



- ASR 透過機器學習將語音轉換為文字,實現語音指令與即時轉錄。
- 現代 ASR 系統已從分離的音素模型(HMM-GMM)轉向能預測整個單字的深度學習模型。
- ASR 的效能以詞錯誤率(WER)衡量,錯誤來自替換、刪除或插入;WER 越低,轉錄品質越好。
- ASR 的未來重點在於裝置端處理以提升隱私,並支援資源較少的語言。
你上次看影片沒開字幕是什麼時候?
以前字幕是可選的,現在不管你要不要,短影音裡都會自動跳出來。字幕已經融入內容,讓你幾乎忘了它們的存在。
自動語音辨識(ASR)——能夠快速且準確地自動將語音轉成文字——正是推動這一轉變的技術。
當我們想到一個AI 語音代理人時,會想到它的用詞、表達方式,以及它說話的聲音。
但我們很容易忽略,互動的流暢其實仰賴機器人能否理解我們。而要達到這個程度——讓機器人在吵雜環境下也能聽懂你說話時的「嗯」和「啊」——其實並不容易。
今天,我們要聊聊推動這些字幕背後的技術:自動語音辨識(ASR)。
先自我介紹一下:我有語音技術碩士學位,平常也會關注 ASR 的最新發展,甚至會自己動手做些東西。
我會為你說明 ASR 的基本原理,帶你一窺技術細節,並大致預測這項技術未來的發展方向。
什麼是 ASR?
自動語音辨識(ASR),又稱語音轉文字(STT),是透過機器學習技術將語音轉換成書面文字的過程。
涉及語音的技術通常都會在某種程度上整合 ASR;舉例來說,影片字幕、客服對話轉錄分析,或語音助理互動等。
語音轉文字演算法
底層技術雖然歷經變化,但所有版本基本上都包含兩個要素:資料和模型。
以 ASR 為例,資料是有標註的語音——也就是語音檔案及其對應的文字轉錄。
模型則是用來從語音預測轉錄內容的演算法。這些有標註的資料用來訓練模型,使其能夠泛化到未見過的語音樣本。
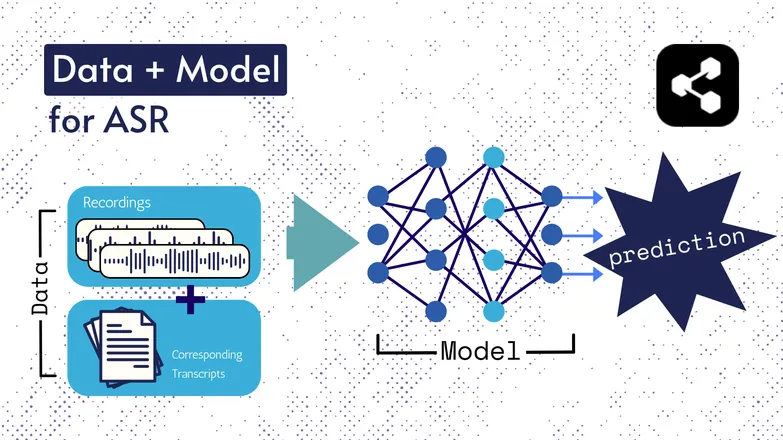
這很像你能理解一串單字,即使你從沒聽過這個順序,或是說話的人是陌生人。
同樣地,模型的種類與細節隨時間演進,所有速度與準確度的進步都歸功於資料集與模型的規模與規格提升。
補充說明:特徵擷取
我在上一篇關於文字轉語音的文章中提過特徵或表徵。這些在過去與現在的 ASR 模型中都會用到。
特徵擷取——也就是將語音轉換為特徵——幾乎是所有 ASR 流程的第一步。
簡單來說,這些特徵,通常是頻譜圖,是對語音進行數學運算後的結果,能將語音轉換成一種強調同一句話相似性、減少不同說話者差異的格式。
也就是說,兩個不同說話者講同一句話時,頻譜圖會很相似,不管他們的聲音有多不同。
我特別說明這點,是想讓你知道我接下來會說模型「從語音預測轉錄」。其實更精確地說,是從特徵預測。不過你可以把特徵擷取當作模型的一部分來看。
早期 ASR:HMM-GMM
