



- Una red neuronal profunda (DNN) es un sistema de aprendizaje automático formado por capas de nodos conectados que aprenden patrones en los datos para hacer predicciones.
- Las DNN pueden ajustar sus conexiones internas en función de errores pasados, mejorando su precisión con el tiempo mediante retropropagación.
- Los avances en la capacidad de cómputo y el acceso a grandes volúmenes de datos han hecho que las DNN sean prácticas para tareas con datos no estructurados como texto, imágenes y audio.
- Las DNN funcionan como “cajas negras”, donde a menudo no está claro cómo llegan a sus decisiones.
¿Qué es una red neuronal profunda?
Una red neuronal profunda (DNN) es un tipo de modelo de aprendizaje automático que imita cómo el cerebro humano procesa la información. A diferencia de los algoritmos tradicionales que siguen reglas predefinidas, las DNN pueden aprender patrones a partir de datos y hacer predicciones basadas en experiencias previas, igual que nosotros.
Las DNN son la base del aprendizaje profundo, impulsando aplicaciones como agentes de IA, reconocimiento de imágenes, asistentes de voz, chatbots de IA.
El mercado global de IA —incluyendo aplicaciones impulsadas por redes neuronales profundas— superará los 500 mil millones de dólares para 2027.
¿Qué es la arquitectura de una red neuronal?
El término “profunda” en DNN se refiere a la presencia de múltiples capas ocultas, lo que permite a la red reconocer patrones complejos.
Una red neuronal está compuesta por varias capas de nodos que reciben información de otras capas y generan una salida hasta llegar a un resultado final.
Una red neuronal consiste en capas de nodos (neuronas). Cada nodo recibe una entrada, la procesa y la envía a la siguiente capa.
- Capa de entrada: La primera capa que recibe los datos en bruto (por ejemplo, imágenes, texto).
- Capas ocultas: Capas entre la entrada y la salida que transforman los datos y detectan patrones.
- Capa de salida: Genera la predicción final.
Las redes neuronales pueden tener cualquier cantidad de capas ocultas: cuantas más capas de nodos tenga la red, mayor será su complejidad. Las redes neuronales tradicionales suelen tener 2 o 3 capas ocultas, mientras que las redes de aprendizaje profundo pueden llegar a tener hasta 150 capas ocultas.
¿En qué se diferencian las redes neuronales de las redes neuronales profundas?
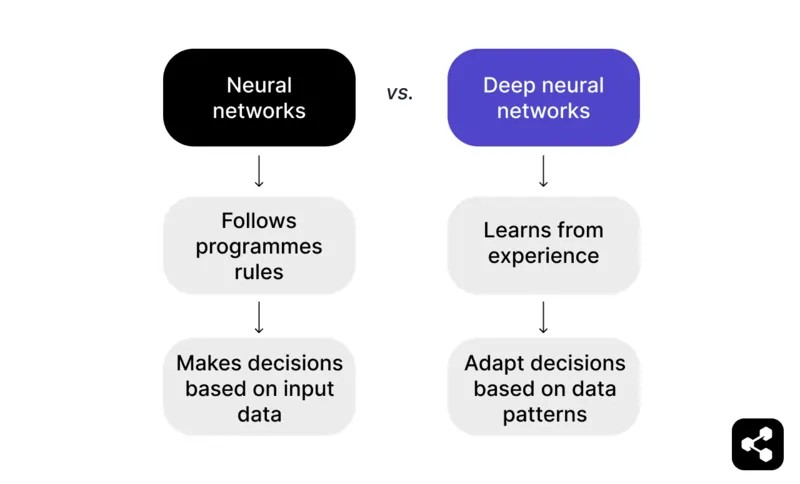
En resumen: una red neuronal que va más allá de los datos de entrada y puede aprender de experiencias previas se convierte en una red neuronal profunda.
Una red neuronal sigue reglas programadas para tomar decisiones basadas en los datos de entrada. Por ejemplo, en una partida de ajedrez, una red neuronal puede sugerir movimientos según tácticas y estrategias predefinidas, pero está limitada a lo que el programador ha proporcionado.
Pero una red neuronal profunda va más allá al aprender de la experiencia. En lugar de depender solo de reglas preestablecidas, una DNN puede ajustar sus decisiones según los patrones que reconoce en grandes conjuntos de datos.
Ejemplo
Imagina que escribes un programa para reconocer perros en fotos. Una red neuronal tradicional requeriría reglas explícitas para identificar características como el pelaje o la cola. Una DNN, en cambio, aprendería a partir de miles de imágenes etiquetadas y mejoraría su precisión con el tiempo, incluso en casos difíciles y sin programación adicional.
