



- Een deep neural network (DNN) is een machine learning-model dat bestaat uit lagen van verbonden knooppunten die patronen in data leren om voorspellingen te doen.
- DNN's kunnen hun interne verbindingen aanpassen op basis van eerdere fouten, waardoor hun nauwkeurigheid verbetert via backpropagation.
- Door vooruitgang in rekenkracht en toegang tot enorme datasets zijn DNN's praktisch geworden voor taken met ongestructureerde data zoals tekst, afbeeldingen en audio.
- DNN's werken als 'black boxes', waarbij het vaak onduidelijk is hoe ze tot hun beslissingen komen.
Wat is een deep neural network?
Een deep neural network (DNN) is een type machine learning-model dat nabootst hoe het menselijk brein informatie verwerkt. In tegenstelling tot traditionele algoritmes die vooraf bepaalde regels volgen, kunnen DNN's patronen leren uit data en voorspellingen doen op basis van eerdere ervaringen — net als wij.
DNN's vormen de basis van deep learning en drijven toepassingen aan zoals AI-agents, beeldherkenning, spraakassistenten, AI-chatbots.
De wereldwijde AI-markt — inclusief toepassingen die gebruikmaken van deep neural networks — zal in 2027 meer dan $500 miljard bedragen.
Wat is neurale netwerkarchitectuur?
Het 'deep' in DNN verwijst naar het gebruik van meerdere verborgen lagen, waardoor het netwerk complexe patronen kan herkennen.
Een neuraal netwerk bestaat uit meerdere lagen knooppunten die input ontvangen van andere lagen en een output genereren totdat het eindresultaat is bereikt.
Een neuraal netwerk bestaat uit lagen van knooppunten (neuronen). Elk knooppunt ontvangt een input, verwerkt deze en geeft het door aan de volgende laag.
- Inputlaag: De eerste laag die ruwe data ontvangt (bijv. afbeeldingen, tekst).
- Verborgen lagen: Lagen tussen input en output die data transformeren en patronen detecteren.
- Outputlaag: Geeft de uiteindelijke voorspelling.
Neurale netwerken kunnen een willekeurig aantal verborgen lagen hebben: hoe meer lagen, hoe groter de complexiteit. Traditionele neurale netwerken bestaan meestal uit 2 of 3 verborgen lagen, terwijl deep learning-netwerken tot wel 150 verborgen lagen kunnen hebben.
Hoe verschillen neurale netwerken van deep neural networks?
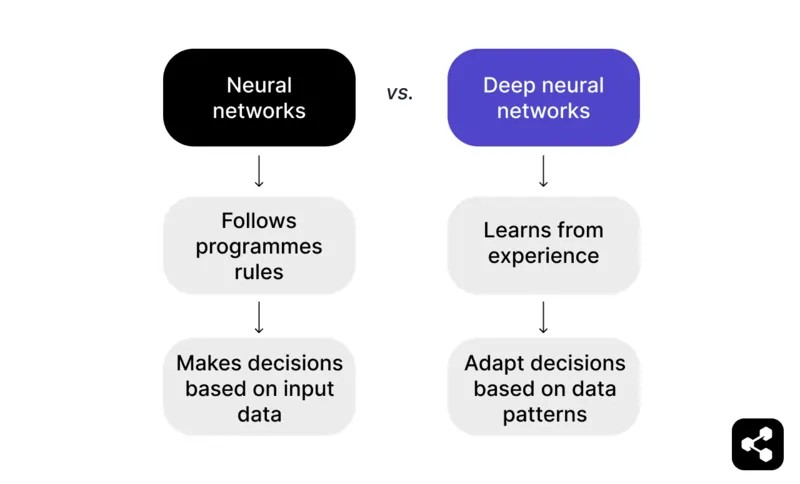
Kort gezegd: een neuraal netwerk dat verder gaat dan alleen inputdata en leert van eerdere ervaringen, wordt een deep neural network.
Een neuraal netwerk volgt geprogrammeerde regels om beslissingen te nemen op basis van inputdata. In een schaakspel kan een neuraal netwerk bijvoorbeeld zetten voorstellen op basis van vooraf ingestelde tactieken en strategieën, maar het is beperkt tot wat de programmeur heeft opgegeven.
Maar een deep neural network gaat verder door te leren van ervaring. In plaats van alleen op vaste regels te vertrouwen, kan een DNN zijn beslissingen aanpassen op basis van patronen die het herkent in grote datasets.
Voorbeeld
Stel je voor dat je een programma schrijft om honden op foto's te herkennen. Een traditioneel neuraal netwerk zou expliciete regels nodig hebben om kenmerken zoals vacht of staarten te identificeren. Een DNN daarentegen leert van duizenden gelabelde afbeeldingen en verbetert zijn nauwkeurigheid in de loop van de tijd — zelfs bij lastige gevallen, zonder extra programmering.
