



- Ein Deep Neural Network (DNN) ist ein System des maschinellen Lernens, das aus mehreren Schichten miteinander verbundener Knoten besteht, die Muster in Daten erkennen und daraus Vorhersagen treffen.
- DNNs können ihre internen Verbindungen anhand vergangener Fehler anpassen und so ihre Genauigkeit durch Backpropagation im Laufe der Zeit verbessern.
- Fortschritte in der Rechenleistung und der Zugang zu riesigen Datensätzen haben DNNs für Aufgaben mit unstrukturierten Daten wie Text, Bildern und Audio praktisch einsetzbar gemacht.
- DNNs funktionieren als „Black Box“, bei der oft unklar ist, wie Entscheidungen zustande kommen.
Was ist ein Deep Neural Network?
Ein Deep Neural Network (DNN) ist ein Modell des maschinellen Lernens, das nachahmt, wie das menschliche Gehirn Informationen verarbeitet. Im Gegensatz zu klassischen Algorithmen, die festen Regeln folgen, können DNNs Muster in Daten erkennen und auf Basis früherer Erfahrungen Vorhersagen treffen – genau wie wir.
DNNs bilden die Grundlage des Deep Learnings und treiben Anwendungen wie KI-Agenten, Bilderkennung, Sprachassistenten und KI-Chatbots an.
Der weltweite KI-Markt – einschließlich Anwendungen, die auf Deep Neural Networks basieren – wird bis 2027 die Marke von über 500 Milliarden US-Dollar überschreiten.
Was ist eine Deep Neural Network-Architektur?
Das „Deep“ in DNN steht für mehrere versteckte Schichten, die es dem Netzwerk ermöglichen, komplexe Muster zu erkennen.
Ein neuronales Netzwerk besteht aus mehreren Schichten von Knoten, die Eingaben von anderen Schichten erhalten und eine Ausgabe erzeugen, bis ein Endergebnis erreicht ist.
Ein neuronales Netzwerk besteht aus Schichten von Knoten (Neuronen). Jeder Knoten nimmt eine Eingabe auf, verarbeitet sie und gibt sie an die nächste Schicht weiter.
- Eingabeschicht: Die erste Schicht, die Rohdaten aufnimmt (z. B. Bilder, Text).
- Versteckte Schichten: Schichten zwischen Eingabe und Ausgabe, die Daten transformieren und Muster erkennen.
- Ausgabeschicht: Liefert die endgültige Vorhersage.
Neuronale Netzwerke können beliebig viele versteckte Schichten haben: Je mehr Schichten ein Netzwerk hat, desto komplexer ist es. Klassische neuronale Netzwerke bestehen meist aus 2 oder 3 versteckten Schichten, während Deep Learning-Netzwerke bis zu 150 versteckte Schichten haben können.
Worin unterscheiden sich neuronale Netzwerke und Deep Neural Networks?
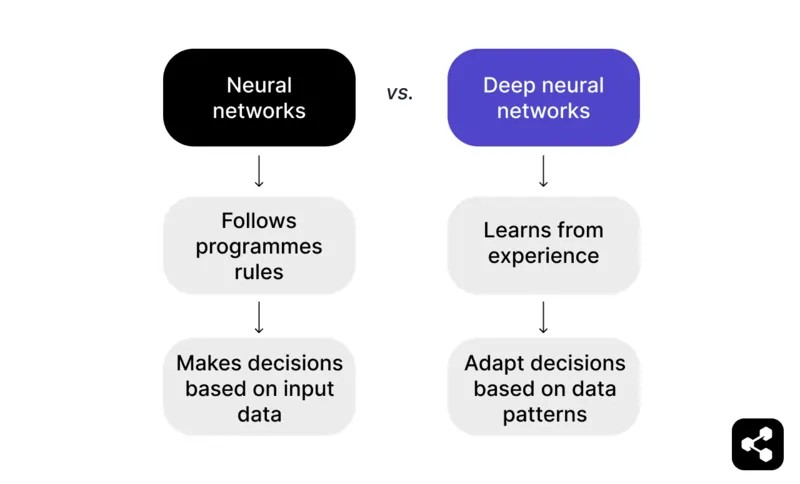
Kurz gesagt: Ein neuronales Netzwerk, das über die Eingabedaten hinausgeht und aus Erfahrungen lernen kann, wird zu einem Deep Neural Network.
