



- Una rete neurale profonda (DNN) è un sistema di machine learning composto da strati di nodi collegati che apprendono schemi nei dati per fare previsioni.
- Le DNN possono modificare le proprie connessioni interne in base agli errori passati, migliorando la precisione nel tempo tramite backpropagation.
- I progressi nella potenza di calcolo e l’accesso a grandi quantità di dati hanno reso le DNN pratiche per attività che coinvolgono dati non strutturati come testo, immagini e audio.
- Le DNN funzionano come “scatole nere” in cui spesso non è chiaro come vengano prese le decisioni.
Cos’è una deep neural network?
Una deep neural network (DNN) è un modello di machine learning che imita il modo in cui il cervello umano elabora le informazioni. A differenza degli algoritmi tradizionali che seguono regole predefinite, le DNN possono apprendere schemi dai dati e fare previsioni basate su esperienze precedenti, proprio come noi.
Le DNN sono la base del deep learning e alimentano applicazioni come agenti AI, riconoscimento immagini, assistenti vocali, chatbot AI.
Il mercato globale dell’AI — incluse le applicazioni basate su reti neurali profonde — supererà i 500 miliardi di dollari entro il 2027.
Cos’è l’architettura di una rete neurale?
Il termine “deep” in DNN si riferisce alla presenza di più livelli nascosti, che permettono alla rete di riconoscere schemi complessi.
Una rete neurale è composta da più livelli di nodi che ricevono input da altri livelli e producono un output fino a raggiungere il risultato finale.
Una rete neurale è composta da strati di nodi (neuroni). Ogni nodo riceve un input, lo elabora e lo passa allo strato successivo.
- Livello di input: Il primo livello che riceve i dati grezzi (ad esempio immagini, testo).
- Layer nascosti: Layer tra input e output che trasformano i dati e rilevano schemi.
- Livello di output: Produce la previsione finale.
Le reti neurali possono avere qualsiasi numero di layer nascosti: più layer ci sono, maggiore è la complessità. Le reti neurali tradizionali sono di solito composte da 2 o 3 layer nascosti, mentre le reti di deep learning possono arrivare fino a 150 layer nascosti.
In cosa si differenziano le reti neurali dalle deep neural networks?
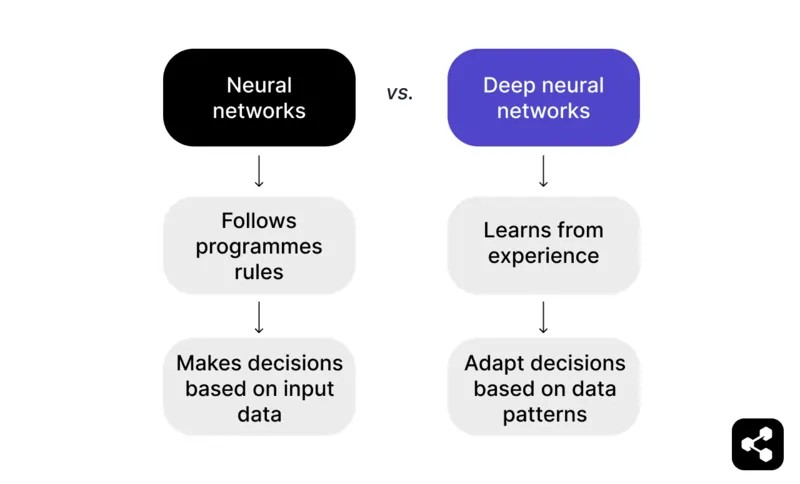
In breve: una rete neurale che va oltre i dati di input e può apprendere dalle esperienze precedenti diventa una rete neurale profonda.
Una rete neurale segue regole programmate per prendere decisioni in base ai dati in ingresso. Ad esempio, in una partita a scacchi, una rete neurale può suggerire mosse basate su tattiche e strategie preimpostate, ma è limitata a ciò che il programmatore ha previsto.
Ma una deep neural network va oltre, imparando dall’esperienza. Invece di affidarsi solo a regole preimpostate, una DNN può adattare le sue decisioni in base ai modelli che riconosce in grandi set di dati.
Esempio
Immagina di scrivere un programma per riconoscere i cani nelle foto. Una rete neurale tradizionale richiederebbe regole esplicite per identificare caratteristiche come il pelo o la coda. Una DNN, invece, imparerebbe da migliaia di immagini etichettate, migliorando la precisione nel tempo — riuscendo a gestire anche i casi difficili senza ulteriore programmazione.
