



- Rangkaian neural mendalam (DNN) ialah sistem pembelajaran mesin yang terdiri daripada lapisan nod yang saling berhubung untuk mempelajari corak dalam data dan membuat ramalan.
- DNN boleh melaraskan sambungan dalaman mereka berdasarkan kesilapan lalu, meningkatkan ketepatan mereka dari semasa ke semasa melalui proses backpropagation.
- Kemajuan dalam kuasa pengkomputeran dan akses kepada set data yang besar telah menjadikan DNN praktikal untuk tugasan yang melibatkan data tidak berstruktur seperti teks, imej, dan audio.
- DNN berfungsi sebagai 'kotak hitam' di mana selalunya tidak jelas bagaimana ia membuat keputusan.
Apakah itu rangkaian neural mendalam?
Rangkaian neural mendalam (DNN) ialah sejenis model pembelajaran mesin yang meniru cara otak manusia memproses maklumat. Tidak seperti algoritma tradisional yang mengikut peraturan yang telah ditetapkan, DNN boleh mempelajari corak daripada data dan membuat ramalan berdasarkan pengalaman lalu — sama seperti kita.
DNN ialah asas kepada pembelajaran mendalam, menggerakkan aplikasi seperti agen AI, pengecaman imej, pembantu suara, chatbot AI.
Pasaran AI global—termasuk aplikasi yang dikuasakan oleh rangkaian neural mendalam—akan melebihi $500 bilion menjelang 2027.
Apakah itu seni bina rangkaian neural?
'Mendalam' dalam DNN merujuk kepada adanya berbilang lapisan tersembunyi, membolehkan rangkaian mengenal pasti corak yang kompleks.
Satu rangkaian neural terdiri daripada beberapa lapisan nod yang menerima input daripada lapisan lain dan menghasilkan output sehingga keputusan akhir dicapai.
Rangkaian neural terdiri daripada lapisan nod (neuron). Setiap nod menerima input, memprosesnya, dan menghantarnya ke lapisan seterusnya.
- Lapisan input: Lapisan pertama yang menerima data mentah (contohnya, imej, teks).
- Lapisan tersembunyi: Lapisan di antara input dan output yang mengubah data dan mengesan corak.
- Lapisan output: Menghasilkan ramalan akhir.
Rangkaian neural boleh mempunyai sebarang bilangan lapisan tersembunyi: lebih banyak lapisan nod dalam rangkaian, lebih tinggi kerumitannya. Rangkaian neural tradisional biasanya terdiri daripada 2 atau 3 lapisan tersembunyi, manakala rangkaian pembelajaran mendalam boleh mempunyai sehingga 150 lapisan tersembunyi.
Bagaimana rangkaian neural berbeza daripada rangkaian neural mendalam?
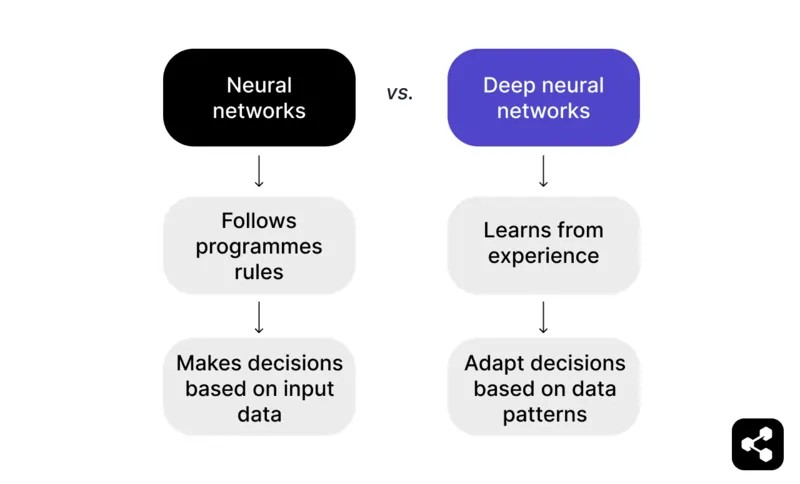
Ringkasnya: Rangkaian neural yang melangkaui data input dan boleh belajar daripada pengalaman lalu menjadi rangkaian neural mendalam.