Hoe werkt een deep neural network?
Eerst ontvangt elk neuron in de inputlaag een stukje ruwe data, zoals pixels uit een afbeelding of woorden uit een zin, en kent hieraan een gewicht toe dat aangeeft hoe relevant deze input is voor de taak.
Een laag gewicht (minder dan 0,5) betekent dat de informatie waarschijnlijk minder relevant is. Deze gewogen inputs worden doorgegeven aan verborgen lagen, waar neuronen de informatie verder aanpassen. Dit proces herhaalt zich over meerdere lagen tot de outputlaag een uiteindelijke voorspelling geeft.
Hoe weet een deep neural network of het juist is?
Een deep neural network weet of het juist is door zijn voorspellingen te vergelijken met gelabelde data tijdens het trainen. Voor elke input controleert het netwerk of zijn voorspelling overeenkomt met het werkelijke resultaat. Als het fout is, berekent het netwerk de fout met een verliesfunctie, die meet hoe ver de voorspelling afwijkt.
Het netwerk gebruikt vervolgens backpropagation om de gewichten van de neuronen die bijgedragen hebben aan de fout aan te passen. Dit proces wordt bij elke iteratie herhaald.
Wat zijn de verschillende soorten neurale netwerken?
Hoe verbetert een deep neural network zichzelf?
Een deep neural network verbetert zichzelf in de loop van de tijd door te leren van zijn fouten. Wanneer het een voorspelling doet — zoals het identificeren van een klantprobleem of het aanbevelen van een product — controleert het of het juist was. Als dat niet zo is, past het systeem zich aan om het de volgende keer beter te doen.
In klantenservice kan een DNN bijvoorbeeld voorspellen hoe een ticket opgelost moet worden. Als de voorspelling fout was, leert het van die fout en wordt het beter in het oplossen van vergelijkbare tickets in de toekomst. In sales kan een DNN leren welke leads het beste converteren door eerdere deals te analyseren, waardoor zijn aanbevelingen steeds beter worden.
Met elke interactie wordt het DNN dus nauwkeuriger en betrouwbaarder.
Denken deep neural networks anders dan mensen?
Maar deep learning-modellen functioneren vaak als een 'black box', wat betekent dat mensen niet eenvoudig kunnen achterhalen hoe ze tot hun beslissingen komen. Zoals AI-onderzoeker Cynthia Rudin van Duke University uitlegt, is uitlegbaarheid cruciaal voor het ethisch inzetten van AI-systemen, vooral in situaties met grote gevolgen.
Onderzoekers hebben geprobeerd te visualiseren hoe netwerken afbeeldingen verwerken, maar bij complexere taken — zoals taal of financiële voorspellingen — blijft de logica verborgen. Hoewel deze algoritmes nieuw lijken, zijn veel ervan decennia geleden ontwikkeld. Het zijn de vooruitgang in data en rekenkracht die ze nu praktisch maken.
Waarom worden deep neural networks steeds populairder?
1. Verbeteringen in rekenkracht
Een van de belangrijkste redenen voor de opkomst van DNN's is dat rekenkracht sneller en goedkoper is geworden. Dankzij deze rekenkracht kunnen netwerken snel tot goede resultaten komen. “De opkomst van gespecialiseerde hardware zoals Graphics Processing Units (GPU's) en Tensor Processing Units (TPU's) maakt het mogelijk om netwerken met miljarden parameters te trainen.”
2. Toenemende beschikbaarheid van datasets
Een andere belangrijke factor is de beschikbaarheid van grote datasets, die deep neural networks nodig hebben om effectief te leren. Naarmate bedrijven meer data genereren, kunnen DNN's complexe patronen ontdekken die traditionele modellen niet aankunnen.
3. Verbeteringen in het verwerken van ongestructureerde data
Hun vermogen om ongestructureerde data zoals tekst, afbeeldingen en audio te verwerken, heeft ook nieuwe toepassingen mogelijk gemaakt, zoals chatbots, aanbevelingssystemen en voorspellende analyses.
Kunnen neurale netwerken werken met ongestructureerde data?
Ja, neurale netwerken kunnen werken met ongestructureerde data, en dit is een van hun grootste sterke punten.
Kunstmatige neurale netwerken die werken met ongestructureerde data maken gebruik van unsupervised learning. Dit wordt beschouwd als de heilige graal van machine learning en is meer vergelijkbaar met hoe mensen leren.
Traditionele machine learning-algoritmes hebben moeite met het verwerken van ongestructureerde data omdat ze feature engineering vereisen — het handmatig selecteren en extraheren van relevante kenmerken. Daarentegen kunnen neurale netwerken automatisch patronen herkennen in ruwe data zonder veel handmatige tussenkomst.
Hoe leren diepe neurale netwerken door middel van training?
