



- Ang deep neural network (DNN) ay isang sistema ng machine learning na binubuo ng mga patong-patong na konektadong node na natututo ng mga pattern mula sa datos upang makagawa ng prediksyon.
- Kayang baguhin ng mga DNN ang kanilang mga panloob na koneksyon batay sa mga nagdaang pagkakamali, kaya't gumagaling ang kanilang katumpakan sa pagdaan ng panahon gamit ang backpropagation.
- Dahil sa pag-unlad ng kakayahan ng mga computer at pagdami ng malalaking dataset, naging praktikal ang paggamit ng DNN para sa mga gawain na may hindi istrakturadong datos tulad ng teksto, larawan, at tunog.
- Gumagana ang mga DNN bilang “black box” kung saan madalas hindi malinaw kung paano sila nakararating sa kanilang mga desisyon.
Ano ang deep neural network?
Ang deep neural network (DNN) ay isang uri ng modelo ng machine learning na ginagaya ang paraan ng pagproseso ng impormasyon ng utak ng tao. Hindi tulad ng mga tradisyonal na algorithm na sumusunod sa nakatakdang mga tuntunin, natututo ang mga DNN mula sa datos at nakagagawa ng prediksyon batay sa mga naunang karanasan — gaya ng ginagawa natin.
Ang mga DNN ang pundasyon ng deep learning, na nagpapagana sa mga aplikasyon tulad ng AI agents, pagkilala ng larawan, voice assistants, AI chatbots.
Ang pandaigdigang merkado ng AI—kabilang ang mga aplikasyon na pinapagana ng deep neural networks—ay lalampas sa $500 bilyon pagsapit ng 2027.
Ano ang neural network architecture?
Ang “deep” sa DNN ay tumutukoy sa pagkakaroon ng maraming nakatagong patong, na nagpapahintulot sa network na makakilala ng masalimuot na mga pattern.
Ang neural network ay binubuo ng maraming patong ng mga node na tumatanggap ng input mula sa ibang mga patong at gumagawa ng output hanggang makuha ang huling resulta.
Ang neural network ay binubuo ng mga patong ng node (neurons). Bawat node ay tumatanggap ng input, pinoproseso ito, at ipinapasa sa susunod na patong.
- Input layer: Ang unang patong na tumatanggap ng hilaw na datos (halimbawa, larawan, teksto).
- Hidden layers: Mga patong sa pagitan ng input at output na nagbabago at nakakakita ng mga pattern sa datos.
- Output layer: Gumagawa ng huling prediksyon.
Maaaring magkaroon ng kahit ilang hidden layer ang neural networks: habang dumarami ang mga patong ng node, mas nagiging masalimuot ang network. Ang tradisyonal na neural networks ay karaniwang may 2 o 3 hidden layers, samantalang ang deep learning networks ay maaaring umabot ng hanggang 150 hidden layers.
Paano naiiba ang neural networks sa deep neural networks?
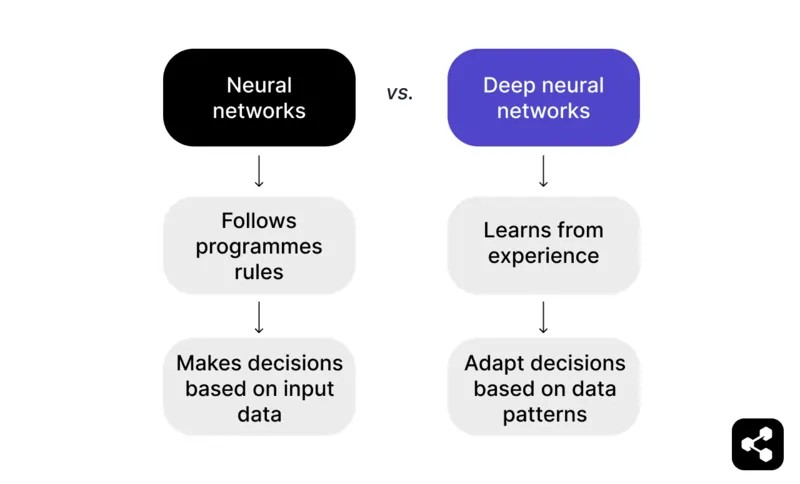
Sa madaling sabi: Ang neural network na lumalampas sa input na datos at natututo mula sa mga naunang karanasan ay nagiging deep neural network.