Come funziona una rete neurale profonda?
Per prima cosa, ogni neurone nello strato di input riceve un dato grezzo, come i pixel di un’immagine o le parole di una frase, e assegna un peso a questo input, indicando quanto sia rilevante per il compito.
Un peso basso (inferiore a 0,5) indica che è meno probabile che l’informazione sia rilevante. Questi input ponderati passano attraverso strati nascosti, dove i neuroni regolano ulteriormente le informazioni. Questo processo continua su più livelli fino a quando lo strato di output fornisce una previsione finale.
Come fa una rete neurale profonda a sapere se ha ragione?
Una rete neurale profonda sa se ha ragione confrontando le sue previsioni con dati etichettati durante l’addestramento. Per ogni input, la rete verifica se la previsione corrisponde al risultato reale. Se sbaglia, calcola l’errore tramite una funzione di perdita, che misura quanto la previsione si discosta dal risultato atteso.
La rete utilizza quindi la backpropagation per regolare i pesi dei neuroni che hanno contribuito all'errore. Questo processo si ripete a ogni iterazione.
Quali sono i diversi tipi di reti neurali?
Come migliora nel tempo una rete neurale profonda?
Una rete neurale profonda migliora nel tempo imparando dai propri errori. Quando fa una previsione — come identificare un problema di un cliente o consigliare un prodotto — verifica se aveva ragione. Se sbaglia, il sistema si corregge per migliorare la volta successiva.
Ad esempio, nell’assistenza clienti, una DNN può prevedere come risolvere un ticket. Se la previsione è errata, impara dall’errore e migliora nella risoluzione di casi simili in futuro. Nelle vendite, una DNN può imparare quali lead convertono meglio analizzando le trattative passate, migliorando così le sue raccomandazioni nel tempo.
Così, con ogni interazione, la DNN diventa più precisa e affidabile.
Le reti neurali profonde pensano in modo diverso dagli esseri umani?
Ma i modelli di deep learning spesso funzionano come una 'scatola nera', il che significa che gli esseri umani non possono facilmente interpretare come arrivano alle loro decisioni. Come spiega la ricercatrice AI Cynthia Rudin della Duke University , l’interpretabilità è fondamentale per un uso etico dei sistemi AI, soprattutto in contesti critici.
I ricercatori hanno provato a visualizzare come le reti elaborano le immagini, ma per compiti più complessi — come il linguaggio o le previsioni finanziarie — la logica resta nascosta. Anche se questi algoritmi sembrano nuovi, molti sono stati sviluppati decenni fa. I progressi nei dati e nella potenza di calcolo li rendono oggi praticabili.
Perché le reti neurali profonde sono sempre più popolari?
1. Miglioramenti nella potenza di calcolo
Uno dei motivi principali dell’aumento delle DNN è che la potenza di calcolo è più veloce ed economica. La potenza di calcolo ha fatto la differenza nel raggiungere una rapida convergenza. “La diffusione di hardware specializzato come GPU e TPU ha reso possibile addestrare reti con miliardi di parametri.”
2. Maggiore disponibilità di dataset
Un altro fattore chiave è la disponibilità di grandi set di dati, necessari alle reti neurali profonde per apprendere efficacemente. Con l’aumento dei dati generati dalle aziende, le DNN possono scoprire schemi complessi che i modelli tradizionali non riescono a gestire.
3. Miglioramenti nell’elaborazione di dati non strutturati
La loro capacità di elaborare dati non strutturati come testo, immagini e audio ha aperto nuove applicazioni in ambiti come chatbot, sistemi di raccomandazione e analisi predittiva.
Le reti neurali possono lavorare con dati non strutturati?
Sì, le reti neurali possono lavorare con dati non strutturati, ed è proprio uno dei loro maggiori punti di forza.
Le reti neurali artificiali che lavorano con dati non strutturati sono chiamate apprendimento non supervisionato. Questo è il traguardo dell’apprendimento automatico ed è più simile a come imparano gli esseri umani.
Gli algoritmi di machine learning tradizionali faticano a gestire dati non strutturati perché richiedono l’ingegnerizzazione delle feature — la selezione ed estrazione manuale delle caratteristiche rilevanti. Al contrario, le reti neurali possono apprendere automaticamente schemi nei dati grezzi senza un intervento manuale esteso.
Come fanno le reti neurali profonde a imparare tramite l’addestramento?
Una rete neurale profonda apprende facendo previsioni e confrontandole con i risultati corretti. Ad esempio, quando elabora delle foto, prevede se un’immagine contiene un cane e tiene traccia di quante volte indovina la risposta giusta.
