



- ASR, konuşmayı makine öğrenimiyle metne dönüştürerek sesli komutları ve gerçek zamanlı transkripsiyonu mümkün kılar.
- Modern ASR sistemleri, ayrı fonem modellerinden (HMM-GMM) tüm kelimeleri tahmin eden derin öğrenme modellerine geçiş yaptı.
- ASR performansı, Kelime Hata Oranı (WER) ile ölçülür; hatalar yerine koyma, silme veya ekleme şeklinde olabilir; düşük WER = daha iyi transkripsiyon kalitesi demektir.
- ASR'nin geleceği, gizlilik için cihaz üzerinde işleme ve az kaynaklı dilleri desteklemeye odaklanıyor.
En son ne zaman altyazısız bir şey izlediniz?
Eskiden isteğe bağlıydı, ama artık kısa videolarda istemesek de karşımıza çıkıyorlar. Altyazılar içeriğe o kadar entegre oldu ki, varlıklarını unutuyorsunuz.
Otomatik konuşma tanıma (ASR) — konuşulan kelimeleri hızlı ve doğru şekilde otomatik olarak metne dönüştürme yeteneği — bu değişimi mümkün kılan teknoloji.
Bir yapay zeka sesli ajanı düşündüğümüzde, kelime seçimini, konuşma tarzını ve ses tonunu aklımıza getiriyoruz.
Ama etkileşimlerimizin akıcı olmasının, botun bizi anlamasına bağlı olduğunu kolayca unutuyoruz. Ve bu noktaya gelmek — botun gürültülü bir ortamda “ııı” ve “aaa” gibi seslerimizi anlaması — hiç de kolay olmadı.
Bugün, o altyazıları mümkün kılan teknolojiden, yani otomatik konuşma tanımadan (ASR) bahsedeceğiz.
Kendimi tanıtayım: Konuşma teknolojileri alanında yüksek lisansım var ve boş zamanlarımda ASR ile ilgili yenilikleri takip etmeyi ve hatta bir şeyler geliştirmeyi seviyorum.
ASR'nin temellerini size anlatacağım, teknolojinin detaylarına ineceğim ve gelecekte nereye evrilebileceğine dair tahminlerimi paylaşacağım.
ASR nedir?
Otomatik konuşma tanıma (ASR) veya konuşmadan metne (STT), konuşmayı makine öğrenimi teknolojisiyle yazılı metne dönüştürme sürecidir.
Konuşmayı içeren teknolojiler genellikle bir şekilde ASR içerir; örneğin video altyazılamada, müşteri destek görüşmelerinin analiz için transkribe edilmesinde veya bir sesli asistan etkileşiminde kullanılabilir.
Konuşmadan Metne Algoritmaları
Temel teknolojiler yıllar içinde değişti, ancak tüm versiyonlarda iki ana bileşen hep vardı: veri ve bir model.
ASR'de, veri etiketlenmiş konuşmadır – yani konuşma ses dosyaları ve bunların metin karşılıklarıdır.
Model ise, sesteki transkripsiyonu tahmin eden algoritmadır. Etiketli veriler modelin eğitilmesinde kullanılır, böylece model daha önce görmediği konuşma örneklerinde de genelleme yapabilir.
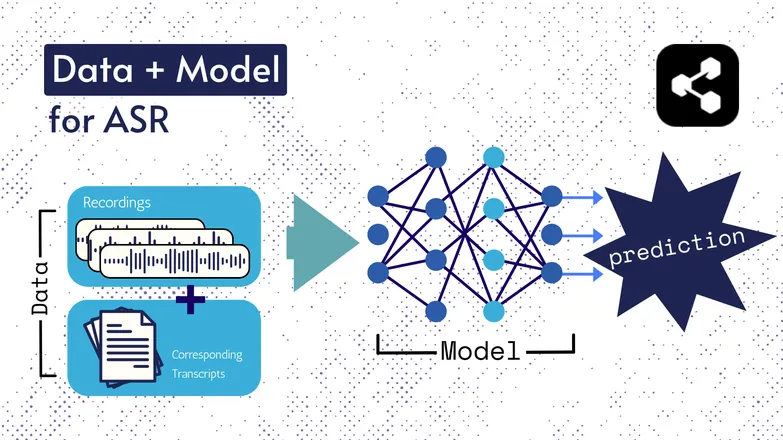
Bu, hiç duymadığınız bir kelime dizisini, ya da yabancı birinin söylediği kelimeleri anlayabilmenize benzer.
