



- 深度神經網路(DNN)是一種由多層連接節點組成的機器學習系統,能夠從資料中學習模式並進行預測。
- DNN 可以根據過去的錯誤調整其內部連結,透過反向傳播機制,隨著時間提升準確度。
- 運算能力的進步以及龐大資料集的取得,使 DNN 能夠實際應用於處理文字、影像、音訊等非結構化資料的任務。
- DNN 的運作就像「黑盒子」,我們常常無法明確知道它是如何做出決策的。
什麼是深度神經網路?
深度神經網路(DNN)是一種模仿人腦處理資訊方式的機器學習模型。與傳統依照預設規則運作的演算法不同,DNN 能從資料中學習模式,並根據過去經驗進行預測——就像我們一樣。
DNN 是深度學習的基礎,驅動了像 AI 智能代理、影像辨識、語音助理、AI 聊天機器人 等應用。
全球 AI 市場——包括由深度神經網路驅動的應用——將在 2027 年突破 5,000 億美元。
什麼是神經網路架構?
DNN 中的「深度」指的是擁有多個隱藏層,讓網路能夠辨識更複雜的模式。
神經網路由多層節點組成,每一層從其他層接收輸入並產生輸出,直到得到最終結果。
神經網路由多層節點(神經元)組成。每個節點接收輸入、處理後再傳遞到下一層。
- 輸入層:第一層,負責接收原始資料(如影像、文字)。
- 隱藏層:位於輸入與輸出之間,負責轉換資料並偵測模式。
- 輸出層:產生最終預測結果。
神經網路可以有任意數量的隱藏層:節點層數越多,網路的複雜度越高。傳統神經網路通常只有 2 至 3 個隱藏層,而深度學習網路則可多達 150 個隱藏層。
神經網路與深度神經網路有何不同?
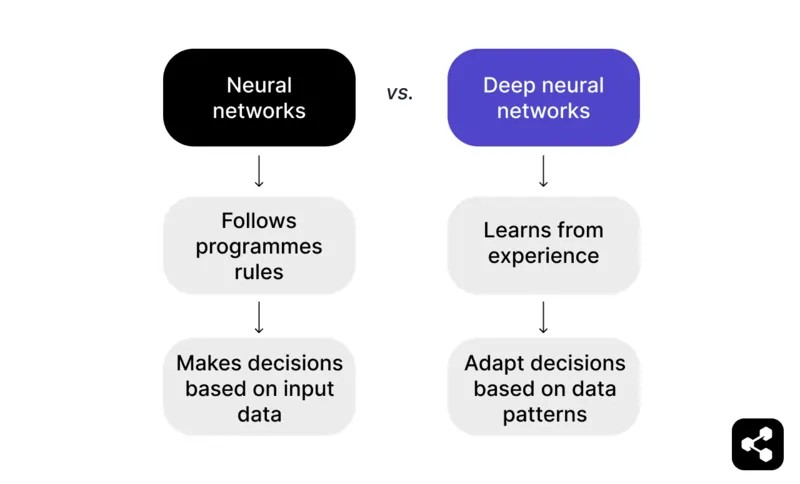
簡單來說:能夠超越輸入資料、從過去經驗中學習的神經網路,就是深度神經網路。
神經網路會依照程式規則,根據輸入資料做出決策。例如在西洋棋遊戲中,神經網路可以根據預設戰術與策略建議走法,但僅限於程式設計者提供的內容。
但深度神經網路則能進一步從經驗中學習。不再只依賴預設規則,DNN 能根據大量資料集裡的模式調整決策。
舉例
想像你要寫一個辨識照片中狗的程式。傳統神經網路需要明確規則來辨識毛皮或尾巴等特徵;而 DNN 則能從數千張標註過的圖片中學習,隨著時間提升準確度——即使遇到困難案例,也不需額外編程。
深度神經網路是如何運作的?
首先,輸入層的每個神經元會接收一部分原始資料,例如影像像素或句子中的單字,並為這些輸入賦予權重,表示其與任務的相關程度。
較低的權重(小於 0.5)代表該資訊較不重要。這些加權輸入會傳遞到隱藏層,神經元會進一步調整資訊。這個過程會在多層間持續,直到輸出層產生最終預測。
深度神經網路如何知道自己是否正確?
深度神經網路在訓練時,會將預測結果與標註資料進行比對。每筆輸入,網路都會檢查預測是否與實際結果相符。如果錯誤,網路會利用損失函數計算誤差,衡量預測偏離實際值的程度。
接著,網路會利用反向傳播來調整導致錯誤的神經元權重。這個過程會在每次訓練時重複進行。
神經網路有哪些類型?
深度神經網路如何隨時間進步?
深度神經網路會從錯誤中學習,隨著時間不斷進步。每當它做出預測——例如判斷客戶問題或推薦產品——都會檢查結果是否正確。如果錯誤,系統會自我調整,下次表現會更好。
舉例來說,在客服領域,DNN 可能會預測如何解決工單。如果預測錯誤,它會從錯誤中學習,未來處理類似工單時表現會更好。在銷售方面,DNN 能分析過去成交紀錄,學習哪些潛在客戶最容易成交,隨時間提升推薦品質。
因此,每一次互動都讓 DNN 更加準確可靠。
深度神經網路的思考方式和人類不同嗎?