Ein neuronales Netzwerk folgt programmierten Regeln, um Entscheidungen auf Basis von Eingabedaten zu treffen. Zum Beispiel kann ein neuronales Netzwerk beim Schachspiel Züge auf Basis vorgegebener Taktiken und Strategien vorschlagen, ist aber auf das beschränkt, was der Programmierer vorgegeben hat.
Ein Deep Neural Network geht jedoch weiter, indem es aus Erfahrungen lernt. Statt sich nur auf feste Regeln zu verlassen, kann ein DNN seine Entscheidungen anhand von Mustern in großen Datensätzen anpassen.
Beispiel
Stellen Sie sich vor, Sie schreiben ein Programm, das Hunde auf Fotos erkennt. Ein klassisches neuronales Netzwerk würde explizite Regeln benötigen, um Merkmale wie Fell oder Schwanz zu identifizieren. Ein DNN hingegen lernt aus Tausenden von gelabelten Bildern und verbessert seine Genauigkeit im Laufe der Zeit – auch bei schwierigen Fällen, ohne zusätzliche Programmierung.
Wie funktioniert ein Deep Neural Network?
Zunächst erhält jedes Neuron in der Eingabeschicht einen Teil der Rohdaten, etwa Pixel eines Bildes oder Wörter eines Satzes, und weist diesem Eingang ein Gewicht zu, das angibt, wie relevant die Information für die Aufgabe ist.
Ein niedriges Gewicht (unter 0,5) bedeutet, dass die Information wahrscheinlich weniger relevant ist. Diese gewichteten Eingaben werden durch die versteckten Schichten weitergegeben, wo die Neuronen die Informationen weiter anpassen. Das setzt sich über mehrere Schichten fort, bis die Ausgabeschicht eine endgültige Vorhersage liefert.
Wie weiß ein Deep Neural Network, ob es richtig liegt?
Ein Deep Neural Network erkennt, ob es richtig liegt, indem es seine Vorhersagen während des Trainings mit gelabelten Daten vergleicht. Für jede Eingabe prüft das Netzwerk, ob die Vorhersage mit dem tatsächlichen Ergebnis übereinstimmt. Liegt es falsch, berechnet das Netzwerk den Fehler mithilfe einer Verlustfunktion, die misst, wie weit die Vorhersage danebenlag.
Anschließend nutzt das Netzwerk Backpropagation, um die Gewichte der Neuronen anzupassen, die zum Fehler beigetragen haben. Dieser Vorgang wiederholt sich bei jeder Iteration.
Welche verschiedenen Arten von neuronalen Netzwerken gibt es?
Wie verbessert sich ein Deep Neural Network im Laufe der Zeit?
Ein Deep Neural Network verbessert sich im Laufe der Zeit, indem es aus Fehlern lernt. Wenn es eine Vorhersage trifft – etwa ein Kundenproblem erkennt oder ein Produkt empfiehlt – prüft es, ob die Vorhersage korrekt war. War sie falsch, passt sich das System an, um beim nächsten Mal besser zu werden.
Zum Beispiel kann ein DNN im Kundensupport vorhersagen, wie ein Ticket gelöst werden kann. War die Vorhersage falsch, lernt es daraus und wird bei ähnlichen Tickets in Zukunft genauer. Im Vertrieb kann ein DNN analysieren, welche Leads am ehesten konvertieren, und so seine Empfehlungen stetig verbessern.
Mit jeder Interaktion wird das DNN genauer und zuverlässiger.
Denken Deep Neural Networks anders als Menschen?
Deep-Learning-Modelle funktionieren jedoch oft als „Black Box“, das heißt, Menschen können ihre Entscheidungswege nicht leicht nachvollziehen. Wie die KI-Forscherin Cynthia Rudin von der Duke University erklärt, ist Interpretierbarkeit entscheidend für den ethischen Einsatz von KI-Systemen, besonders in sensiblen Bereichen.
