



- Uma rede neural profunda (DNN) é um sistema de aprendizado de máquina composto por camadas de nós conectados que aprendem padrões em dados para fazer previsões.
- As DNNs podem ajustar suas conexões internas com base em erros anteriores, melhorando sua precisão ao longo do tempo por meio da retropropagação.
- Avanços no poder de processamento e o acesso a grandes volumes de dados tornaram as DNNs viáveis para tarefas envolvendo dados não estruturados, como texto, imagens e áudio.
- As DNNs funcionam como “caixas-pretas”, onde muitas vezes não está claro como elas chegam às decisões.
O que é uma rede neural profunda?
Uma rede neural profunda (DNN) é um tipo de modelo de aprendizado de máquina que imita como o cérebro humano processa informações. Diferente de algoritmos tradicionais que seguem regras pré-definidas, as DNNs conseguem aprender padrões a partir dos dados e fazer previsões com base em experiências anteriores — assim como nós.
As DNNs são a base do deep learning, impulsionando aplicações como agentes de IA, reconhecimento de imagens, assistentes de voz, chatbots de IA.
O mercado global de IA — incluindo aplicações baseadas em redes neurais profundas — irá ultrapassar US$ 500 bilhões até 2027.
O que é arquitetura de rede neural?
O “profundo” em DNN se refere à presença de múltiplas camadas ocultas, permitindo que a rede reconheça padrões complexos.
Uma rede neural é composta por várias camadas de nós que recebem entradas de outras camadas e produzem uma saída até chegar ao resultado final.
Uma rede neural consiste em camadas de nós (neurônios). Cada nó recebe uma entrada, processa e repassa para a próxima camada.
- Camada de entrada: A primeira camada que recebe os dados brutos (por exemplo, imagens, texto).
- Camadas ocultas: Camadas entre a entrada e a saída que transformam os dados e detectam padrões.
- Camada de saída: Gera a previsão final.
Redes neurais podem ter qualquer número de camadas ocultas: quanto mais camadas de nós, maior a complexidade. Redes neurais tradicionais geralmente possuem 2 ou 3 camadas ocultas, enquanto redes de deep learning podem ter até 150 camadas ocultas.
Como as redes neurais diferem das redes neurais profundas?
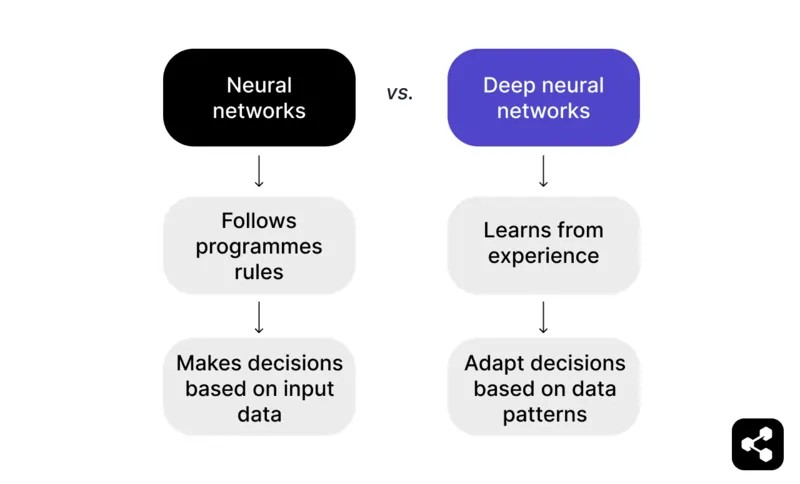
Resumindo: uma rede neural que vai além dos dados de entrada e consegue aprender com experiências anteriores se torna uma rede neural profunda.
Uma rede neural segue regras programadas para tomar decisões com base nos dados de entrada. Por exemplo, em um jogo de xadrez, uma rede neural pode sugerir jogadas com base em táticas e estratégias pré-definidas, mas fica limitada ao que o programador forneceu.
Já uma rede neural profunda vai além, aprendendo com a experiência. Em vez de depender apenas de regras pré-definidas, uma DNN pode ajustar suas decisões com base em padrões que reconhece em grandes conjuntos de dados.
Exemplo
Imagine criar um programa para reconhecer cachorros em fotos. Uma rede neural tradicional exigiria regras explícitas para identificar características como pelos ou caudas. Já uma DNN aprenderia com milhares de imagens rotuladas e melhoraria sua precisão ao longo do tempo — lidando até com casos difíceis sem programação extra.