¿Cómo funciona una red neuronal profunda?
Primero, cada neurona en la capa de entrada recibe una parte de los datos en bruto, como los píxeles de una imagen o palabras de una frase, y asigna un peso a esa entrada, indicando qué tan relevante es para la tarea.
Un peso bajo (menor a 0.5) significa que es menos probable que la información sea relevante. Estas entradas ponderadas pasan por las capas ocultas, donde las neuronas ajustan la información aún más. Esto continúa a través de varias capas hasta que la capa de salida entrega una predicción final.
¿Cómo sabe una red neuronal profunda si acierta?
Una red neuronal profunda sabe si acierta comparando sus predicciones con datos etiquetados durante el entrenamiento. Para cada entrada, la red verifica si su predicción coincide con el resultado real. Si se equivoca, calcula el error usando una función de pérdida, que mide qué tan lejos estuvo la predicción.
Luego, la red utiliza la retropropagación para ajustar los pesos de las neuronas que contribuyeron al error. Este proceso se repite en cada iteración.
¿Cuáles son los diferentes tipos de redes neuronales?
¿Cómo mejora una red neuronal profunda con el tiempo?
Una red neuronal profunda mejora con el tiempo aprendiendo de sus errores. Cuando hace una predicción —como identificar un problema de cliente o recomendar un producto— verifica si acertó. Si no fue así, el sistema se ajusta para mejorar la próxima vez.
Por ejemplo, en atención al cliente, una DNN podría predecir cómo resolver un ticket. Si la predicción fue incorrecta, aprende de ese error y mejora al resolver casos similares en el futuro. En ventas, una DNN puede aprender qué oportunidades tienen más probabilidades de concretarse analizando acuerdos anteriores, mejorando sus recomendaciones con el tiempo.
Así, con cada interacción, la DNN se vuelve más precisa y confiable.
¿Las redes neuronales profundas piensan diferente a los humanos?
Pero los modelos de aprendizaje profundo suelen funcionar como una 'caja negra', lo que significa que las personas no pueden interpretar fácilmente cómo llegan a sus decisiones. Como explica la investigadora Cynthia Rudin de la Universidad de Duke , la interpretabilidad es fundamental para el uso ético de sistemas de IA, especialmente en entornos críticos.
Los investigadores han intentado visualizar cómo las redes procesan imágenes, pero para tareas más complejas —como el lenguaje o las predicciones financieras— la lógica sigue siendo desconocida. Aunque estos algoritmos parecen nuevos, muchos se desarrollaron hace décadas. Los avances en datos y capacidad de cómputo son los que los hacen prácticos hoy en día.
¿Por qué las redes neuronales profundas son cada vez más populares?
1. Mejoras en la capacidad de procesamiento
Una de las principales razones del auge de las DNN es que la capacidad de procesamiento es más rápida y económica. El poder de cómputo ha sido clave para lograr una convergencia rápida. “El surgimiento de hardware especializado como las Unidades de Procesamiento Gráfico (GPU) y las Unidades de Procesamiento Tensorial (TPU) ha hecho posible entrenar redes con miles de millones de parámetros.”
2. Mayor disponibilidad de conjuntos de datos
Otro factor clave es la disponibilidad de grandes conjuntos de datos, que las redes neuronales profundas necesitan para aprender de manera efectiva. A medida que las empresas generan más datos, las DNN pueden descubrir patrones complejos que los modelos tradicionales no pueden manejar.
3. Avances en el procesamiento de datos no estructurados
Su capacidad para procesar datos no estructurados como texto, imágenes y audio también ha abierto nuevas aplicaciones en áreas como chatbots, sistemas de recomendación y análisis predictivo.
¿Pueden las redes neuronales trabajar con datos no estructurados?
Sí, las redes neuronales pueden trabajar con datos no estructurados, y esta es una de sus mayores fortalezas.
Las redes neuronales artificiales que trabajan con datos no estructurados suelen emplear el aprendizaje no supervisado. Esto es el santo grial del aprendizaje automático y se asemeja más a cómo aprenden los humanos.
Los algoritmos tradicionales de aprendizaje automático tienen dificultades para procesar datos no estructurados porque requieren ingeniería de características: la selección y extracción manual de atributos relevantes. En cambio, las redes neuronales pueden aprender patrones en los datos sin necesidad de una intervención manual extensa.
¿Cómo aprenden las redes neuronales profundas durante el entrenamiento?
