



- ASR zamienia mowę na tekst za pomocą uczenia maszynowego, umożliwiając obsługę poleceń głosowych i transkrypcję w czasie rzeczywistym.
- Nowoczesne systemy ASR odeszły od oddzielnych modeli fonemów (HMM-GMM) na rzecz modeli głębokiego uczenia, które przewidują całe słowa.
- Wydajność ASR mierzy się wskaźnikiem błędu słowa (WER); błędy wynikają z podstawień, usunięć lub wstawek. Niższy WER = lepsza jakość transkrypcji.
- Przyszłość ASR skupia się na przetwarzaniu na urządzeniu dla ochrony prywatności oraz wsparciu języków o ograniczonych zasobach.
Kiedy ostatnio oglądałeś coś bez napisów?
Kiedyś były opcjonalne, a dziś pojawiają się nawet w krótkich filmach, czy tego chcemy, czy nie. Napisy są tak wtopione w treść, że łatwo o nich zapomnieć.
Automatyczne rozpoznawanie mowy (ASR) — czyli szybka i precyzyjna automatyzacja zamiany mowy na tekst — to technologia stojąca za tą zmianą.
Gdy myślimy o głosowym agencie AI, zwracamy uwagę na dobór słów, sposób wypowiedzi i barwę głosu.
Łatwo jednak zapomnieć, że płynność rozmowy zależy od tego, czy bot nas rozumie. A dojście do tego etapu — rozumienia przez bota nawet „yyy” i „eee” w hałaśliwym otoczeniu — nie było proste.
Dziś porozmawiamy o technologii, która stoi za tymi napisami: automatycznym rozpoznawaniu mowy (ASR).
Pozwól, że się przedstawię: mam tytuł magistra technologii mowy, a w wolnym czasie śledzę nowinki ze świata ASR i nawet buduję różne rzeczy.
Wyjaśnię Ci podstawy ASR, zajrzymy pod maskę tej technologii i spróbuję przewidzieć, dokąd zmierza.
Czym jest ASR?
Automatyczne rozpoznawanie mowy (ASR), znane też jako speech-to-text (STT), to proces zamiany mowy na tekst pisany z wykorzystaniem technologii uczenia maszynowego.
Technologie związane z mową często wykorzystują ASR na różne sposoby: do generowania napisów wideo, transkrypcji rozmów z obsługą klienta do analizy czy jako element asystenta głosowego, by wymienić tylko kilka.
Algorytmy zamiany mowy na tekst
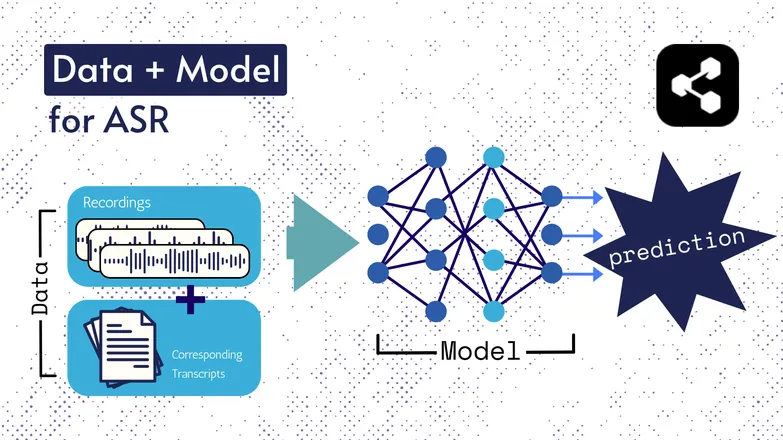
Podstawowe technologie zmieniały się przez lata, ale każda wersja składała się z dwóch elementów: danych i modelu.
W przypadku ASR danymi są oznaczone nagrania mowy – pliki audio z wypowiedziami i ich transkrypcjami.
Model to algorytm przewidujący transkrypcję na podstawie dźwięku. Dane z oznaczeniami służą do trenowania modelu, by potrafił uogólniać na nowe przykłady mowy.
To trochę jak zrozumienie ciągu słów, nawet jeśli nigdy nie słyszałeś ich w tej kolejności albo mówi je ktoś obcy.
Również rodzaje modeli i ich szczegóły zmieniały się z czasem, a wszystkie postępy w szybkości i dokładności wynikają z wielkości i jakości zbiorów danych oraz modeli.
Krótka dygresja: Ekstrakcja cech
Wspominałem o cechach, czyli reprezentacjach w moim artykule o syntezie mowy. Są one wykorzystywane w modelach ASR dawniej i dziś.
