capacité à traiter des données non structurées telles que du texte, des images et du son a également ouvert la voie à de nouvelles applications dans des domaines tels que les chatbots, les systèmes de recommandation et l'analyse prédictive.
Les réseaux neuronaux peuvent-ils fonctionner avec des données non structurées ?
Oui, les réseaux neuronaux peuvent travailler avec des données non structurées, et c'est l'un de leurs principaux atouts.
Les réseaux neuronaux artificiels qui travaillent avec des données non structurées sont appelés apprentissage non supervisé. Il s'agit du Saint-Graal de l'apprentissage automatique et il est plus proche de la manière dont les humains apprennent.
Les algorithmes traditionnels d'apprentissage automatique ont du mal à traiter les données non structurées car ils nécessitent une ingénierie des caractéristiques, c'est-à-dire la sélection et l'extraction manuelles des caractéristiques pertinentes. En revanche, les réseaux neuronaux peuvent apprendre automatiquement des modèles dans les données brutes sans intervention manuelle importante.
Comment les réseaux neuronaux profonds utilisent-ils la formation pour apprendre ?
Un réseau neuronal profond apprend en faisant des prédictions et en les comparant aux bons résultats. Par exemple, lorsqu'il traite des photos, il prédit si une image contient un chien et suit le nombre de fois où il obtient la bonne réponse.
Le réseau calcule sa précision en vérifiant le pourcentage de prédictions correctes et utilise ce retour d'information pour s'améliorer. Il ajuste les poids de ses neurones et recommence le processus. Si la précision s'améliore, il conserve les nouveaux poids ; dans le cas contraire, il tente d'autres ajustements.
Ce cycle se répète sur de nombreuses itérations jusqu'à ce que le réseau puisse reconnaître des modèles de manière cohérente et faire des prédictions précises. Une fois qu'il a atteint ce stade, on dit que le réseau a convergé et qu'il a été formé avec succès.
Gagner du temps de codage et obtenir de meilleurs résultats
Le réseau neuronal est ainsi nommé parce qu'il existe une similitude entre cette approche de programmation et le fonctionnement du cerveau.
Tout comme le cerveau, les algorithmes de réseaux neuronaux utilisent un réseau de neurones ou de nœuds. Et comme le cerveau, ces neurones sont des fonctions discrètes (ou des petites machines si vous préférez) qui reçoivent des entrées et génèrent des sorties. Ces nœuds sont disposés en couches, les sorties des neurones d'une couche devenant les entrées des neurones de la couche suivante, jusqu'à ce que les neurones de la couche externe du réseau génèrent le résultat final.
Il y a donc des couches de neurones, chaque neurone individuel recevant des entrées très limitées et générant des sorties très limitées, comme dans le cerveau. La première couche de neurones (ou couche d'entrée) reçoit les entrées et la dernière couche de neurones (ou couche de sortie) du réseau produit le résultat.
Est-il exact d'appeler ce type d'algorithme un "réseau neuronal" ?
Qualifier cet algorithme de "réseau neuronal profond" s'est avéré efficace en termes d'image de marque, même si cela peut susciter des attentes trop ambitieuses. Bien que puissants, ces modèles sont encore bien plus simples que la complexité du cerveau humain. Néanmoins, les chercheurs continuent d'explorer les architectures neuronales en vue d'une intelligence générale semblable à celle de l'homme.
Cela dit, certains tentent de remodeler le cerveau à l'aide d'un réseau neuronal très complexe, dans l'espoir de pouvoir reproduire une intelligence générale semblable à celle de l'homme dans le développement des robots. Comment un réseau neuronal et des techniques d'apprentissage automatique peuvent-ils nous aider à résoudre notre problème de reconnaissance des chiens ?
Au lieu de définir manuellement les attributs d'un chien, un algorithme de réseau neuronal profond peut identifier les attributs importants et traiter tous les cas particuliers sans programmation.
FAQ
1. Combien de temps faut-il pour former un réseau neuronal profond ?
Le temps nécessaire à la formation d'un réseau neuronal profond dépend de la taille de l'ensemble de données et de la complexité du modèle. Un modèle simple peut s'entraîner en quelques minutes sur un ordinateur portable, tandis qu'un modèle à grande échelle comme GPT ou ResNet peut prendre des jours, voire des semaines, en utilisant des GPU ou des TPU hautes performances.
2. Puis-je entraîner un DNN sur mon ordinateur personnel ?
Oui, vous pouvez former un réseau neuronal profond sur un ordinateur personnel si l'ensemble de données est petit et le modèle relativement simple. Toutefois, pour former des modèles de grande taille ou utiliser des ensembles de données volumineux, vous aurez besoin d'une installation dotée d'un GPU ou d'un accès à des plateformes en nuage telles que AWS ou Azure.
3. Quelle est la différence entre un DNN utilisé en vision artificielle et un DNN utilisé en traitement du langage naturel ?
Un réseau neuronal profond utilisé en vision par ordinateur utilise des couches convolutives (CNN) pour traiter les données relatives aux pixels, tandis que les modèles de NLP utilisent des architectures telles que les transformateurs, les LSTM ou les RNN pour traiter la structure séquentielle et sémantique du langage. Les deux utilisent l'apprentissage profond, mais sont optimisés pour des types de données différents.
4. Comment choisir le nombre de couches cachées dans un réseau DNN ?
Le choix du nombre de couches cachées dans un DNN implique une expérimentation - un nombre trop faible peut entraîner une sous-adaptation aux données, tandis qu'un nombre trop élevé peut entraîner une suradaptation et ralentir l'apprentissage. Commencez par 1 à 3 couches pour les tâches simples et augmentez-les progressivement, en validant les performances par validation croisée ou à l'aide d'un ensemble de tests.
5. Quelles sont les prochaines grandes avancées attendues dans la recherche sur les réseaux neuronaux profonds ?
Les futures percées dans la recherche sur les réseaux neuronaux profonds comprennent les réseaux neuronaux épars (qui réduisent le coût de calcul), le raisonnement neurosymbolique (qui combine la logique et l'apprentissage profond), l'amélioration des techniques d'interprétabilité et des architectures plus économes en énergie qui imitent l'efficacité du cerveau humain (par exemple, les réseaux neuronaux à pointes).


.webp)