Rangkaian neural mengikut peraturan yang diprogramkan untuk membuat keputusan berdasarkan data input. Sebagai contoh, dalam permainan catur, rangkaian neural boleh mencadangkan langkah berdasarkan taktik dan strategi yang telah ditetapkan, tetapi ia terhad kepada apa yang telah disediakan oleh pengaturcara.
Tetapi rangkaian neural mendalam pergi lebih jauh dengan belajar daripada pengalaman. Daripada hanya bergantung pada peraturan yang telah ditetapkan, DNN boleh melaraskan keputusannya berdasarkan corak yang dikenal pasti dalam set data yang besar.
Contoh
Bayangkan anda menulis program untuk mengenal pasti anjing dalam gambar. Rangkaian neural tradisional memerlukan peraturan khusus untuk mengenal pasti ciri seperti bulu atau ekor. Sebaliknya, DNN akan belajar daripada ribuan imej berlabel dan meningkatkan ketepatannya dari semasa ke semasa — malah mampu mengendalikan kes sukar tanpa pengaturcaraan tambahan.
Bagaimana rangkaian neural mendalam berfungsi?
Pertama, setiap neuron dalam lapisan input menerima sebahagian data mentah, seperti piksel daripada imej atau perkataan daripada ayat, dan memberikan pemberat kepada input ini, menunjukkan sejauh mana ia berkaitan dengan tugasan.
Pemberat yang rendah (kurang daripada 0.5) bermakna maklumat itu kurang berkaitan. Input yang telah diberi pemberat ini akan melalui lapisan tersembunyi, di mana neuron melaraskan maklumat tersebut lagi. Proses ini berterusan merentasi beberapa lapisan sehingga lapisan output memberikan ramalan akhir.
Bagaimana rangkaian neural mendalam tahu jika ia betul?
Rangkaian neural mendalam mengetahui sama ada ia betul dengan membandingkan ramalannya dengan data berlabel semasa latihan. Untuk setiap input, rangkaian menyemak sama ada ramalannya sepadan dengan hasil sebenar. Jika salah, rangkaian mengira ralat menggunakan fungsi kerugian, yang mengukur sejauh mana ramalan tersasar.
Rangkaian kemudian menggunakan backpropagation untuk melaraskan pemberat neuron yang menyumbang kepada ralat tersebut. Proses ini diulang untuk setiap iterasi.
Apakah jenis-jenis rangkaian neural yang berbeza?
Bagaimana rangkaian neural mendalam bertambah baik dari semasa ke semasa?
Rangkaian neural mendalam bertambah baik dari semasa ke semasa dengan belajar daripada kesilapan. Apabila ia membuat ramalan — seperti mengenal pasti isu pelanggan atau mencadangkan produk — ia akan menyemak sama ada keputusannya betul. Jika tidak, sistem akan melaraskan dirinya untuk menjadi lebih baik pada masa akan datang.
Sebagai contoh, dalam sokongan pelanggan, DNN mungkin meramalkan cara menyelesaikan tiket. Jika ramalan itu salah, ia belajar daripada kesilapan tersebut dan menjadi lebih baik dalam menyelesaikan tiket serupa pada masa hadapan. Dalam jualan, DNN boleh belajar prospek mana yang paling berpotensi dengan menganalisis urus niaga lalu, lalu meningkatkan cadangannya dari semasa ke semasa.
Jadi, dengan setiap interaksi, DNN menjadi semakin tepat dan boleh dipercayai.
Adakah rangkaian neural mendalam berfikir secara berbeza daripada manusia?
Namun, model pembelajaran mendalam sering berfungsi sebagai 'kotak hitam', bermakna manusia sukar untuk mentafsir bagaimana ia membuat keputusan. Seperti yang dijelaskan oleh penyelidik AI Cynthia Rudin dari Duke University menjelaskan, kebolehfahaman sangat penting untuk penggunaan AI secara beretika, terutamanya dalam persekitaran berisiko tinggi.