Ekstrakcja cech — czyli zamiana mowy na cechy — to pierwszy krok praktycznie w każdym procesie ASR.
W skrócie, te cechy, często spektragramy, powstają w wyniku obliczeń matematycznych na mowie i zamieniają ją na format, który podkreśla podobieństwa w wypowiedzi, a minimalizuje różnice między mówcami.
Czyli ta sama fraza wypowiedziana przez dwie różne osoby będzie miała podobne spektragramy, niezależnie od różnic w głosie.
Zwracam na to uwagę, bo będę mówił o modelach „przewidujących transkrypcje z mowy”. Technicznie rzecz biorąc, modele przewidują na podstawie cech. Ale możesz traktować ekstrakcję cech jako część modelu.
Początki ASR: HMM-GMM
Ukryte modele Markowa (HMMs) i modele mieszanin Gaussa (GMMs) to modele predykcyjne sprzed ery głębokich sieci neuronowych.
HMM-y dominowały w ASR aż do niedawna.
Dla danego pliku audio HMM przewidywał długość fonemu, a GMM określał, jaki to fonem.
Brzmi to trochę na odwrót i w sumie tak jest, na przykład:
- HMM: „Pierwsze 0,2 sekundy to fonem.”
- GMM: „Ten fonem to G, jak w Gary.”
Aby zamienić klip audio na tekst, potrzebnych było jeszcze kilka elementów, mianowicie:
- Słownik wymowy: pełna lista słów ze słownika wraz z ich wymową.
- Model językowy: kombinacje słów ze słownika i prawdopodobieństwo ich współwystępowania.
Więc nawet jeśli GMM przewidzi /f/ zamiast /s/, model językowy wie, że bardziej prawdopodobne jest, że ktoś powiedział „a penny for your thoughts”, a nie foughts.
Mieliśmy te wszystkie elementy, bo, mówiąc wprost, żaden z nich nie był szczególnie dobry.
HMM mylił się w dopasowaniu, GMM mylił podobne dźwięki: /s/ i /f/, /p/ i /t/, a o samogłoskach nawet nie zaczynam...
A potem model językowy próbował poskładać te niejasne fonemy w coś przypominającego język.
ASR end-to-end z głębokim uczeniem
Wiele elementów procesu ASR zostało od tego czasu połączonych.
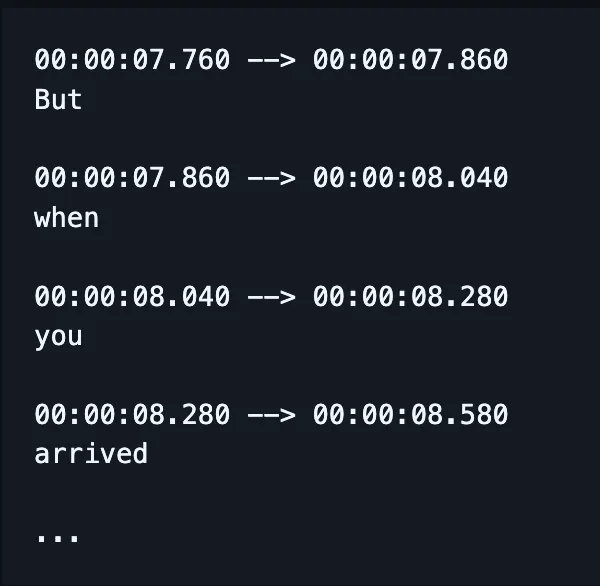
Zamiast trenować oddzielne modele do ortografii, wyrównania i wymowy, jeden model przyjmuje mowę i zwraca (miejmy nadzieję) poprawnie zapisane słowa, a dziś także znaczniki czasu.
(Chociaż w praktyce często poprawia się lub „przelicza” ten wynik dodatkowym modelem językowym.)
To nie znaczy, że różne aspekty — jak wyrównanie czy pisownia — nie są traktowane osobno. Nadal powstaje mnóstwo publikacji skupionych na rozwiązywaniu bardzo konkretnych problemów.
To znaczy, naukowcy wymyślają sposoby modyfikacji architektury modelu, by poprawić wybrane aspekty działania, na przykład:
- Dekoder RNN-Transducer, który bierze pod uwagę poprzednie wyniki, by poprawić pisownię.
- Konwolucyjne próbkowanie w dół, by ograniczyć puste wyniki i poprawić wyrównanie.
Wiem, że to brzmi jak bełkot. Uprzedzam pytanie szefa: „możesz podać przykład po ludzku?”