Yine, model türleri ve detayları zamanla değişti ve hız ile doğruluktaki tüm gelişmeler, veri setlerinin ve modellerin büyüklüğüne ve özelliklerine bağlı oldu.
Kısa Bir Not: Özellik Çıkartımı
Özellikler veya temsiller hakkında metinden konuşmaya makalemde bahsetmiştim. Bunlar geçmişte ve günümüzde ASR modellerinde kullanılıyor.
Özellik çıkartımı — konuşmayı özelliklere dönüştürmek — neredeyse tüm ASR süreçlerinin ilk adımıdır.
Kısaca, bu özellikler genellikle spektrumlar olur ve konuşma üzerinde yapılan matematiksel bir işlem sonucunda elde edilir; konuşmayı, bir ifadedeki benzerlikleri öne çıkaran ve konuşmacılar arasındaki farklılıkları azaltan bir formata dönüştürür.
Yani, aynı ifadeyi iki farklı kişi söylese de, sesleri ne kadar farklı olursa olsun, spektrumları benzer olur.
Bunu belirtmemin nedeni, modellerin “konuşmadan transkript tahmin ettiğinden” bahsedecek olmam. Aslında teknik olarak doğru değil; modeller özelliklerden tahmin yapıyor. Ama özellik çıkartımı bileşenini modelin bir parçası olarak düşünebilirsiniz.
Erken Dönem ASR: HMM-GMM
Gizli Markov Modelleri (HMM) ve Gauss Karışım Modelleri (GMM), derin sinir ağları yaygınlaşmadan önce kullanılan tahmin modelleriydi.
HMM'ler, yakın zamana kadar ASR alanında baskındı.
Bir ses dosyası verildiğinde, HMM bir fonemin süresini tahmin eder, GMM ise fonemin kendisini tahmin ederdi.
Bu kulağa biraz ters geliyor ve aslında öyle, yani:
- HMM: “İlk 0,2 saniye bir fonem.”
- GMM: “O fonem bir G, yani Gary’deki gibi.”
Bir ses kaydını metne dönüştürmek için birkaç ek bileşen daha gerekiyordu, özellikle:
- Bir telaffuz sözlüğü: kelime haznesindeki tüm kelimelerin ve telaffuzlarının eksiksiz listesi.
- Bir dil modeli: Kelime haznesindeki kelimelerin kombinasyonları ve birlikte görülme olasılıkları.
Yani GMM /f/ yerine /s/ tahmin etse bile, dil modeli konuşmacının büyük ihtimalle “a penny for your thoughts” dediğini, foughts demediğini bilir.
Tüm bu parçalara sahip olmamızın nedeni, açıkça söylemek gerekirse, bu sürecin hiçbir parçası gerçekten iyi değildi.
HMM hizalamaları yanlış tahmin eder, GMM benzer sesleri karıştırırdı: /s/ ve /f/, /p/ ve /t/, ve ünlüler konusunda hiç konuşmayalım bile.
Sonra dil modeli, tutarsız fonemleri daha anlamlı bir dile dönüştürürdü.
Derin Öğrenmeyle Uçtan Uca ASR
ASR sürecindeki birçok parça artık birleştirildi.