但深度學習模型通常像「黑盒子」,人類難以理解它們如何做出決策。正如杜克大學 AI 研究員 Cynthia Rudin 所說,可解釋性對於 AI 系統在高風險環境中的倫理部署至關重要。
研究人員曾嘗試將網路處理影像的過程視覺化,但對於更複雜的任務——如語言或金融預測——其邏輯仍然難以理解。雖然這些演算法看似新穎,其實許多早在數十年前就已發展。真正讓它們實用的是資料量與運算能力的進步。
為什麼深度神經網路越來越受歡迎?
1. 運算能力提升
DNN 崛起的主要原因之一,是運算能力變得更快、更便宜。強大的運算力讓模型能快速收斂。「專用硬體如圖形處理器(GPU)和張量處理器(TPU)的出現,使訓練擁有數十億參數的網路成為可能。」
2. 資料集日益豐富
另一個關鍵因素是龐大資料集的取得,這對深度神經網路有效學習至關重要。隨著企業產生更多資料,DNN 能發掘傳統模型無法處理的複雜模式。
3. 處理非結構化資料的能力提升
DNN 能處理文字、影像、音訊等非結構化資料,也開啟了聊天機器人、推薦系統、預測分析等新應用。
神經網路能處理非結構化資料嗎?
可以,神經網路能處理非結構化資料,這也是它們最大的優勢之一。
能處理非結構化資料的人工神經網路稱為非監督式學習。這是機器學習的終極目標,也更接近人類的學習方式。
傳統的機器學習演算法在處理非結構化資料時表現不佳,因為它們需要進行特徵工程——也就是手動選擇和提取相關特徵。相比之下,神經網路能夠自動從原始資料中學習模式,無需大量人工干預。
深度神經網路是如何透過訓練來學習的?
深度神經網路透過預測並將結果與正確答案比較來學習。例如,當處理照片時,它會預測圖片中是否有狗,並記錄答對的次數。
網路會計算正確預測的比例來評估準確率,並利用這些回饋來改進自身。它會調整神經元的權重,然後再次執行這個過程。如果準確率提升,就保留新的權重;若沒有改善,則嘗試其他調整方式。
這個循環會重複進行多次,直到網路能夠穩定辨識模式並做出準確預測。當達到這個階段時,表示網路已經收斂並成功完成訓練。
節省程式撰寫時間,獲得更佳成果
神經網路之所以得名,是因為這種程式設計方式與大腦的運作方式有相似之處。
就像大腦一樣,神經網路演算法使用由神經元或節點組成的網路。而且,這些神經元就像大腦中的小型機器,負責接收輸入並產生輸出。這些節點以層狀方式排列,一層的神經元輸出會成為下一層神經元的輸入,直到最外層的神經元產生最終結果。
因此,神經網路中有多層神經元,每個神經元僅接收有限的輸入並產生有限的輸出,就像大腦一樣。第一層(輸入層)負責接收輸入,而最後一層(輸出層)則輸出結果。
稱這種演算法為「神經網路」是否準確?
將這種演算法稱為「深度神經網路」確實有助於推廣,但也可能讓人產生過高的期待。雖然這些模型很強大,但與人腦的複雜程度相比仍然簡單得多。不過,研究人員仍持續探索神經網路架構,希望能實現更通用、更接近人類智慧的系統。
話雖如此,確實有人嘗試用極為複雜的神經網路來重新打造大腦,期望藉此能夠在機器人開發中複製出通用且類似人類的智慧。那麼,神經網路和機器學習技術如何協助我們解決狗狗辨識的問題呢?
其實,與其手動定義狗的特徵,深度神經網路演算法可以自動找出重要特徵,並處理各種特殊情況,無需額外編程。
常見問題
1. 訓練一個深度神經網路需要多長時間?
訓練深度神經網路所需時間取決於資料集大小和模型複雜度。簡單的模型在筆記型電腦上幾分鐘就能訓練完成,而像 GPT 或 ResNet 這類大型模型則可能需要高效能 GPU 或 TPU 執行數天甚至數週。
2. 我可以在自己的電腦上訓練深度神經網路嗎?
可以,只要資料集不大且模型較簡單,就能在個人電腦上訓練深度神經網路。不過,如果要訓練大型模型或處理龐大資料集,則需要配備 GPU 的設備,或使用 AWS、Azure 等雲端平台。
3. 用於電腦視覺的深度神經網路和用於自然語言處理的有什麼不同?
用於電腦視覺的深度神經網路會採用卷積層(CNN)來處理像素資料,而自然語言處理模型則會用 Transformer、LSTM 或 RNN 等架構來處理語言的序列與語意結構。兩者都屬於深度學習,但針對不同資料型態進行最佳化。
4. 如何選擇深度神經網路的隱藏層數量?
選擇深度神經網路的隱藏層數量需要透過實驗調整——層數太少可能無法學到足夠特徵,層數太多則可能過度擬合並拖慢訓練速度。簡單任務可從 1–3 層開始,逐步增加,並用交叉驗證或測試集來評估表現。
5. 深度神經網路研究未來有哪些重大突破值得期待?
深度神經網路未來的重大突破包括稀疏神經網路(降低運算成本)、神經符號推理(結合邏輯與深度學習)、更好的可解釋性技術,以及模仿人腦高效率的節能架構(如脈衝神經網路)。



