



- ディープニューラルネットワーク(DNN)は、複数の層で構成されたノードがデータ内のパターンを学習し、予測を行う機械学習システムです。
- DNNは過去の誤りをもとに内部の接続を調整し、バックプロパゲーションによって時間とともに精度を高めていきます。
- 計算能力の向上と大規模データセットへのアクセスが可能になったことで、DNNはテキスト・画像・音声などの非構造化データを扱うタスクでも実用的になりました。
- DNNは“ブラックボックス”として動作し、どのように判断に至ったかが分かりにくいことが多いです。
ディープニューラルネットワークとは?
ディープニューラルネットワーク(DNN)は、人間の脳が情報を処理する仕組みを模倣した機械学習モデルです。従来のアルゴリズムが決められたルールに従うのに対し、DNNはデータからパターンを学び、過去の経験をもとに予測を行います——まるで私たちのように。
DNNはディープラーニングの基盤であり、AIエージェント、画像認識、音声アシスタント、AIチャットボットなどのアプリケーションを支えています。
ディープニューラルネットワークを活用したアプリケーションを含む世界のAI市場は、2027年までに5,000億ドルを超える見込みです。
ニューラルネットワークアーキテクチャとは?
DNNの“ディープ”とは、複数の隠れ層を持つことで、より複雑なパターンを認識できることを指します。
ニューラルネットワークは、複数のノード層で構成され、各層が他の層から入力を受け取り、最終的な出力が得られるまで処理を繰り返します。
ニューラルネットワークはノード(ニューロン)の層で構成されます。各ノードは入力を受け取り、処理し、次の層へ渡します。
- 入力層:最初の層で、生データ(例:画像やテキスト)を受け取ります。
- 隠れ層:入力と出力の間にあり、データを変換しパターンを検出します。
- 出力層:最終的な予測結果を出します。
ニューラルネットワークは隠れ層の数に制限はありません。ノードの層が多いほど、ネットワークの複雑さが増します。従来型のニューラルネットワークは通常2~3層ですが、ディープラーニングネットワークは最大150層にもなります。
ニューラルネットワークとディープニューラルネットワークの違いは?
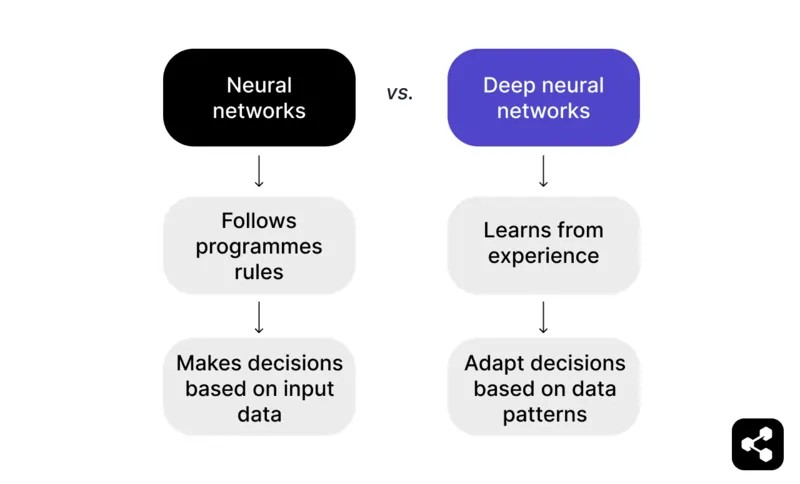
要するに、入力データを超えて過去の経験から学習できるニューラルネットワークが、ディープニューラルネットワークとなります。
ニューラルネットワークは、入力データに基づきプログラムされたルールで判断します。例えばチェスのゲームでは、あらかじめ設定された戦術や戦略に基づいて手を提案できますが、プログラマーが用意した範囲に限られます。
一方、ディープニューラルネットワークは経験から学びます。あらかじめ決められたルールだけでなく、大規模なデータセットから認識したパターンをもとに判断を調整できます。
例
写真から犬を認識するプログラムを作るとします。従来のニューラルネットワークでは、毛やしっぽなどの特徴を明示的にルール化する必要があります。一方DNNは、何千枚ものラベル付き画像から学習し、時間とともに精度を高め、追加のプログラミングなしでも難しいケースに対応できます。
ディープニューラルネットワークはどのように動作するのか?