Ang neural network ay sumusunod sa mga programadong tuntunin upang gumawa ng desisyon batay sa input na datos. Halimbawa, sa larong chess, maaaring magmungkahi ng galaw ang neural network batay sa mga nakatakdang taktika at estratehiya, ngunit limitado ito sa itinakda ng programmer.
Ngunit ang deep neural network ay higit pa rito dahil natututo ito mula sa karanasan. Sa halip na umasa lang sa mga nakatakdang tuntunin, kayang baguhin ng DNN ang mga desisyon batay sa mga pattern na nakikita nito sa malalaking dataset.
Halimbawa
Isipin mong gumagawa ka ng programang nakakakilala ng aso sa mga larawan. Ang tradisyonal na neural network ay mangangailangan ng malinaw na tuntunin para matukoy ang mga katangian tulad ng balahibo o buntot. Ang DNN naman ay matututo mula sa libu-libong larawan na may label at gagaling sa pagdaan ng panahon — kaya nitong kilalanin kahit mahirap na kaso nang hindi na kailangan ng dagdag na pagprograma.
Paano gumagana ang deep neural network?
Una, bawat neuron sa input layer ay tumatanggap ng bahagi ng raw na datos, gaya ng mga pixel mula sa larawan o mga salita mula sa pangungusap, at nagtatakda ng timbang sa input na ito, na nagsasaad kung gaano ito kahalaga sa gawain.
Ang mababang timbang (mas mababa sa 0.5) ay nangangahulugang mas maliit ang posibilidad na mahalaga ang impormasyong iyon. Ang mga input na may timbang ay ipinapasa sa mga hidden layer, kung saan lalo pang inaayos ng mga neuron ang impormasyon. Paulit-ulit itong nangyayari sa maraming patong hanggang makuha ang huling prediksyon mula sa output layer.
Paano nalalaman ng deep neural network kung tama ito?
Nalalaman ng deep neural network kung tama ito sa pamamagitan ng paghahambing ng mga prediksyon nito sa datos na may label habang nagsasanay. Para sa bawat input, tinitingnan ng network kung tumugma ang prediksyon sa aktwal na resulta. Kapag mali, kinukuwenta ng network ang error gamit ang loss function, na sumusukat kung gaano kalayo ang prediksyon.
Pagkatapos, ginagamit ng network ang backpropagation para ayusin ang mga timbang ng mga neuron na nag-ambag sa pagkakamali. Paulit-ulit ang prosesong ito sa bawat pag-ikot.
Ano-ano ang iba't ibang uri ng neural networks?
Paano gumagaling ang deep neural network habang tumatagal?
Gumagaling ang deep neural network habang tumatagal sa pamamagitan ng pagkatuto mula sa mga pagkakamali. Kapag gumawa ito ng prediksyon — tulad ng pagtukoy ng problema ng customer o pagrekomenda ng produkto — tinitingnan nito kung tama ang sagot. Kung mali, inaayos ng sistema ang sarili para gumaling sa susunod.
Halimbawa, sa customer support, maaaring hulaan ng DNN kung paano sosolusyunan ang isang ticket. Kung mali ang prediksyon, natututo ito mula sa pagkakamaling iyon at gumagaling sa pagsagot ng katulad na ticket sa hinaharap. Sa sales, maaaring matutunan ng DNN kung aling mga lead ang pinakamadaling makonvert sa pamamagitan ng pagsusuri ng mga nagdaang deal, kaya gumagaling ang mga rekomendasyon nito habang tumatagal.
Kaya sa bawat interaksyon, lalong nagiging tumpak at maaasahan ang DNN.
Iba ba mag-isip ang deep neural networks kumpara sa tao?
Ngunit madalas gumana ang mga deep learning model bilang 'black box', ibig sabihin, hindi madaling maunawaan ng tao kung paano sila nakararating sa kanilang mga desisyon. Gaya ng paliwanag ni AI researcher Cynthia Rudin mula sa Duke University ipinaliwanag, mahalaga ang interpretability para sa etikal na paggamit ng mga sistema ng AI, lalo na sa mga sensitibong sitwasyon.