隱馬可夫模型(HMM)和高斯混合模型(GMM)是深度神經網路普及前的預測模型。
HMM 一直到最近都主導著 ASR 領域。
給定一個語音檔案,HMM 會預測音素的持續時間,GMM 則預測音素本身。
這聽起來有點顛倒,實際上也確實如此,像這樣:
- HMM:「前 0.2 秒是一個音素。」
- GMM:「這個音素是G,像Gary的 G。」
要把一段語音轉成文字,還需要幾個額外的元件,包括:
- 發音字典:收錄所有詞彙及其對應發音的完整清單。
- 語言模型:詞彙間的組合及其同時出現的機率。
所以即使 GMM 預測 /f/ 而不是 /s/,語言模型也知道「a penny for your thoughts」比 foughts 合理得多。
會有這麼多組件,坦白說,是因為這整個流程沒有哪一部分特別強。
HMM 會對齊錯誤,GMM 會把相似的音聽錯:像 /s/ 和 /f/、/p/ 和 /t/,母音更不用說了。
然後語言模型會把這些亂七八糟的音素整理成比較像語言的東西。
深度學習的端到端 ASR
ASR 流程中的許多部分如今已經整合起來。
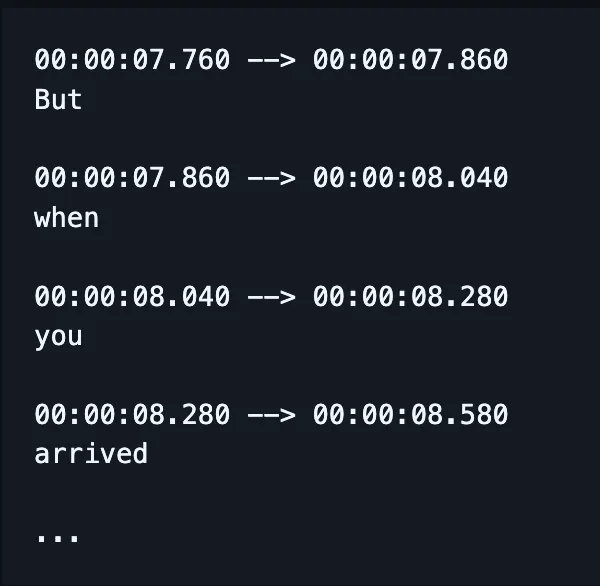
現在不再需要分開訓練拼字、對齊、發音等模型,一個模型就能輸入語音並輸出(希望是)拼字正確的單字,現在還能同時標記時間戳。
(不過實際應用中,通常還會用額外的語言模型來修正或「重新評分」這些輸出。)
這並不代表像對齊、拼字這些因素就沒有人關注。針對特定問題的改進,相關研究文獻仍然非常多。
也就是說,研究人員會針對模型效能的特定面向,設計調整模型架構的方法,例如:
- 用依賴前一輸出的 RNN-Transducer 解碼器來改善拼字。
- 用卷積式降採樣減少空白輸出,提升對齊效果。
我知道這聽起來很難懂。我只是先預防老闆問我「能不能舉個白話例子?」
答案是不行。
真的沒辦法。
ASR 的效能怎麼評量?
ASR 表現不佳時,你一聽就知道。
我看過caramelization被轉錄成communist Asians,Crispiness變成Chris p —,你懂我的意思。
我們用來數學化反映錯誤的指標是詞錯誤率(WER)。WER 的公式如下:
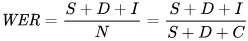
其中:
- S 是替換的數量(為了和參考文本一致而改變的單字數)
- D 是刪除的數量(輸出中比參考文本少的單字數)
- I 是插入的數量(輸出中比參考文本多的單字數)
- N 是參考文本中的總單字數
假設參考文本是「the cat sat.」
- 如果模型輸出「the cat sank」,這是替換。
- 如果模型輸出「cat sat」,這是刪除。
- 如果輸出「the cat has sat」,這是插入。
ASR 有哪些應用?