Como funciona uma rede neural profunda?
Primeiro, cada neurônio na camada de entrada recebe uma parte dos dados brutos, como pixels de uma imagem ou palavras de uma frase, e atribui um peso a essa entrada, indicando o quanto ela é relevante para a tarefa.
Um peso baixo (menor que 0,5) significa que é menos provável que a informação seja relevante. Essas entradas ponderadas passam pelas camadas ocultas, onde os neurônios ajustam ainda mais as informações. Isso se repete por várias camadas até que a camada de saída forneça uma previsão final.
Como uma rede neural profunda sabe se está certa?
Uma rede neural profunda sabe se está certa ao comparar suas previsões com dados rotulados durante o treinamento. Para cada entrada, a rede verifica se sua previsão corresponde ao resultado real. Se estiver errada, a rede calcula o erro usando uma função de perda, que mede o quanto a previsão se afastou do esperado.
A rede então utiliza a retropropagação para ajustar os pesos dos neurônios que contribuíram para o erro. Esse processo se repete a cada iteração.
Quais são os diferentes tipos de redes neurais?
Como uma rede neural profunda melhora com o tempo?
Uma rede neural profunda melhora com o tempo aprendendo com seus erros. Quando faz uma previsão — como identificar um problema de cliente ou recomendar um produto — ela verifica se acertou. Se errou, o sistema se ajusta para melhorar na próxima vez.
Por exemplo, no suporte ao cliente, uma DNN pode prever como resolver um chamado. Se a previsão estiver errada, ela aprende com o erro e fica melhor em resolver chamados semelhantes no futuro. Em vendas, uma DNN pode aprender quais leads têm mais chance de conversão analisando negócios anteriores, melhorando suas recomendações ao longo do tempo.
Assim, a cada interação, a DNN se torna mais precisa e confiável.
Redes neurais profundas pensam diferente dos humanos?
Mas modelos de deep learning geralmente funcionam como uma 'caixa-preta', ou seja, os humanos não conseguem interpretar facilmente como as decisões são tomadas. Como explica a pesquisadora Cynthia Rudin, da Duke University, a interpretabilidade é fundamental para o uso ético de sistemas de IA, especialmente em ambientes críticos.
Pesquisadores tentaram visualizar como as redes processam imagens, mas para tarefas mais complexas — como linguagem ou previsões financeiras — a lógica permanece oculta. Embora esses algoritmos pareçam novos, muitos foram desenvolvidos há décadas. O que os tornou práticos hoje foram os avanços em dados e poder computacional.
Por que redes neurais profundas estão cada vez mais populares?
1. Avanços no poder de processamento
Um dos principais motivos para o crescimento das DNNs é que o poder de processamento está mais rápido e acessível. O poder computacional fez toda a diferença para alcançar convergência rápida. “O surgimento de hardwares especializados, como GPUs e TPUs, tornou viável treinar redes com bilhões de parâmetros.”
2. Maior disponibilidade de conjuntos de dados
Outro fator importante é a disponibilidade de grandes conjuntos de dados, que as redes neurais profundas precisam para aprender de forma eficaz. À medida que as empresas geram mais dados, as DNNs conseguem identificar padrões complexos que modelos tradicionais não conseguem.
3. Avanços no processamento de dados não estruturados
A capacidade de processar dados não estruturados, como texto, imagens e áudio, também abriu novas aplicações em áreas como chatbots, sistemas de recomendação e análises preditivas.
Redes neurais podem trabalhar com dados não estruturados?
Sim, redes neurais podem trabalhar com dados não estruturados, e essa é uma de suas maiores vantagens.
Redes neurais artificiais podem ser usadas em aprendizado não supervisionado quando trabalham com dados não estruturados. Esse é o grande objetivo do aprendizado de máquina e se assemelha mais à forma como os humanos aprendem.
Algoritmos tradicionais de aprendizado de máquina têm dificuldade para processar dados não estruturados porque exigem engenharia de atributos — a seleção e extração manual de características relevantes. Em contraste, redes neurais conseguem aprender padrões automaticamente a partir de dados brutos, sem grande intervenção manual.
Como redes neurais profundas aprendem durante o treinamento?
Uma rede neural profunda aprende fazendo previsões e comparando com os resultados corretos. Por exemplo, ao analisar fotos, ela prevê se uma imagem contém um cachorro e acompanha quantas vezes acerta.