Sinubukan ng mga mananaliksik na gawing mas malinaw kung paano pinoproseso ng mga network ang mga larawan, ngunit para sa mas komplikadong gawain—tulad ng wika o prediksyon sa pananalapi—nananatiling nakatago ang lohika. Bagamat tila bago ang mga algorithm na ito, marami sa mga ito ay nilikha na dekada na ang nakalipas. Ang pag-unlad sa datos at computing power ang dahilan kung bakit praktikal na silang gamitin ngayon.
Bakit patuloy na sumisikat ang deep neural networks?
1. Pagbuti ng processing power
Isa sa mga pangunahing dahilan ng pagdami ng DNN ay mas mabilis at mas mura na ang processing power. Malaki ang naging epekto ng computing power sa mabilis na convergence. “Ang pag-usbong ng mga espesyal na hardware tulad ng Graphics Processing Units (GPUs) at Tensor Processing Units (TPUs) ang nagpadali sa pagsasanay ng mga network na may bilyon-bilyong parameter.”
2. Dumadaming mga dataset
Isa pang mahalagang salik ay ang pagkakaroon ng malalaking dataset, na kailangan ng deep neural networks para matutong mabuti. Habang mas maraming datos ang nalilikha ng mga negosyo, mas natutuklasan ng DNN ang masalimuot na mga pattern na hindi kayang hawakan ng tradisyonal na mga modelo.
3. Pagbuti ng pagproseso ng hindi istrakturadong datos
Ang kakayahan nilang magproseso ng hindi istrakturadong datos tulad ng teksto, larawan, at tunog ay nagbukas din ng mga bagong aplikasyon sa larangan ng chatbots, recommendation systems, at predictive analytics.
Kaya bang magtrabaho ng neural networks gamit ang hindi istrakturadong datos?
Oo, kaya ng neural networks na magtrabaho gamit ang hindi istrakturadong datos, at ito ang isa sa kanilang pinakamalalakas na kakayahan.
Ang mga artificial neural network na kayang magproseso ng hindi istrakturadong datos ay tinatawag na unsupervised learning algorithms. Ito ang itinuturing na banal na grail ng machine learning at mas malapit sa paraan ng pagkatuto ng tao.
Nahihirapan ang mga tradisyonal na algorithm ng machine learning na magproseso ng hindi istrukturadong datos dahil nangangailangan ito ng feature engineering — ang mano-manong pagpili at pagkuha ng mahahalagang katangian. Sa kabilang banda, kayang matutunan ng neural networks ang mga pattern sa hilaw na datos nang hindi na kailangan ng masyadong maraming manu-manong pakikialam.
Paano natututo ang deep neural networks sa pamamagitan ng training?
Natututo ang deep neural network sa pamamagitan ng paggawa ng mga prediksyon at paghahambing ng mga ito sa tamang sagot. Halimbawa, kapag nagpoproseso ng mga larawan, hinuhulaan nito kung may aso sa larawan at sinusubaybayan kung gaano kadalas tama ang sagot nito.
Kinakalkula ng network ang katumpakan nito sa pamamagitan ng pagtingin sa porsyento ng tamang prediksyon at ginagamit ang feedback na ito para gumaling pa. Ina-adjust nito ang mga timbang ng mga neuron at inuulit ang proseso. Kapag gumanda ang katumpakan, itinatago nito ang bagong timbang; kung hindi, sumusubok ito ng ibang adjustments.
Paulit-ulit ang siklong ito sa maraming ulit hanggang sa matutunan ng network na kilalanin ang mga pattern at makagawa ng tamang prediksyon nang tuloy-tuloy. Kapag narating na ito, sinasabing nag-converge na ang network at matagumpay nang na-train.
Makatipid ng oras sa pag-programa na may mas magagandang resulta
Tinawag itong neural network dahil may pagkakahawig ang paraang ito ng pag-programa sa paraan ng paggana ng utak.
