



- Głęboka sieć neuronowa (DNN) to system uczenia maszynowego zbudowany z warstw połączonych węzłów, które uczą się wzorców w danych, aby dokonywać predykcji.
- DNN mogą dostosowywać swoje wewnętrzne połączenia na podstawie wcześniejszych błędów, zwiększając swoją dokładność z czasem dzięki mechanizmowi wstecznej propagacji błędów.
- Postęp w mocy obliczeniowej i dostęp do ogromnych zbiorów danych sprawiły, że DNN stały się praktyczne w zadaniach związanych z nieustrukturyzowanymi danymi, takimi jak tekst, obrazy czy dźwięk.
- DNN działają jak „czarne skrzynki”, w których często nie wiadomo, jak podejmują decyzje.
Czym jest głęboka sieć neuronowa?
Głęboka sieć neuronowa (DNN) to rodzaj modelu uczenia maszynowego, który naśladuje sposób, w jaki ludzki mózg przetwarza informacje. W przeciwieństwie do tradycyjnych algorytmów opartych na z góry ustalonych regułach, DNN potrafią uczyć się wzorców z danych i przewidywać na podstawie wcześniejszych doświadczeń — tak jak my.
DNN są podstawą deep learningu i napędzają takie zastosowania jak agenci AI, rozpoznawanie obrazów, asystenci głosowi, czatboty AI.
Globalny rynek AI — obejmujący aplikacje oparte na głębokich sieciach neuronowych — przekroczy 500 miliardów dolarów do 2027 roku.
Czym jest architektura sieci neuronowej?
„Głębia” w DNN odnosi się do wielu ukrytych warstw, które pozwalają sieci rozpoznawać złożone wzorce.
Sieć neuronowa składa się z wielu warstw węzłów, które otrzymują dane wejściowe z innych warstw i generują wynik, aż do uzyskania ostatecznego rezultatu.
Sieć neuronowa to warstwy węzłów (neuronów). Każdy węzeł przyjmuje dane wejściowe, przetwarza je i przekazuje do kolejnej warstwy.
- Warstwa wejściowa: Pierwsza warstwa, która przyjmuje surowe dane (np. obrazy, tekst).
- Warstwy ukryte: Warstwy pomiędzy wejściem a wyjściem, które przekształcają dane i wykrywają wzorce.
- Warstwa wyjściowa: Generuje końcową predykcję.
Sieci neuronowe mogą mieć dowolną liczbę warstw ukrytych: im więcej warstw w sieci, tym większa jej złożoność. Tradycyjne sieci neuronowe zwykle mają 2 lub 3 warstwy ukryte, podczas gdy sieci głębokiego uczenia mogą mieć nawet do 150 warstw ukrytych.
Czym różnią się sieci neuronowe od głębokich sieci neuronowych?
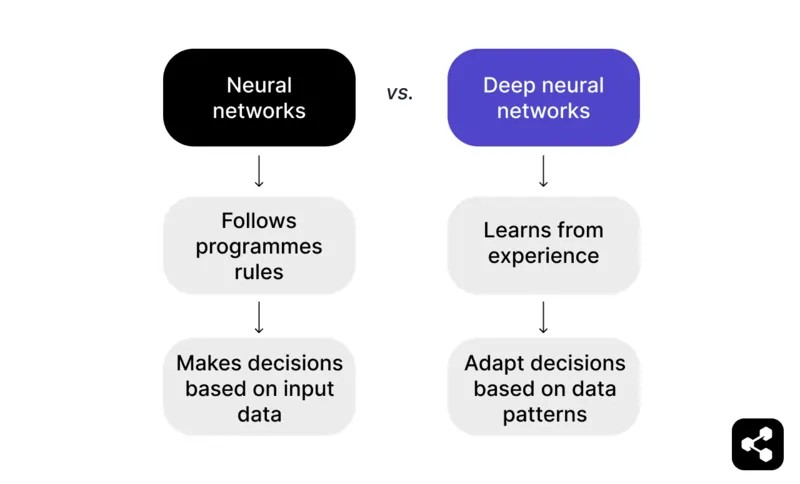
W skrócie: Sieć neuronowa, która wykracza poza dane wejściowe i potrafi uczyć się na podstawie wcześniejszych doświadczeń, staje się głęboką siecią neuronową.