Penyelidik telah cuba menggambarkan bagaimana rangkaian memproses imej, tetapi untuk tugasan yang lebih kompleks—seperti bahasa atau ramalan kewangan—logiknya masih tersembunyi. Walaupun algoritma ini kelihatan baharu, banyak daripadanya telah dibangunkan beberapa dekad lalu. Kemajuan dalam data dan kuasa pengkomputeranlah yang menjadikannya praktikal hari ini.
Mengapa rangkaian neural mendalam semakin popular?
1. Peningkatan kuasa pemprosesan
Salah satu sebab utama peningkatan penggunaan DNN ialah kuasa pemprosesan kini lebih pantas dan murah. Kuasa pengkomputeran sangat penting untuk mencapai penumpuan yang pantas. "Kemunculan perkakasan khusus seperti Graphics Processing Units (GPU) dan Tensor Processing Units (TPU) telah membolehkan latihan rangkaian dengan berbilion parameter."
2. Ketersediaan set data yang semakin meningkat
Faktor utama lain ialah ketersediaan set data yang besar, yang diperlukan oleh rangkaian neural mendalam untuk belajar dengan berkesan. Apabila perniagaan menghasilkan lebih banyak data, DNN dapat mengenal pasti corak kompleks yang tidak dapat ditangani oleh model tradisional.
3. Penambahbaikan dalam pemprosesan data tidak berstruktur
Keupayaan mereka untuk memproses data tidak berstruktur seperti teks, imej, dan audio juga telah membuka aplikasi baharu dalam bidang seperti chatbot, sistem cadangan, dan analitik ramalan.
Bolehkah rangkaian neural berfungsi dengan data tidak berstruktur?
Ya, rangkaian neural boleh berfungsi dengan data tidak berstruktur, dan ini adalah salah satu kekuatan utamanya.
Rangkaian neural buatan yang menggunakan pembelajaran tanpa seliaan boleh memproses data tidak berstruktur. Ini adalah matlamat utama pembelajaran mesin dan lebih menyerupai cara manusia belajar.
Algoritma pembelajaran mesin tradisional sukar memproses data tidak berstruktur kerana ia memerlukan kejuruteraan ciri — iaitu pemilihan dan pengekstrakan ciri yang relevan secara manual. Sebaliknya, rangkaian neural boleh mengenal pasti corak dalam data mentah secara automatik tanpa campur tangan manual yang meluas.
Bagaimana rangkaian neural mendalam menggunakan latihan untuk belajar?
Rangkaian neural mendalam belajar dengan membuat ramalan dan membandingkannya dengan jawapan yang betul. Sebagai contoh, apabila memproses gambar, ia meramalkan sama ada imej mengandungi anjing dan menjejak kekerapan jawapannya betul.
Rangkaian ini mengira ketepatannya dengan memeriksa peratusan ramalan yang betul dan menggunakan maklum balas ini untuk penambahbaikan. Ia melaraskan pemberat neuron dan mengulangi proses tersebut. Jika ketepatan meningkat, ia mengekalkan pemberat baharu; jika tidak, ia mencuba pelarasan lain.
Kitaran ini diulang berkali-kali sehingga rangkaian dapat mengenal pasti corak dan membuat ramalan dengan tepat secara konsisten. Apabila tahap ini dicapai, rangkaian dianggap telah berjaya dilatih dan mencapai penumpuan.
Jimat masa pengekodan dengan hasil yang lebih baik
Rangkaian neural dinamakan sedemikian kerana pendekatan pengaturcaraan ini menyerupai cara otak berfungsi.
Sama seperti otak, algoritma rangkaian neural menggunakan rangkaian neuron atau nod. Dan seperti otak, neuron ini ialah fungsi diskret (atau mesin kecil, jika anda suka) yang menerima input dan menghasilkan output. Nod-nod ini disusun dalam lapisan di mana output neuron pada satu lapisan menjadi input kepada neuron di lapisan seterusnya sehingga neuron pada lapisan paling luar menghasilkan keputusan akhir.