まず、入力層の各ニューロンが画像のピクセルや文章の単語など生データの一部を受け取り、その入力がどれだけ重要かを示す重みを割り当てます。
重みが低い(0.5未満)場合、その情報が重要でない可能性が高いことを意味します。これらの重み付き入力は隠れ層を通過し、ニューロンがさらに情報を調整します。これが複数の層で繰り返され、最終的に出力層が予測結果を出します。
ディープニューラルネットワークはどうやって正解を知るのか?
ディープニューラルネットワークは、学習時に予測結果とラベル付きデータを比較することで正解かどうかを判断します。各入力ごとに、予測が実際の結果と一致するかを確認します。間違っていた場合は、損失関数を使ってどれだけ外れていたか(誤差)を計算します。
その後、ネットワークはバックプロパゲーションを使い、誤差に関与したニューロンの重みを調整します。このプロセスを繰り返します。
ニューラルネットワークの種類にはどんなものがある?
ディープニューラルネットワークはどのようにして進化するのか?
ディープニューラルネットワークは、間違いから学ぶことで進化します。例えば、顧客の課題を特定したり商品を推薦したりする際、予測が正しかったかどうかを確認し、間違っていれば次回のためにシステムが自動で調整します。
たとえばカスタマーサポートでは、DNNがチケットの解決方法を予測します。予測が間違っていた場合、その失敗から学習し、今後同様のチケットの解決精度が向上します。営業では、過去の成約データを分析してどのリードが成約しやすいかを学び、推薦の精度を高めていきます。
このように、やりとりを重ねるごとにDNNはより正確で信頼できるものになります。
ディープニューラルネットワークは人間と異なる考え方をするのか?
しかし、ディープラーニングモデルはしばしば“ブラックボックス”として機能し、人間がどのように判断に至ったかを簡単に解釈できません。デューク大学のAI研究者シンシア・ルディン氏が説明しているように、特に重要な場面でAIを倫理的に運用するには解釈性が不可欠です。
研究者たちはネットワークが画像をどのように処理するかを可視化しようと試みていますが、言語や金融予測のような複雑なタスクでは、そのロジックは依然として不明です。これらのアルゴリズムは新しいものに感じられますが、多くは数十年前に開発されており、データと計算能力の進歩によって実用化されています。
ディープニューラルネットワークが普及している理由は?
1. 処理能力の向上
DNNが急速に普及した主な理由のひとつは、処理能力が向上し、コストも下がったことです。計算能力の進歩が高速な収束を実現しました。「GPUやTPUなどの専用ハードウェアの登場により、数十億のパラメータを持つネットワークの学習が現実的になりました。」
2. データセットの増加
もうひとつの重要な要因は、大規模なデータセットが利用可能になったことです。DNNは効果的に学習するために大量のデータを必要とします。企業がより多くのデータを生み出すことで、DNNは従来モデルでは扱えなかった複雑なパターンも発見できるようになりました。
3. 非構造化データ処理の進歩
テキスト・画像・音声など非構造化データを処理できる能力も、チャットボットやレコメンドシステム、予測分析など新たな用途を切り開いています。
ニューラルネットワークは非構造化データにも対応できるのか?
はい、ニューラルネットワークは非構造化データにも対応でき、これが最大の強みのひとつです。
非構造化データを扱う人工ニューラルネットワークは教師なし学習と呼ばれます。これは機械学習の究極の目標であり、人間の学習方法にも近いものです。
従来の機械学習アルゴリズムは、特徴量エンジニアリング(関連する特徴量を手作業で選択・抽出する作業)が必要なため、非構造化データの処理が苦手です。一方、ニューラルネットワークは、生データからパターンを自動的に学習でき、手作業による介入を大幅に減らせます。
ディープニューラルネットワークは、どのようにして学習するのですか?