Una red neuronal profunda aprende haciendo predicciones y comparándolas con los resultados correctos. Por ejemplo, al analizar fotos, predice si una imagen contiene un perro y registra cuántas veces acierta.
La red calcula su precisión comprobando el porcentaje de aciertos y utiliza esa retroalimentación para mejorar. Ajusta los pesos de sus neuronas y repite el proceso. Si la precisión mejora, mantiene los nuevos pesos; si no, prueba otros ajustes.
Este ciclo se repite muchas veces hasta que la red logra reconocer patrones y hacer predicciones precisas de forma consistente. Cuando llega a este punto, se dice que la red ha convergido y está entrenada con éxito.
Ahorra tiempo de programación y obtén mejores resultados
La red neuronal recibe ese nombre porque su enfoque de programación es similar al funcionamiento del cerebro.
Al igual que el cerebro, los algoritmos de redes neuronales utilizan una red de neuronas o nodos. Y, como en el cerebro, estas neuronas son funciones discretas (o pequeñas máquinas, si se prefiere) que reciben entradas y generan salidas. Estos nodos se organizan en capas, de modo que las salidas de una capa se convierten en las entradas de la siguiente, hasta que las neuronas de la capa final generan el resultado.
Por lo tanto, existen capas de neuronas, donde cada neurona individual recibe entradas limitadas y genera salidas limitadas; igual que en el cerebro. La primera capa (o capa de entrada) recibe los datos y la última capa (o capa de salida) entrega el resultado final.
¿Es correcto llamar a este tipo de algoritmo una “red neuronal”?
Llamar a este algoritmo una 'red neuronal profunda' ha resultado ser una estrategia de marca efectiva, aunque puede generar expectativas demasiado altas. Si bien son potentes, estos modelos siguen siendo mucho más simples que la complejidad del cerebro humano. Sin embargo, los investigadores continúan explorando arquitecturas neuronales con el objetivo de lograr una inteligencia general similar a la humana.
Dicho esto, hay quienes intentan re-ingenierizar el cerebro utilizando redes neuronales muy complejas, con la esperanza de replicar una inteligencia general humana en el desarrollo de bots. Entonces, ¿cómo nos ayudan las redes neuronales y las técnicas de aprendizaje automático con nuestro problema de reconocimiento de perros?
En lugar de definir manualmente los atributos similares a los de un perro, un algoritmo de red neuronal profunda puede identificar los atributos importantes y manejar todos los casos especiales sin necesidad de programación.
Preguntas frecuentes
1. ¿Cuánto tiempo se tarda en entrenar una red neuronal profunda?
El tiempo necesario para entrenar una red neuronal profunda depende del tamaño del conjunto de datos y la complejidad del modelo. Un modelo sencillo puede entrenarse en minutos en una laptop, mientras que uno grande como GPT o ResNet puede tardar días o incluso semanas usando GPUs o TPUs de alto rendimiento.
2. ¿Puedo entrenar una red neuronal profunda en mi computadora personal?
Sí, puedes entrenar una red neuronal profunda en tu computadora personal si el conjunto de datos es pequeño y el modelo es relativamente simple. Sin embargo, para modelos grandes o datos voluminosos, necesitarás una configuración con GPU o acceso a plataformas en la nube como AWS o Azure.
3. ¿Cuál es la diferencia entre una red neuronal profunda usada en visión por computadora y una usada en procesamiento de lenguaje natural?
Una red neuronal profunda utilizada en visión por computadora emplea capas convolucionales (CNN) para procesar datos de píxeles, mientras que los modelos de PLN usan arquitecturas como transformers, LSTM o RNN para manejar la estructura secuencial y semántica del lenguaje. Ambos usan aprendizaje profundo, pero están optimizados para diferentes tipos de datos.
4. ¿Cómo se elige el número de capas ocultas en una red neuronal profunda?
Elegir el número de capas ocultas en una red neuronal profunda requiere experimentación: muy pocas pueden subajustar los datos, mientras que demasiadas pueden sobreajustar y ralentizar el entrenamiento. Comienza con 1–3 capas para tareas simples y aumenta gradualmente, validando el rendimiento con validación cruzada o un conjunto de prueba.
5. ¿Cuáles son los próximos grandes avances esperados en la investigación de redes neuronales profundas?
Los próximos avances en la investigación de redes neuronales profundas incluyen redes neuronales dispersas (que reducen el costo computacional), razonamiento neurosimbólico (que combina lógica con aprendizaje profundo), mejores técnicas de interpretabilidad y arquitecturas más eficientes energéticamente que imitan la eficiencia del cerebro humano (por ejemplo, redes neuronales de picos).