Een diep neuraal netwerk leert door voorspellingen te doen en deze te vergelijken met de juiste uitkomsten. Bijvoorbeeld: bij het analyseren van foto's voorspelt het of er een hond op de afbeelding staat en houdt het bij hoe vaak het antwoord klopt.
Het netwerk berekent zijn nauwkeurigheid door het percentage correcte voorspellingen te controleren en gebruikt deze feedback om zichzelf te verbeteren. Het past de gewichten van de neuronen aan en voert het proces opnieuw uit. Als de nauwkeurigheid toeneemt, worden de nieuwe gewichten behouden; zo niet, dan probeert het andere aanpassingen.
Deze cyclus herhaalt zich vele keren totdat het netwerk consequent patronen kan herkennen en nauwkeurige voorspellingen kan doen. Zodra dit punt is bereikt, zeggen we dat het netwerk geconvergeerd is en succesvol getraind is.
Bespaar programmeertijd met betere resultaten
Het neurale netwerk dankt zijn naam aan de gelijkenis tussen deze programmeermethode en de werking van het menselijk brein.
Net als het brein gebruiken neurale netwerk-algoritmes een netwerk van neuronen of knooppunten. En zoals in het brein zijn deze neuronen afzonderlijke functies (of kleine machines, als je wilt) die input ontvangen en output genereren. Deze knooppunten zijn gerangschikt in lagen, waarbij de uitkomsten van neuronen in de ene laag de input vormen voor de volgende laag, totdat de neuronen in de buitenste laag van het netwerk het eindresultaat opleveren.
Er zijn dus lagen van neuronen, waarbij elke individuele neuron slechts beperkte input ontvangt en beperkte output genereert, net als in het brein. De eerste laag (de inputlaag) van neuronen ontvangt de input en de laatste laag (de outputlaag) van het netwerk geeft het resultaat.
Is het juist om dit type algoritme een 'neuraal netwerk' te noemen?
Het gebruik van de term 'diep neuraal netwerk' is effectieve branding gebleken, al kan het te hoge verwachtingen scheppen. Hoewel krachtig, zijn deze modellen nog steeds veel eenvoudiger dan de complexiteit van het menselijk brein. Toch blijven onderzoekers neurale architecturen verkennen met als doel algemene, mensachtige intelligentie te bereiken.
Dat gezegd hebbende, zijn er mensen die proberen het brein na te bouwen met een zeer complex neuraal netwerk, in de hoop zo algemene, mensachtige intelligentie te kunnen repliceren in botontwikkeling. Maar hoe helpt een neuraal netwerk en machine learning ons nu bij het herkennen van honden?
In plaats van handmatig hondachtige kenmerken te definiëren, kan een diep neuraal netwerk de belangrijke kenmerken identificeren en alle uitzonderingen afhandelen zonder extra programmering.
Veelgestelde vragen
1. Hoe lang duurt het om een diep neuraal netwerk te trainen?
Hoe lang het trainen van een diep neuraal netwerk duurt, hangt af van de grootte van de dataset en de complexiteit van het model. Een eenvoudig model kan binnen enkele minuten op een laptop getraind worden, terwijl een grootschalig model zoals GPT of ResNet dagen of zelfs weken kan duren met krachtige GPU's of TPU's.
2. Kan ik een DNN trainen op mijn eigen computer?
Ja, je kunt een diep neuraal netwerk trainen op je eigen computer als de dataset klein is en het model relatief eenvoudig. Voor grote modellen of datasets heb je echter een computer met GPU of toegang tot cloudplatforms zoals AWS of Azure nodig.
3. Wat is het verschil tussen een DNN voor computer vision en een voor natuurlijke taalverwerking?
Een diep neuraal netwerk voor computer vision gebruikt convolutionele lagen (CNN's) om pixeldata te verwerken, terwijl NLP-modellen architecturen zoals transformers, LSTM's of RNN's gebruiken om sequentiële en semantische structuren in taal te verwerken. Beide maken gebruik van deep learning, maar zijn geoptimaliseerd voor verschillende soorten data.
4. Hoe kies je het aantal verborgen lagen in een DNN?
Het kiezen van het aantal verborgen lagen in een DNN vereist experimenteren – te weinig lagen kunnen leiden tot underfitting, te veel tot overfitting en langzamere training. Begin met 1–3 lagen voor eenvoudige taken en verhoog dit stapsgewijs, waarbij je de prestaties controleert met cross-validatie of een testset.
5. Wat zijn de volgende grote doorbraken die worden verwacht in onderzoek naar diepe neurale netwerken?
Toekomstige doorbraken in onderzoek naar diepe neurale netwerken zijn onder andere: spaarzame neurale netwerken (die rekenkosten verlagen), neurosymbolisch redeneren (dat logica combineert met deep learning), betere interpretatietechnieken en energiezuinigere architecturen die de efficiëntie van het menselijk brein benaderen (zoals spiking neural networks).