Forscher haben versucht zu visualisieren, wie Netzwerke Bilder verarbeiten, aber bei komplexeren Aufgaben – wie Sprache oder Finanzprognosen – bleibt die Logik verborgen. Obwohl diese Algorithmen neu erscheinen, wurden viele bereits vor Jahrzehnten entwickelt. Erst Fortschritte bei Daten und Rechenleistung machen sie heute praktisch nutzbar.
Warum werden Deep Neural Networks immer beliebter?
1. Verbesserte Rechenleistung
Einer der Hauptgründe für den Anstieg von DNNs ist die schnellere und günstigere Rechenleistung. Die Rechenpower hat entscheidend dazu beigetragen, schnelle Ergebnisse zu erzielen. „Der Aufstieg spezialisierter Hardware wie Grafikprozessoren (GPUs) und Tensor Processing Units (TPUs) hat es möglich gemacht, Netzwerke mit Milliarden von Parametern zu trainieren.“
2. Zunehmende Verfügbarkeit von Datensätzen
Ein weiterer wichtiger Faktor ist die Verfügbarkeit großer Datensätze, die Deep Neural Networks zum effektiven Lernen benötigen. Da Unternehmen immer mehr Daten generieren, können DNNs komplexe Muster erkennen, die klassische Modelle nicht erfassen können.
3. Verbesserte Verarbeitung unstrukturierter Daten
Ihre Fähigkeit, unstrukturierte Daten wie Text, Bilder und Audio zu verarbeiten, hat zudem neue Anwendungen in Bereichen wie Chatbots, Empfehlungssystemen und Predictive Analytics ermöglicht.
Können neuronale Netzwerke mit unstrukturierten Daten arbeiten?
Ja, neuronale Netzwerke können mit unstrukturierten Daten arbeiten – das ist sogar eine ihrer größten Stärken.
Künstliche neuronale Netzwerke, die mit unstrukturierten Daten arbeiten, nennt man Unsupervised Learning. Das gilt als Königsdisziplin des maschinellen Lernens und ähnelt am ehesten der menschlichen Lernweise.
Traditionelle Machine-Learning-Algorithmen tun sich schwer mit unstrukturierten Daten, da sie Feature Engineering benötigen – also das manuelle Auswählen und Extrahieren relevanter Merkmale. Im Gegensatz dazu können neuronale Netze Muster in Rohdaten automatisch erkennen, ohne dass umfangreiche manuelle Eingriffe nötig sind.
Wie lernen tiefe neuronale Netze durch Training?
Ein tiefes neuronales Netz lernt, indem es Vorhersagen trifft und diese mit den korrekten Ergebnissen vergleicht. Zum Beispiel sagt es bei Fotos voraus, ob ein Bild einen Hund zeigt, und verfolgt, wie oft die Antwort richtig ist.
Das Netzwerk berechnet seine Genauigkeit, indem es den Anteil der korrekten Vorhersagen prüft, und nutzt dieses Feedback zur Verbesserung. Es passt die Gewichte seiner Neuronen an und wiederholt den Vorgang. Verbessert sich die Genauigkeit, behält es die neuen Gewichte; andernfalls versucht es andere Anpassungen.
Dieser Zyklus wiederholt sich über viele Durchläufe, bis das Netzwerk zuverlässig Muster erkennt und genaue Vorhersagen trifft. Sobald dieser Punkt erreicht ist, gilt das Netzwerk als konvergiert und erfolgreich trainiert.
Spare Programmierzeit mit besseren Ergebnissen
Das neuronale Netz trägt seinen Namen, weil es eine Ähnlichkeit zwischen diesem Programmieransatz und der Funktionsweise des Gehirns gibt.
Wie das Gehirn nutzen auch neuronale Netz-Algorithmen ein Netzwerk aus Neuronen oder Knoten. Und wie im Gehirn sind diese Neuronen eigenständige Funktionen (oder kleine Maschinen, wenn man so will), die Eingaben aufnehmen und Ausgaben erzeugen. Diese Knoten sind in Schichten angeordnet, wobei die Ausgaben der Neuronen einer Schicht zu den Eingaben der Neuronen der nächsten Schicht werden, bis die Neuronen der äußeren Schicht das Endergebnis liefern.