ASR 是個很實用的工具。
它也幫助我們在重要產業中提升安全性、無障礙性與效率,改善了生活品質。
醫療保健
每次我跟醫生說我做語音辨識研究,他們都會說「喔,像Dragon那種。」
在我們擁有醫療領域的生成式 AI之前,醫生只能以每分鐘 30 字的速度用有限的詞彙做口頭記錄。
ASR(自動語音辨識)在減輕醫生普遍的職業倦怠方面取得了巨大成功。
醫師必須在大量文書工作與照顧病患之間取得平衡。早在 2018 年,研究人員就已經呼籲在診療時使用數位轉錄,以提升醫生提供醫療照護的能力。
這是因為事後補記診療內容不僅會減少與病患面對面的時間,而且比起直接轉錄諮詢內容再摘要,準確度也大打折扣。
智慧家庭
我有個自己常講的笑話。
當我想關燈但又懶得起身時,我會快速拍兩下手——就像我有個聲控開關一樣。
我的另一半從來沒笑過。
聲控智慧家庭既讓人覺得很有未來感,也有點奢侈。至少看起來是這樣。
沒錯,它們很方便,但在許多情況下,它們讓原本做不到的事變得可能。
一個很好的例子是能源消耗:如果你必須一直起身調整燈光和溫控器,整天做這些小調整根本不切實際。
聲控讓這些微調不僅更容易,也能讀懂人類語言的細微差異。
舉例來說,你說「可以再涼一點嗎?」助理會利用自然語言處理,把你的請求轉換成溫度調整,並考量許多其他數據:目前溫度、天氣預報、其他用戶的溫控使用資料等等。
你負責人類該做的部分,電腦的事就交給電腦處理。
我認為這比你自己憑感覺猜要調幾度還要簡單多了。
而且它更節能:有報導指出,家庭使用語音啟動智慧照明後,能源消耗可減少高達80%,這只是其中一個例子。
客戶支援
我們在醫療領域已經談過這點,但「轉錄加摘要」比人們事後回顧互動內容再做摘要有效得多。
同樣地,這樣可以節省時間,也更精確。我們一再發現,自動化能讓人們有更多時間把本職工作做得更好。
這一點在客服領域尤其明顯,因為採用ASR技術的客服,首次解決率提升了25%。
轉錄與摘要有助於自動化根據客戶情緒和問題找出解決方案的流程。
車載語音助理
我們這裡是從家庭助理延伸過來的,但很值得一提。
語音辨識能減輕駕駛者的認知負擔與視覺干擾。
而分心導致的事故佔比高達30%,因此導入這項技術對於安全來說是顯而易見的選擇。
語言治療
ASR 長期以來一直被用作評估與治療語言障礙的工具。
我們要記得,機器不只是在自動化任務,還能做到人類做不到的事。
語音辨識能偵測到人耳幾乎察覺不到的語音細節,捕捉到受影響語音的特徵,否則這些細節很容易被忽略。
ASR 的未來
STT(語音轉文字)已經好到讓我們幾乎不再注意它的存在。
但在幕後,研究人員仍在努力讓它更強大、更容易取得——而且更不引人注意。
我挑選了一些利用 ASR 進步的有趣趨勢,也加進了自己的想法。
裝置端語音辨識
大多數 ASR 解決方案都在雲端運行。你應該聽過這說法。也就是說,模型是在遠端電腦上運行,而不是在你身邊。
這麼做是因為你手機的小處理器不一定跑得動龐大的模型,或是轉錄會花很久。
因此,你的音訊會透過網路傳送到遠端伺服器,由一台你不可能隨身攜帶的GPU來處理。GPU 執行 ASR 模型,然後把轉錄結果傳回你的裝置。
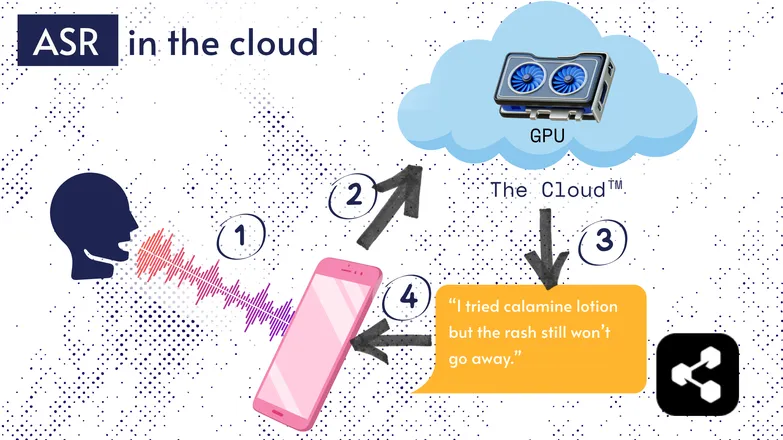
為了提升能源效率與安全性(不是每個人都希望個資在網路上流竄),有大量研究投入於讓模型精簡到可以直接在你的裝置上運行,不論是手機、電腦還是瀏覽器引擎。
我本人寫過一篇關於 ASR 量化的論文,讓模型能在裝置端運作。Picovoice是一家加拿大公司,專注於低延遲的裝置端語音 AI,看起來很有潛力。
裝置端 ASR 讓轉錄成本更低,有機會服務低收入社群。
以逐字稿為核心的介面
音訊與轉錄之間的距離正在縮小。這代表什麼?