A rede calcula sua precisão verificando a porcentagem de acertos e usa esse retorno para melhorar. Ela ajusta os pesos dos neurônios e repete o processo. Se a precisão aumenta, mantém os novos pesos; se não, tenta outros ajustes.
Esse ciclo se repete por várias iterações até que a rede consiga reconhecer padrões e fazer previsões precisas de forma consistente. Quando chega a esse ponto, dizemos que a rede convergiu e está treinada com sucesso.
Poupe tempo de programação com melhores resultados
A rede neural recebe esse nome porque há uma semelhança entre essa abordagem de programação e o funcionamento do cérebro.
Assim como o cérebro, os algoritmos de redes neurais usam uma rede de neurônios ou nós. E, como no cérebro, esses neurônios são funções discretas (ou pequenas máquinas, se preferir) que recebem entradas e geram saídas. Esses nós são organizados em camadas, de modo que as saídas dos neurônios de uma camada se tornam as entradas dos neurônios da próxima camada, até que os neurônios da camada externa da rede gerem o resultado final.
Portanto, existem camadas de neurônios, com cada neurônio individual recebendo entradas limitadas e gerando saídas limitadas, assim como no cérebro. A primeira camada (ou camada de entrada) recebe os dados e a última camada (ou camada de saída) gera o resultado.
É correto chamar esse tipo de algoritmo de “rede neural”?
Chamar esse algoritmo de 'rede neural profunda' funcionou bem como estratégia de divulgação, embora possa criar expectativas exageradas. Apesar de poderosos, esses modelos ainda são muito mais simples do que a complexidade do cérebro humano. Mesmo assim, pesquisadores continuam explorando arquiteturas neurais em busca de uma inteligência geral, semelhante à humana.
Dito isso, há pessoas tentando reengenheirar o cérebro, usando redes neurais extremamente complexas, na esperança de que, ao fazer isso, consigam replicar uma inteligência geral, parecida com a humana, no desenvolvimento de bots. Então, como redes neurais e técnicas de aprendizado de máquina nos ajudam no problema de reconhecimento de cachorros?
Bem, em vez de definir manualmente atributos que caracterizam um cachorro, um algoritmo de rede neural profunda pode identificar automaticamente os atributos importantes e lidar com casos especiais sem programação.
Perguntas frequentes
1. Quanto tempo leva para treinar uma rede neural profunda?
O tempo de treinamento de uma rede neural profunda depende do tamanho do conjunto de dados e da complexidade do modelo. Um modelo simples pode ser treinado em minutos em um notebook, enquanto modelos grandes como GPT ou ResNet podem levar dias ou até semanas usando GPUs ou TPUs de alto desempenho.
2. Posso treinar uma rede neural profunda no meu computador pessoal?
Sim, é possível treinar uma rede neural profunda em um computador pessoal se o conjunto de dados for pequeno e o modelo for relativamente simples. No entanto, para treinar modelos grandes ou usar grandes volumes de dados, será necessário um computador com GPU ou acesso a plataformas em nuvem como AWS ou Azure.
3. Qual a diferença entre uma rede neural profunda usada em visão computacional e uma usada em processamento de linguagem natural?
Uma rede neural profunda usada em visão computacional utiliza camadas convolucionais (CNNs) para processar dados de pixels, enquanto modelos de PLN usam arquiteturas como transformers, LSTMs ou RNNs para lidar com a estrutura sequencial e semântica da linguagem. Ambas usam aprendizado profundo, mas são otimizadas para tipos de dados diferentes.
4. Como escolher o número de camadas ocultas em uma rede neural profunda?
A escolha do número de camadas ocultas em uma rede neural profunda envolve experimentação — poucas camadas podem não ajustar bem aos dados, enquanto muitas podem causar sobreajuste e tornar o treinamento mais lento. Comece com 1 a 3 camadas para tarefas simples e aumente gradualmente, validando o desempenho com validação cruzada ou um conjunto de teste.
5. Quais são os próximos grandes avanços esperados em pesquisas de redes neurais profundas?
Os próximos avanços em pesquisas de redes neurais profundas incluem redes neurais esparsas (que reduzem o custo computacional), raciocínio neurossimbólico (que combina lógica com aprendizado profundo), técnicas de interpretabilidade aprimoradas e arquiteturas mais eficientes em energia que imitam a eficiência do cérebro humano (por exemplo, redes neurais pulsadas).