Oleh itu, terdapat beberapa lapisan neuron, di mana setiap neuron individu menerima input yang sangat terhad dan menghasilkan output yang terhad, sama seperti dalam otak. Lapisan pertama (atau lapisan input) neuron menerima input dan lapisan terakhir neuron (atau lapisan output) dalam rangkaian menghasilkan keputusan.
Adakah tepat untuk memanggil algoritma jenis ini sebagai "rangkaian neural"?
Memanggil algoritma ini 'rangkaian neural mendalam' terbukti berkesan dari segi penjenamaan, walaupun ia mungkin menimbulkan jangkaan yang terlalu tinggi. Walaupun berkuasa, model-model ini masih jauh lebih ringkas berbanding kerumitan otak manusia. Namun begitu, penyelidik terus meneroka seni bina neural untuk mencapai kecerdasan umum seperti manusia.
Walau bagaimanapun, terdapat juga mereka yang cuba membina semula otak menggunakan rangkaian neural yang sangat kompleks, dengan harapan dapat meniru kecerdasan umum seperti manusia dalam pembangunan bot. Jadi, bagaimana rangkaian neural dan teknik pembelajaran mesin membantu kita dalam masalah pengecaman anjing?
Sebaliknya, tanpa perlu mendefinisikan ciri-ciri seperti anjing secara manual, algoritma rangkaian neural mendalam boleh mengenal pasti ciri penting dan mengendalikan semua kes khas tanpa perlu diprogramkan.
Soalan Lazim
1. Berapa lama masa yang diperlukan untuk melatih rangkaian neural mendalam?
Masa yang diperlukan untuk melatih rangkaian neural mendalam bergantung pada saiz set data dan kerumitan model. Model ringkas mungkin boleh dilatih dalam beberapa minit menggunakan komputer riba, manakala model berskala besar seperti GPT atau ResNet boleh mengambil masa beberapa hari atau minggu dengan menggunakan GPU atau TPU berprestasi tinggi.
2. Bolehkah saya melatih DNN di komputer peribadi saya?
Ya, anda boleh melatih rangkaian neural mendalam di komputer peribadi jika set data kecil dan model tidak terlalu kompleks. Namun, untuk melatih model besar atau menggunakan set data yang besar, anda memerlukan komputer dengan GPU atau akses ke platform awan seperti AWS atau Azure.
3. Apakah perbezaan antara DNN yang digunakan dalam visi komputer dan yang digunakan dalam pemprosesan bahasa semula jadi?
Rangkaian neural mendalam yang digunakan dalam visi komputer menggunakan lapisan konvolusi (CNN) untuk memproses data piksel, manakala model NLP menggunakan seni bina seperti transformer, LSTM, atau RNN untuk mengendalikan struktur berurutan dan semantik dalam bahasa. Kedua-duanya menggunakan pembelajaran mendalam tetapi dioptimumkan untuk jenis data yang berbeza.
4. Bagaimana memilih bilangan lapisan tersembunyi dalam DNN?
Pemilihan bilangan lapisan tersembunyi dalam DNN memerlukan percubaan – terlalu sedikit boleh menyebabkan model kurang belajar, manakala terlalu banyak boleh menyebabkan terlebih belajar dan melambatkan latihan. Mulakan dengan 1–3 lapisan untuk tugas mudah dan tambah secara berperingkat, sambil mengesahkan prestasi menggunakan kaedah silang-sah atau set ujian.
5. Apakah penemuan besar seterusnya yang dijangka dalam penyelidikan rangkaian neural mendalam?
Penemuan masa depan dalam penyelidikan rangkaian neural mendalam termasuk rangkaian neural jarang (yang mengurangkan kos pengiraan), penaakulan neurosimbolik (yang menggabungkan logik dengan pembelajaran mendalam), teknik interpretabiliti yang lebih baik, dan seni bina yang lebih cekap tenaga yang meniru kecekapan otak manusia (contohnya, rangkaian neural berdetik).