像 Premiere Pro 和 Descript 這類影片編輯器,讓你可以透過轉錄內容瀏覽錄音:點一下某個字,就會跳到該時間點。
需要重錄幾次嗎?像編輯文字一樣選擇你最喜歡的版本,刪除其他的。系統會自動幫你修剪影片。
只靠音波圖來編輯這種內容很讓人抓狂,但有了以轉錄為基礎的編輯器就變得超簡單。
同樣地,像 WhatsApp 這類通訊服務也會把你的語音訊息轉成文字,讓你可以直接滑動文字來瀏覽內容。手指滑過某個字,就會跳到錄音的那個部分。

有趣的是:我其實在蘋果宣布類似功能前一週就做過這樣的東西。
這些例子顯示,複雜的底層技術能為終端用戶帶來簡單直覺的體驗。
公平、包容與低資源語言
這場戰役還沒結束。
ASR 在英語和其他常見、資源豐富的語言上表現很好。但對於低資源語言就不一定如此。
在方言少數族群、語音障礙等議題上,語音技術的公平性仍有落差。
很抱歉打斷好心情。這一節談的是 ASR 的「未來」。我選擇期待一個值得我們驕傲的未來。
如果我們要進步,就應該一起前進,否則只會加劇社會不平等。
立即開始使用 ASR
無論你的產業是什麼,使用ASR都是明智之舉——但你可能會想知道該怎麼開始。要如何導入ASR?又該如何將這些資料傳遞給其他工具?
Botpress 內建易用的轉錄卡片。你可以把它們整合進拖拉式流程,並搭配數十種應用程式和通訊管道的整合使用。
立即開始打造。免費使用。
常見問題
現代ASR在不同口音和嘈雜環境下的準確度如何?
現代ASR系統對於主流語言的常見口音表現相當精確,在安靜環境下字詞錯誤率(WER)低於10%,但遇到重口音、方言或明顯背景雜音時,準確度會明顯下降。像Google和Microsoft等廠商會用多元語音資料訓練模型,但在吵雜環境下要做到完美轉錄仍有挑戰。
ASR在轉錄專業術語或產業專用詞彙時可靠嗎?
ASR在處理專業術語或產業專用詞彙時,預設情況下準確度較低,因為訓練資料多偏向一般語言;不熟悉的詞彙可能會被誤轉或遺漏。不過,企業級方案可自訂詞彙表、領域專屬語言模型及發音字典,能提升醫療、法律、工程等領域的專業詞彙辨識率。
免費 ASR 工具和企業級解決方案有什麼差別?
免費 ASR 工具和企業級解決方案的差異在於準確率、可擴展性、客製化和隱私控管:免費工具通常錯誤率較高、語言支援有限且有使用上限,而企業級方案則提供更低的 WER、領域專屬客製化、整合能力、服務等級協議(SLA)以及處理敏感資料的強大安全功能。
ASR在轉錄過程中如何保護用戶隱私及敏感資訊?
ASR 透過在資料傳輸過程中加密來保護使用者隱私,並提供如在裝置端執行模型等選項,以避免語音資料傳送到外部伺服器。許多企業級服務供應商也遵循 GDPR 或 HIPAA 等隱私法規,並可將資料匿名化以保障敏感資訊。
雲端 ASR 服務與裝置端解決方案的費用差異大嗎?
雲端ASR服務通常依音訊分鐘數或使用量分級收費,根據準確度和功能,每分鐘費用約在0.03至1.00美元以上;而裝置端方案則需一次性開發成本及授權費用。