Odpowiedź brzmi: nie.
Nie mogę.
Jak mierzy się skuteczność ASR?
Gdy ASR działa źle, od razu to widać.
Widziałem, jak karmelizacja została przepisana jako komunistyczni Azjaci. Chrupkość na Krzysiek p — rozumiesz, o co chodzi.
Do matematycznego mierzenia błędów używamy wskaźnika błędu słowa (WER). Wzór na WER to:
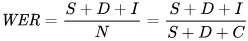
Gdzie:
- S to liczba podstawień (słów zmienionych w przewidywanym tekście, by pasowały do wzorcowego tekstu)
- D to liczba usunięć (słów brakujących w wyniku względem tekstu wzorcowego)
- I to liczba wstawiń (dodatkowych słów w wyniku względem tekstu wzorcowego)
- N to łączna liczba słów w tekście wzorcowym
Załóżmy, że tekst wzorcowy to „the cat sat.”
- Jeśli model zwróci „the cat sank”, to podstawienie.
- Jeśli model zwróci „cat sat”, to usunięcie.
- Jeśli model zwróci „the cat has sat”, to wstawienie.
Jakie są zastosowania ASR?
ASR to sprytne narzędzie.
Pomogło nam też poprawić jakość życia dzięki większemu bezpieczeństwu, dostępności i wydajności w kluczowych branżach.
Opieka zdrowotna
Kiedy mówię lekarzom, że zajmuję się rozpoznawaniem mowy, odpowiadają: „a, jak Dragon.”
Zanim pojawiła się generatywna AI w opiece zdrowotnej, lekarze sporządzali notatki ustne z prędkością 30 słów na minutę, korzystając z ograniczonego słownictwa.
ASR okazał się niezwykle skuteczny w ograniczaniu powszechnego wypalenia zawodowego wśród lekarzy.
Lekarze muszą godzić ogromną ilość dokumentacji z opieką nad pacjentami. Już w 2018 roku naukowcy apelowali o wykorzystanie cyfrowej transkrypcji podczas konsultacji, by poprawić jakość opieki.
Dzieje się tak, ponieważ dokumentowanie konsultacji po fakcie nie tylko ogranicza czas spędzany z pacjentem, ale jest też znacznie mniej dokładne niż podsumowania powstałe na podstawie transkrypcji rzeczywistych rozmów.
Inteligentne domy
Mam taki żart, który czasem robię.
Kiedy chcę zgasić światło, ale nie chce mi się wstawać, klaszczę dwa razy szybko — jakbym miał klaskacz.
Mój partner nigdy się nie śmieje.
Sterowane głosem inteligentne domy wydają się zarówno futurystyczne, jak i trochę przesadzone. Przynajmniej na pierwszy rzut oka.
Owszem, są wygodne, ale często umożliwiają rzeczy, które w innym przypadku byłyby niedostępne.
Świetnym przykładem jest zużycie energii: drobne zmiany oświetlenia czy temperatury byłyby trudne do wprowadzenia w ciągu dnia, gdyby za każdym razem trzeba było wstać i przekręcać pokrętło.
Sterowanie głosowe sprawia, że te drobne zmiany są nie tylko łatwiejsze, ale system rozumie też niuanse ludzkiej mowy.
Na przykład, mówisz: „czy możesz zrobić trochę chłodniej?” Asystent wykorzystuje przetwarzanie języka naturalnego, by przełożyć Twoją prośbę na zmianę temperatury, biorąc pod uwagę szereg innych danych: aktualną temperaturę, prognozę pogody, dane o korzystaniu z termostatu przez innych użytkowników itd.
Ty robisz to, co ludzkie, a komputer zajmuje się resztą.
Moim zdaniem to znacznie łatwiejsze niż zgadywanie, o ile stopni obniżyć temperaturę na podstawie własnego odczucia.
I jest bardziej energooszczędne: są doniesienia o rodzinach, które zmniejszyły zużycie energii nawet o 80% dzięki sterowanemu głosem oświetleniu – to tylko jeden z przykładów.
Obsługa klienta
Wspominaliśmy o tym w kontekście opieki zdrowotnej, ale transkrypcja i podsumowanie są znacznie skuteczniejsze niż późniejsze streszczanie przebiegu rozmów przez ludzi.
Znów – oszczędza to czas i jest dokładniejsze. Praktyka pokazuje, że automatyzacja pozwala ludziom lepiej wykonywać swoją pracę.
Nigdzie nie jest to bardziej widoczne niż w obsłudze klienta, gdzie wsparcie z wykorzystaniem ASR ma o 25% wyższy wskaźnik rozwiązania sprawy przy pierwszym kontakcie.