Sieć neuronowa działa według zaprogramowanych reguł, aby podejmować decyzje na podstawie danych wejściowych. Na przykład w grze w szachy sieć neuronowa może sugerować ruchy na podstawie ustalonych taktyk i strategii, ale jest ograniczona do tego, co zaprogramował twórca.
Natomiast głęboka sieć neuronowa idzie dalej, ucząc się na podstawie doświadczenia. Zamiast polegać wyłącznie na ustalonych regułach, DNN potrafi dostosowywać swoje decyzje na podstawie wzorców rozpoznanych w dużych zbiorach danych.
Przykład
Wyobraź sobie program do rozpoznawania psów na zdjęciach. Tradycyjna sieć neuronowa wymagałaby jasno określonych reguł do identyfikacji cech, takich jak sierść czy ogon. DNN natomiast uczy się na podstawie tysięcy oznaczonych zdjęć i z czasem poprawia swoją dokładność — radząc sobie nawet z trudnymi przypadkami bez dodatkowego programowania.
Jak działa głęboka sieć neuronowa?
Najpierw każdy neuron w warstwie wejściowej otrzymuje fragment surowych danych, takich jak piksele z obrazu lub słowa z tekstu, i przypisuje temu wejściu wagę, określając jego znaczenie dla zadania.
Niska waga (poniżej 0,5) oznacza, że informacja jest mniej istotna. Te ważone dane przechodzą przez warstwy ukryte, gdzie neurony dalej je przetwarzają. Proces ten powtarza się przez kolejne warstwy, aż warstwa wyjściowa wygeneruje końcową predykcję.
Skąd głęboka sieć neuronowa wie, czy ma rację?
Głęboka sieć neuronowa sprawdza poprawność swoich predykcji, porównując je z oznaczonymi danymi podczas treningu. Dla każdego wejścia sieć sprawdza, czy jej przewidywanie zgadza się z rzeczywistym wynikiem. Jeśli się myli, oblicza błąd za pomocą funkcji straty, która mierzy, jak bardzo wynik odbiega od prawdy.
Następnie sieć wykorzystuje wsteczną propagację błędów, aby dostosować wagi neuronów, które przyczyniły się do błędu. Proces ten powtarza się przy każdej iteracji.
Jakie są rodzaje sieci neuronowych?
Jak głęboka sieć neuronowa uczy się z czasem?
Głęboka sieć neuronowa uczy się z czasem, wyciągając wnioski ze swoich błędów. Gdy dokonuje predykcji — na przykład rozpoznaje problem klienta lub rekomenduje produkt — sprawdza, czy miała rację. Jeśli nie, system dostosowuje się, by następnym razem być skuteczniejszym.
Na przykład w obsłudze klienta DNN może przewidzieć sposób rozwiązania zgłoszenia. Jeśli się pomyli, uczy się na tym błędzie i w przyszłości lepiej rozwiązuje podobne sprawy. W sprzedaży DNN może analizować, które leady najlepiej się konwertują, i z czasem poprawiać swoje rekomendacje.
Dzięki każdej interakcji DNN staje się coraz dokładniejsza i bardziej niezawodna.
Czy głębokie sieci neuronowe myślą inaczej niż ludzie?
Jednak modele deep learningu często działają jak „czarna skrzynka”, co oznacza, że ludzie nie mogą łatwo zrozumieć, jak podejmują decyzje. Jak wyjaśnia badaczka AI Cynthia Rudin z Duke University , interpretowalność jest kluczowa dla etycznego wdrażania systemów AI, zwłaszcza w sytuacjach o dużym znaczeniu.