Gaya ng utak, gumagamit ang neural net algorithms ng network ng mga neuron o node. At tulad ng utak, ang mga neuron na ito ay mga hiwalay na function (o parang maliliit na makina) na tumatanggap ng input at nagbibigay ng output. Nakaayos ang mga node na ito sa mga layer kung saan ang output ng mga neuron sa isang layer ay nagiging input sa mga neuron ng susunod na layer hanggang sa ang mga neuron sa pinakalabas na layer ng network ang magbigay ng huling resulta.
Kaya may mga layer ng mga neuron na bawat isa ay tumatanggap ng limitadong input at nagbibigay ng limitadong output, tulad ng sa utak. Ang unang layer (input layer) ng mga neuron ang tumatanggap ng input at ang huling layer ng mga neuron (output layer) sa network ang nagbibigay ng resulta.
Tama bang tawaging 'neural network' ang ganitong uri ng algorithm?
Naging epektibo ang pagtawag sa algorithm na ito bilang 'deep neural network' bilang branding, kahit na maaaring magdulot ito ng sobrang taas na inaasahan. Bagama't makapangyarihan, mas simple pa rin ang mga modelong ito kumpara sa komplikadong utak ng tao. Gayunpaman, patuloy na nagsasaliksik ang mga mananaliksik ng mga neural na arkitektura na naglalayong makamit ang pangkalahatan, mala-taong katalinuhan.
Gayunpaman, may mga taong sinusubukang muling likhain ang utak gamit ang napakakomplikadong neural network, umaasang sa pamamagitan nito ay magagaya nila ang pangkalahatan at mala-taong katalinuhan sa paggawa ng bot. Kaya paano nga ba nakakatulong ang neural net at mga teknik sa machine learning sa problema natin sa pagkilala ng aso?
Sa halip na manu-manong tukuyin ang mga katangian ng aso, ang deep neural network algorithm ay kayang tukuyin ang mahahalagang katangian at humawak ng lahat ng natatanging kaso nang hindi na kailangang isa-isang i-programa.
FAQs
1. Gaano katagal bago ma-train ang isang deep neural network?
Ang tagal ng training ng deep neural network ay nakadepende sa laki ng dataset at sa komplikasyon ng modelo. Ang simpleng modelo ay maaaring ma-train sa loob ng ilang minuto sa laptop, habang ang malalaking modelo tulad ng GPT o ResNet ay maaaring abutin ng ilang araw o linggo gamit ang high-performance na GPU o TPU.
2. Pwede ba akong mag-train ng DNN sa sarili kong computer?
Oo, maaari kang mag-train ng deep neural network sa personal na computer kung maliit lang ang dataset at simple ang modelo. Pero kung malaki ang modelo o malaki ang dataset, kakailanganin mo ng GPU-enabled na setup o access sa cloud platforms tulad ng AWS o Azure.
3. Ano ang pagkakaiba ng DNN na ginagamit sa computer vision at sa natural language processing?
Ang deep neural network na ginagamit sa computer vision ay gumagamit ng convolutional layers (CNNs) para iproseso ang pixel data, habang ang mga NLP model ay gumagamit ng mga architecture tulad ng transformers, LSTM, o RNN para hawakan ang sunud-sunod at semantikong estruktura ng wika. Parehong gumagamit ng deep learning pero iniangkop para sa magkaibang uri ng datos.
4. Paano pinipili ang bilang ng hidden layers sa isang DNN?
Ang pagpili ng bilang ng hidden layers sa DNN ay nangangailangan ng pagsubok — kapag masyadong kaunti, maaaring hindi matutunan nang husto ang datos; kapag masyadong marami, maaaring mag-overfit at bumagal ang training. Magsimula sa 1–3 layers para sa simpleng gawain at dagdagan ito nang paunti-unti, sabayan ng pag-validate ng performance gamit ang cross-validation o test set.
5. Ano ang mga susunod na malaking tagumpay na inaasahan sa pananaliksik sa deep neural network?
Kabilang sa mga susunod na malaking tagumpay sa pananaliksik sa deep neural network ang sparse neural networks (para bumaba ang gastos sa compute), neurosymbolic reasoning (pagsasama ng lohika at deep learning), mas pinahusay na interpretability techniques, at mas matipid sa enerhiya na mga architecture na ginagaya ang kahusayan ng utak ng tao (halimbawa, spiking neural networks).