Es gibt also mehrere Schichten von Neuronen, wobei jedes einzelne Neuron nur sehr begrenzte Eingaben erhält und ebenso begrenzte Ausgaben erzeugt – genau wie im Gehirn. Die erste Schicht (Eingabeschicht) nimmt die Eingaben auf, und die letzte Schicht (Ausgabeschicht) gibt das Ergebnis aus.
Ist es zutreffend, diesen Algorithmus als „neuronales Netz“ zu bezeichnen?
Die Bezeichnung 'tiefes neuronales Netz' hat sich als effektives Branding erwiesen, auch wenn sie vielleicht zu hohe Erwartungen weckt. Trotz ihrer Leistungsfähigkeit sind diese Modelle immer noch deutlich einfacher als das menschliche Gehirn. Dennoch erforschen Wissenschaftler weiterhin neuronale Architekturen, um allgemeine, menschenähnliche Intelligenz zu erreichen.
Es gibt tatsächlich Menschen, die versuchen, das Gehirn mit sehr komplexen neuronalen Netzen nachzubauen, in der Hoffnung, so eine allgemeine, menschenähnliche Intelligenz in der Bot-Entwicklung zu erreichen. Wie helfen neuronale Netze und Machine-Learning-Techniken also bei unserem Hund-Erkennungsproblem?
Anstatt hundetypische Merkmale manuell zu definieren, kann ein Algorithmus für tiefe neuronale Netze die wichtigen Eigenschaften selbstständig erkennen und alle Sonderfälle ohne Programmierung behandeln.
FAQs
1. Wie lange dauert das Training eines tiefen neuronalen Netzes?
Die Trainingsdauer eines tiefen neuronalen Netzes hängt von der Größe des Datensatzes und der Komplexität des Modells ab. Ein einfaches Modell kann in wenigen Minuten auf einem Laptop trainiert werden, während ein großes Modell wie GPT oder ResNet Tage oder sogar Wochen auf Hochleistungs-GPUs oder TPUs benötigt.
2. Kann ich ein DNN auf meinem eigenen Computer trainieren?
Ja, Sie können ein tiefes neuronales Netz auf einem eigenen Computer trainieren, wenn der Datensatz klein und das Modell relativ einfach ist. Für große Modelle oder umfangreiche Datensätze benötigen Sie jedoch eine GPU-unterstützte Umgebung oder Zugriff auf Cloud-Plattformen wie AWS oder Azure.
3. Was ist der Unterschied zwischen einem DNN für Computer Vision und einem für Natural Language Processing?
Ein tiefes neuronales Netz für Computer Vision verwendet Faltungsschichten (CNNs), um Pixeldaten zu verarbeiten, während NLP-Modelle Architekturen wie Transformer, LSTMs oder RNNs nutzen, um die sequentielle und semantische Struktur von Sprache zu erfassen. Beide nutzen Deep Learning, sind aber für unterschiedliche Datentypen optimiert.
4. Wie wählt man die Anzahl der versteckten Schichten in einem DNN aus?
Die Wahl der Anzahl versteckter Schichten in einem DNN erfordert Ausprobieren – zu wenige führen zu Unteranpassung, zu viele können überanpassen und das Training verlangsamen. Für einfache Aufgaben beginnt man mit 1–3 Schichten und erhöht schrittweise, wobei die Leistung mit Kreuzvalidierung oder einem Testdatensatz überprüft wird.
5. Welche großen Durchbrüche werden in der Forschung zu tiefen neuronalen Netzen als nächstes erwartet?
Zukünftige Durchbrüche in der Forschung zu tiefen neuronalen Netzen umfassen spärliche neuronale Netze (die den Rechenaufwand verringern), neurosymbolisches Schließen (Kombination von Logik und Deep Learning), verbesserte Interpretierbarkeit sowie energieeffizientere Architekturen, die die Effizienz des menschlichen Gehirns nachahmen (z. B. Spiking Neural Networks).