Transkrypcja i podsumowanie pomagają zautomatyzować proces znajdowania rozwiązania na podstawie nastroju i zapytania klienta.
Asystenci samochodowi
Trochę korzystamy tu z doświadczeń domowych asystentów, ale warto o tym wspomnieć.
Rozpoznawanie głosu zmniejsza obciążenie poznawcze i rozpraszanie uwagi kierowców.
A ponieważ rozproszenie uwagi odpowiada za nawet 30% kolizji, wdrożenie tej technologii to oczywisty wybór dla bezpieczeństwa.
Patologia mowy
ASR od dawna jest narzędziem w diagnozowaniu i leczeniu zaburzeń mowy.
Warto pamiętać, że maszyny nie tylko automatyzują zadania, ale potrafią też robić rzeczy, których człowiek nie jest w stanie.
Rozpoznawanie mowy może wychwycić subtelności niemal niesłyszalne dla ludzkiego ucha, rejestrując szczegóły zaburzonej mowy, które mogłyby umknąć uwadze.
Przyszłość ASR
STT jest już na tyle dobre, że przestaliśmy o nim myśleć.
Ale w tle naukowcy stale pracują nad tym, by było jeszcze potężniejsze, bardziej dostępne — i mniej zauważalne.
Wybrałem kilka ciekawych trendów wykorzystujących postępy w ASR i dodałem kilka własnych przemyśleń.
Rozpoznawanie mowy na urządzeniu
Większość rozwiązań ASR działa w chmurze. Pewnie już o tym słyszałeś. To znaczy, że model działa na zdalnym komputerze, gdzieś indziej.
Robią tak, bo procesor w Twoim telefonie nie zawsze poradzi sobie z ogromnym modelem lub transkrypcja trwałaby bardzo długo.
Zamiast tego Twój dźwięk jest przesyłany przez internet na zdalny serwer z GPU zbyt potężnym, by nosić je w kieszeni. GPU uruchamia model ASR i odsyła transkrypcję na Twoje urządzenie.
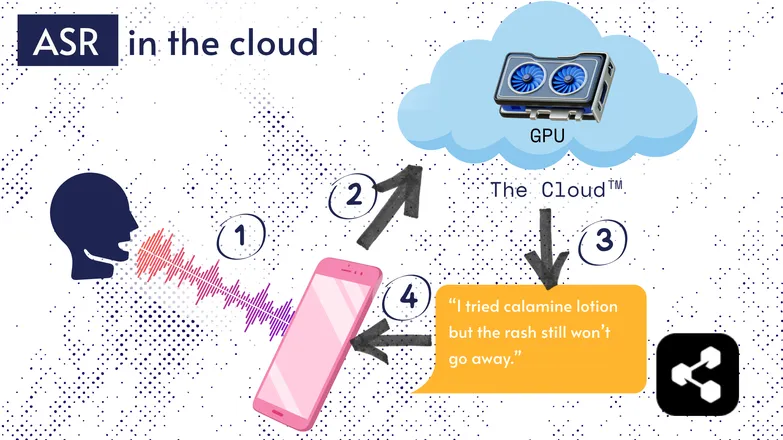
Ze względu na efektywność energetyczną i bezpieczeństwo (nie każdy chce, by jego dane krążyły po sieci), wiele badań zostało poświęconych temu, by modele były na tyle kompaktowe, by działały bezpośrednio na Twoim urządzeniu — telefonie, komputerze czy w silniku przeglądarki.
Napisałem pracę magisterską o kwantyzacji modeli ASR, aby mogły działać na urządzeniu. Picovoice to kanadyjska firma budująca niskolatencyjną sztuczną inteligencję głosową na urządzenia i wydają się interesujący.
ASR na urządzeniu umożliwia transkrypcję przy niższych kosztach, z potencjałem dotarcia do społeczności o niższych dochodach.
Interfejs Transcript-First
Różnica między dźwiękiem a transkrypcją się zaciera. Co to oznacza?
Edytory wideo, takie jak Premiere Pro czy Descript, pozwalają nawigować po nagraniach przez transkrypt: kliknij słowo, a przeniesie Cię do odpowiedniego momentu.
Musiałeś nagrać kilka wersji? Wybierz swoją ulubioną i usuń pozostałe, jak w edytorze tekstu. System automatycznie przytnie wideo za Ciebie.
Taka edycja na podstawie samej fali dźwiękowej jest frustrująca, ale z edytorem opartym na transkrypcji to banalnie proste.