La rete calcola la sua accuratezza verificando la percentuale di previsioni corrette e usa questo feedback per migliorare. Regola i pesi dei suoi neuroni e ripete il processo. Se l’accuratezza migliora, mantiene i nuovi pesi; altrimenti prova altre regolazioni.
Questo ciclo si ripete per molte iterazioni finché la rete non riesce a riconoscere costantemente i pattern e a fare previsioni accurate. Una volta raggiunto questo punto, si dice che la rete abbia convergito ed è stata addestrata con successo.
Risparmia tempo di sviluppo ottenendo risultati migliori
La rete neurale prende questo nome perché esiste una somiglianza tra questo approccio di programmazione e il funzionamento del cervello.
Proprio come il cervello, gli algoritmi delle reti neurali utilizzano una rete di neuroni o nodi. E, come nel cervello, questi neuroni sono funzioni discrete (o piccole macchine, se preferisci) che ricevono input e generano output. Questi nodi sono organizzati in livelli: gli output dei neuroni di un livello diventano input per i neuroni del livello successivo, fino a quando i neuroni dello strato più esterno generano il risultato finale.
Ci sono quindi strati di neuroni, ognuno dei quali riceve input molto limitati e genera output altrettanto limitati, proprio come nel cervello. Il primo strato (o strato di input) riceve gli input e l’ultimo strato (o strato di output) restituisce il risultato.
È corretto chiamare questo tipo di algoritmo una “rete neurale”?
Chiamare questo algoritmo una 'rete neurale profonda' si è rivelato efficace dal punto di vista del marketing, anche se può creare aspettative troppo alte. Pur essendo potenti, questi modelli sono ancora molto più semplici rispetto alla complessità del cervello umano. Tuttavia, i ricercatori continuano a esplorare architetture neurali con l’obiettivo di raggiungere un’intelligenza generale simile a quella umana.
Detto ciò, ci sono persone che cercano di riprogettare il cervello usando una rete neurale molto complessa, sperando così di riuscire a replicare un’intelligenza generale simile a quella umana nello sviluppo dei bot. Ma in che modo una rete neurale e le tecniche di machine learning ci aiutano nel nostro problema di riconoscimento dei cani?
Invece di definire manualmente le caratteristiche di un cane, un algoritmo di rete neurale profonda può identificare gli attributi importanti e gestire tutti i casi particolari senza programmazione.
Domande frequenti
1. Quanto tempo serve per addestrare una rete neurale profonda?
Il tempo necessario per addestrare una rete neurale profonda dipende dalla dimensione del dataset e dalla complessità del modello. Un modello semplice può essere addestrato in pochi minuti su un portatile, mentre uno di grandi dimensioni come GPT o ResNet può richiedere giorni o settimane su GPU o TPU ad alte prestazioni.
2. Posso addestrare una DNN sul mio computer personale?
Sì, puoi addestrare una rete neurale profonda su un computer personale se il dataset è piccolo e il modello è relativamente semplice. Tuttavia, per modelli grandi o dataset estesi, avrai bisogno di una configurazione con GPU o accesso a piattaforme cloud come AWS o Azure.
3. Qual è la differenza tra una DNN usata per la computer vision e una usata per l’elaborazione del linguaggio naturale?
Una rete neurale profonda utilizzata nella computer vision impiega strati convoluzionali (CNN) per elaborare i dati dei pixel, mentre i modelli NLP utilizzano architetture come transformer, LSTM o RNN per gestire la struttura sequenziale e semantica del linguaggio. Entrambi usano il deep learning, ma sono ottimizzati per tipi di dati diversi.
4. Come si sceglie il numero di layer nascosti in una DNN?
La scelta del numero di layer nascosti in una DNN richiede sperimentazione: troppo pochi rischiano di sottostimare i dati, troppi possono portare a overfitting e rallentare l’addestramento. Parti da 1–3 layer per compiti semplici e aumenta gradualmente, validando le prestazioni con cross-validation o un set di test.
5. Quali sono le prossime grandi innovazioni attese nella ricerca sulle reti neurali profonde?
Le future innovazioni nella ricerca sulle reti neurali profonde includono reti neurali sparse (che riducono i costi di calcolo), ragionamento neurosimbolico (che combina la logica con il deep learning), tecniche di interpretabilità migliorate e architetture più efficienti dal punto di vista energetico che imitano l’efficienza del cervello umano (ad esempio, reti neurali a spiking).