Naukowcy próbowali wizualizować, jak sieci przetwarzają obrazy, ale w bardziej złożonych zadaniach — takich jak język czy prognozy finansowe — logika pozostaje ukryta. Choć te algorytmy wydają się nowe, wiele z nich powstało dekady temu. To rozwój danych i mocy obliczeniowej sprawił, że dziś są praktyczne.
Dlaczego głębokie sieci neuronowe zyskują na popularności?
1. Postęp w mocy obliczeniowej
Jednym z głównych powodów wzrostu popularności DNN jest szybsza i tańsza moc obliczeniowa. To właśnie moc obliczeniowa umożliwiła szybkie osiąganie dobrych wyników. „Pojawienie się wyspecjalizowanego sprzętu, takiego jak procesory graficzne (GPU) i jednostki przetwarzania tensorowego (TPU), sprawiło, że możliwe stało się trenowanie sieci z miliardami parametrów.”
2. Rosnąca dostępność zbiorów danych
Kolejnym kluczowym czynnikiem jest dostępność dużych zbiorów danych, które są niezbędne do skutecznej nauki głębokich sieci neuronowych. Wraz ze wzrostem ilości danych generowanych przez firmy, DNN mogą odkrywać złożone wzorce, których tradycyjne modele nie są w stanie wykryć.
3. Postęp w przetwarzaniu nieustrukturyzowanych danych
Ich zdolność do przetwarzania nieustrukturyzowanych danych, takich jak tekst, obrazy czy dźwięk, otworzyła nowe możliwości w obszarach takich jak czatboty, systemy rekomendacji czy analityka predykcyjna.
Czy sieci neuronowe mogą pracować z nieustrukturyzowanymi danymi?
Tak, sieci neuronowe mogą pracować z nieustrukturyzowanymi danymi i jest to jedna z ich największych zalet.
Sieci neuronowe, które pracują z nieustrukturyzowanymi danymi, często wykorzystują uczenie nienadzorowane. To swego rodzaju „święty Graal” uczenia maszynowego i bardziej przypomina sposób, w jaki uczą się ludzie.
Tradycyjne algorytmy uczenia maszynowego mają trudności z przetwarzaniem nieustrukturyzowanych danych, ponieważ wymagają ręcznego wyboru i wydobywania istotnych cech. Z kolei sieci neuronowe potrafią automatycznie uczyć się wzorców z surowych danych bez dużej ingerencji człowieka.
Jak głębokie sieci neuronowe uczą się podczas treningu?
Głęboka sieć neuronowa uczy się, dokonując prognoz i porównując je z prawidłowymi wynikami. Na przykład podczas analizy zdjęć przewiduje, czy na obrazie jest pies, i śledzi, jak często udaje jej się poprawnie odpowiedzieć.
Sieć oblicza swoją skuteczność, sprawdzając procent poprawnych przewidywań i wykorzystuje tę informację do ulepszania działania. Dostosowuje wagi swoich neuronów i powtarza proces. Jeśli skuteczność rośnie, zachowuje nowe wagi; jeśli nie, próbuje innych zmian.
Ten cykl powtarza się wielokrotnie, aż sieć zacznie konsekwentnie rozpoznawać wzorce i trafnie przewidywać wyniki. Gdy osiągnie ten poziom, mówi się, że sieć się zbieGŁA i jest skutecznie wytrenowana.
Oszczędzaj czas na kodowaniu i osiągaj lepsze rezultaty
Sieć neuronowa zawdzięcza swoją nazwę podobieństwu tej metody programowania do sposobu działania ludzkiego mózgu.
Podobnie jak mózg, algorytmy sieci neuronowych wykorzystują sieć neuronów lub węzłów. I tak jak w mózgu, te neurony to odrębne funkcje (albo małe maszyny, jeśli wolisz), które przyjmują dane wejściowe i generują wyjścia. Węzły są ułożone warstwowo — wyjścia neuronów z jednej warstwy stają się wejściami dla neuronów w kolejnej, aż neurony w zewnętrznej warstwie sieci wygenerują końcowy wynik.