Podobnie komunikatory, takie jak WhatsApp, transkrybują notatki głosowe i pozwalają przewijać je po tekście. Przesuń palcem po słowie, a trafisz do tego fragmentu nagrania.

Zabawna historia: zbudowałem coś podobnego około tydzień przed tym, jak Apple ogłosiło podobną funkcję.
Te przykłady pokazują, jak złożone technologie pod maską upraszczają i ułatwiają korzystanie z aplikacji końcowych.
Równość, inkluzja i języki niskozasobowe
Walka jeszcze się nie skończyła.
ASR świetnie działa po angielsku i w innych popularnych, dobrze wspieranych językach. Nie zawsze tak jest w przypadku języków niskozasobowych.
Istnieje luka dotycząca mniejszości dialektalnych, zaburzeń mowy i innych problemów z równością w technologiach głosowych.
Przepraszam, że psuję dobry nastrój. Ta sekcja nazywa się „przyszłość” ASR. Wolę patrzeć w przyszłość, z której będziemy dumni.
Jeśli mamy się rozwijać, powinniśmy robić to razem, inaczej ryzykujemy pogłębianie nierówności społecznych.
Zacznij korzystać z ASR już dziś
Niezależnie od branży, korzystanie z ASR to oczywisty wybór — ale pewnie zastanawiasz się, jak zacząć. Jak wdrożyć ASR? Jak przekazać te dane do innych narzędzi?
Botpress oferuje łatwe w użyciu karty transkrypcji. Można je zintegrować w przepływie typu „przeciągnij i upuść”, rozszerzyć o dziesiątki integracji z aplikacjami i kanałami komunikacji.
Zacznij budować już dziś. To nic nie kosztuje.
Najczęstsze pytania
Jak dokładny jest nowoczesny ASR w przypadku różnych akcentów i hałaśliwego otoczenia?
Nowoczesne systemy ASR są imponująco dokładne dla popularnych akcentów w głównych językach, osiągając wskaźnik błędów słownych (WER) poniżej 10% w sprzyjających warunkach, ale dokładność wyraźnie spada przy silnych akcentach, dialektach lub dużym hałasie w tle. Dostawcy tacy jak Google i Microsoft trenują modele na zróżnicowanych danych mowy, jednak idealna transkrypcja w hałaśliwym otoczeniu wciąż stanowi wyzwanie.
Czy ASR jest wiarygodny przy transkrypcji specjalistycznego żargonu lub terminologii branżowej?
ASR jest mniej wiarygodny w przypadku specjalistycznego żargonu lub terminologii branżowej, ponieważ jego dane treningowe są zwykle ukierunkowane na mowę ogólną; nieznane słowa mogą być błędnie transkrybowane lub pomijane. Jednak rozwiązania dla firm umożliwiają stosowanie własnych słowników, modeli językowych dla danej branży oraz słowników wymowy, co poprawia rozpoznawanie terminów technicznych w takich dziedzinach jak medycyna, prawo czy inżynieria.
Czym różnią się darmowe narzędzia ASR od rozwiązań klasy korporacyjnej?
Różnice między darmowymi narzędziami ASR a rozwiązaniami klasy korporacyjnej dotyczą dokładności, skalowalności, możliwości dostosowania i kontroli prywatności: darmowe narzędzia mają zwykle wyższy poziom błędów, ograniczoną obsługę języków i limity użycia, podczas gdy rozwiązania korporacyjne oferują niższy WER, dostosowanie do branży, integracje, umowy SLA i zaawansowane zabezpieczenia dla wrażliwych danych.
Jak ASR chroni prywatność użytkowników i wrażliwe informacje podczas transkrypcji?
ASR chroni prywatność użytkowników poprzez szyfrowanie podczas przesyłania danych oraz oferuje opcje uruchamiania modeli bezpośrednio na urządzeniu, aby uniknąć wysyłania danych głosowych na zewnętrzne serwery. Wielu dostawców korporacyjnych spełnia także wymogi regulacji dotyczących prywatności, takich jak RODO czy HIPAA, i może anonimizować dane w celu ochrony wrażliwych informacji.
Jakie są koszty usług ASR w chmurze w porównaniu do rozwiązań działających na urządzeniu?
Usługi ASR w chmurze zazwyczaj rozliczają się za minutę nagrania lub według progów użycia, a koszty wahają się od 0,03 do ponad 1,00 USD za minutę w zależności od dokładności i funkcji, podczas gdy rozwiązania działające na urządzeniu wymagają początkowych kosztów rozwoju i opłat licencyjnych.