ディープニューラルネットワークは、予測を行い、その結果を正解と比較することで学習します。たとえば、写真を処理する場合、画像に犬が写っているかどうかを予測し、その正答率を記録します。
ネットワークは、正解率(予測が正しかった割合)を計算し、そのフィードバックをもとに改善します。各ニューロンの重みを調整し、再度処理を行います。正解率が上がれば新しい重みを維持し、上がらなければ別の調整を試します。
このサイクルを何度も繰り返すことで、ネットワークはパターンを安定して認識し、正確な予測ができるようになります。この状態に達すると、ネットワークは「収束した」とされ、十分に学習できたことになります。
より良い結果でコーディング時間を短縮
ニューラルネットワークという名前は、このプログラミング手法と脳の働き方に類似点があることに由来しています。
脳と同様に、ニューラルネットワークのアルゴリズムもニューロン(ノード)のネットワークを使います。そして脳と同じく、これらのニューロンは入力を受け取り、出力を生成する個別の関数(あるいは小さな機械)として働きます。これらのノードは層状に配置され、一つの層のニューロンの出力が次の層のニューロンへの入力となり、最終的にネットワークの外側の層のニューロンが最終結果を出力します。
このように、複数のニューロン層があり、それぞれのニューロンは限られた入力を受け取り、限られた出力を生成します。最初の層(入力層)のニューロンが入力を受け取り、最後の層(出力層)のニューロンが結果を出力します。
このタイプのアルゴリズムを「ニューラルネットワーク」と呼ぶのは正確なのでしょうか?
このアルゴリズムを「ディープニューラルネットワーク」と呼ぶのは効果的なブランディングですが、過度な期待を抱かせることもあります。強力ではありますが、これらのモデルは人間の脳の複雑さに比べればまだ非常に単純です。それでも、研究者たちは一般的で人間のような知能を目指してニューラルアーキテクチャの研究を続けています。
とはいえ、非常に複雑なニューラルネットワークを使って脳を再現しようとする人もおり、これによって人間のような汎用知能をボット開発で再現できるのではないかと期待されています。では、ニューラルネットや機械学習の手法は、犬の認識問題にどのように役立つのでしょうか?
手作業で犬らしい特徴を定義する代わりに、ディープニューラルネットワークのアルゴリズムは重要な特徴を自動的に見つけ、特別なケースにも対応できます。
よくある質問
1. ディープニューラルネットワークの学習にはどれくらい時間がかかりますか?
ディープニューラルネットワークの学習時間は、データセットの大きさやモデルの複雑さによって異なります。シンプルなモデルならノートパソコンでも数分で学習できますが、GPTやResNetのような大規模モデルの場合、高性能なGPUやTPUを使っても数日から数週間かかることもあります。
2. 個人のパソコンでDNNを学習できますか?
はい、小規模なデータセットや比較的シンプルなモデルであれば、個人のパソコンでもディープニューラルネットワークを学習できます。ただし、大規模なモデルや大量のデータを扱う場合は、GPU対応の環境やAWSやAzureなどのクラウドプラットフォームが必要になります。
3. コンピュータビジョン用のDNNと自然言語処理用のDNNの違いは何ですか?
コンピュータビジョン用のディープニューラルネットワークは、畳み込み層(CNN)を使ってピクセルデータを処理します。一方、自然言語処理(NLP)モデルは、トランスフォーマーやLSTM、RNNなどのアーキテクチャを使い、言語の順序や意味構造を扱います。どちらもディープラーニングを使いますが、最適化されているデータの種類が異なります。
4. DNNの隠れ層の数はどうやって決めるのですか?
DNNの隠れ層の数は試行錯誤で決めます。層が少なすぎるとデータに合わず、層が多すぎると過学習や学習の遅延につながります。シンプルなタスクなら1~3層から始め、クロスバリデーションやテストセットで性能を確認しながら徐々に増やしていきます。
5. ディープニューラルネットワーク研究の今後の大きなブレークスルーは何ですか?
今後期待されるディープニューラルネットワーク研究のブレークスルーには、計算コストを削減するスパースニューラルネットワーク、論理とディープラーニングを組み合わせたニューロシンボリック推論、解釈性の向上技術、人間の脳の効率性を模倣したより省エネルギーなアーキテクチャ(例:スパイキングニューラルネットワーク)などがあります。