Istnieją więc warstwy neuronów, z których każdy pojedynczy neuron otrzymuje bardzo ograniczone dane wejściowe i generuje bardzo ograniczone wyjścia, podobnie jak w mózgu. Pierwsza warstwa (warstwa wejściowa) neuronów przyjmuje dane wejściowe, a ostatnia warstwa neuronów (warstwa wyjściowa) w sieci zwraca wynik.
Czy określenie tego typu algorytmu jako „sieć neuronowa” jest trafne?
Nazywanie tego algorytmu „głęboką siecią neuronową” okazało się skutecznym zabiegiem marketingowym, choć może budzić zbyt wygórowane oczekiwania. Mimo swojej mocy, te modele są wciąż znacznie prostsze niż ludzki mózg. Niemniej jednak, badacze stale poszukują architektur sieci neuronowych, które pozwolą osiągnąć ogólną, ludzkopodobną inteligencję.
Warto dodać, że są osoby próbujące odtworzyć mózg, wykorzystując bardzo złożone sieci neuronowe, licząc na to, że dzięki temu uda się uzyskać ogólną, ludzkopodobną inteligencję w rozwoju botów. Jak więc sieci neuronowe i techniki uczenia maszynowego pomagają nam w rozpoznawaniu psów?
Zamiast ręcznie definiować cechy charakterystyczne dla psa, algorytm głębokiej sieci neuronowej potrafi wykryć istotne cechy i radzić sobie ze wszystkimi wyjątkami bez programowania.
Najczęstsze pytania
1. Ile trwa trenowanie głębokiej sieci neuronowej?
Czas potrzebny na wytrenowanie głębokiej sieci neuronowej zależy od wielkości zbioru danych i złożoności modelu. Prosty model można wytrenować w kilka minut na laptopie, natomiast duże modele, takie jak GPT czy ResNet, mogą wymagać dni lub nawet tygodni pracy na wydajnych GPU lub TPU.
2. Czy mogę trenować głęboką sieć neuronową na własnym komputerze?
Tak, możesz trenować głęboką sieć neuronową na swoim komputerze, jeśli zbiór danych jest niewielki, a model stosunkowo prosty. Jednak do trenowania dużych modeli lub pracy z dużymi zbiorami danych potrzebny będzie komputer z kartą graficzną lub dostęp do chmury, np. AWS czy Azure.
3. Czym różni się DNN stosowana w wizji komputerowej od tej używanej w przetwarzaniu języka naturalnego?
Głęboka sieć neuronowa wykorzystywana w wizji komputerowej korzysta z warstw konwolucyjnych (CNN) do przetwarzania danych pikselowych, natomiast modele do przetwarzania języka naturalnego wykorzystują architektury takie jak transformatory, LSTM lub RNN, aby analizować sekwencje i strukturę semantyczną języka. Obie korzystają z uczenia głębokiego, ale są zoptymalizowane pod różne typy danych.
4. Jak wybrać liczbę warstw ukrytych w DNN?
Dobór liczby warstw ukrytych w DNN wymaga eksperymentowania — zbyt mało warstw może prowadzić do niedouczenia modelu, a zbyt wiele do przeuczenia i spowolnienia treningu. Przy prostych zadaniach warto zacząć od 1–3 warstw i stopniowo zwiększać ich liczbę, sprawdzając wyniki na zbiorze walidacyjnym lub testowym.
5. Jakie są przewidywane przełomy w badaniach nad głębokimi sieciami neuronowymi?
Przyszłe przełomy w badaniach nad głębokimi sieciami neuronowymi obejmują sieci neuronowe o rzadkiej strukturze (zmniejszające koszty obliczeniowe), neurosymboliczne rozumowanie (łączące logikę z uczeniem głębokim), lepsze techniki interpretacji oraz bardziej energooszczędne architektury inspirowane wydajnością ludzkiego mózgu (np. sieci neuronowe z impulsami).