Artık yazım, hizalama ve telaffuz için ayrı modeller eğitmek yerine, tek bir model konuşmayı alıp (umarız) doğru yazılmış kelimeleri ve günümüzde zaman damgalarını da üretiyor.
(Yine de uygulamalarda bu çıktı genellikle ek bir dil modeliyle düzeltiliyor veya “yeniden puanlanıyor”.)
Bu, farklı faktörlerin — örneğin hizalama ve yazımın — özel ilgi görmediği anlamına gelmiyor. Hâlâ belirli sorunlara odaklanan çok sayıda çalışma var.
Yani, araştırmacılar bir modelin performansının belirli yönlerini hedefleyen mimari değişiklikler geliştiriyor, örneğin:
- Yazımı iyileştirmek için önceki çıktılara göre koşullandırılmış bir RNN-Transducer kod çözücü.
- Boş çıktıları azaltıp hizalamayı iyileştirmek için konvolüsyonel alt örnekleme.
Bunun kulağa karmaşık geldiğini biliyorum. Patronumun “bunu daha basit anlatabilir misin?” demesinin önüne geçmek istedim.
Cevap hayır.
Hayır, anlatamam.
ASR'de Performans Nasıl Ölçülür?
ASR kötü çalıştığında hemen anlarsınız.
"karamelizasyon" kelimesinin "komünist Asyalılar" olarak yazıldığını gördüm. "crispy" ise "Chris p —" olarak yazılmıştı, ne demek istediğimi anladınız.
Hataları matematiksel olarak yansıtmak için kullandığımız ölçüt kelime hata oranıdır (WER). WER formülü şöyledir:
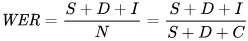
Burada:
- S, yerine koyma sayısıdır (tahmin edilen metnin referans metne uyması için değiştirilen kelimeler)
- D, silme sayısıdır (çıktıda eksik olan kelimeler)
- I, ekleme sayısıdır (çıktıdaki referans metne kıyasla fazladan olan kelimeler)
- N referans metindeki toplam kelime sayısıdır
Örneğin, referans “the cat sat.” olsun.
- Model “the cat sank” derse, bu bir yerine koymadır (substitution).
- Model “cat sat” derse, bu bir silmedir (deletion).
- Model “the cat has sat” derse, bu bir eklemedir (insertion).
ASR'nin Kullanım Alanları Nelerdir?
ASR oldukça pratik bir araçtır.
Ayrıca, önemli sektörlerde güvenlik, erişilebilirlik ve verimliliği artırarak yaşam kalitemizi yükseltmemize yardımcı oldu.
Sağlık
Doktorlara konuşma tanıma üzerine çalıştığımı söylediğimde, “aa, Dragon gibi mi?” diyorlar.
Sağlık sektöründe üretken yapay zeka hayatımıza girmeden önce, doktorlar sınırlı bir kelime dağarcığıyla dakikada 30 kelimeyle sözlü notlar alıyordu.
ASR, doktorların yaşadığı yaygın tükenmişliği azaltmada büyük başarı sağladı.
Doktorlar, hastalarına zaman ayırma ihtiyacı ile yığınla evrak işi arasında denge kuruyor. 2018 gibi erken bir tarihte bile araştırmacılar, doktorların bakım verme yeteneğini artırmak için konsültasyonlarda dijital transkripsiyon kullanımını savunuyordu.
Çünkü konsültasyonları sonradan belgelemek, hastayla yüz yüze geçirilen zamandan çalmakla kalmaz, aynı zamanda gerçek görüşmelerin transkriptlerinin özetlenmesine göre çok daha az doğrudur.
Akıllı Evler
Yaptığım bir espri var.
Işıkları kapatmak istediğimde ama kalkmaya üşendiğimde, iki kez hızlıca alkışlarım — sanki bir clapper'ım varmış gibi.
Partnerim asla gülmez.
Sesle çalışan akıllı evler hem geleceğin teknolojisi gibi hissettiriyor hem de biraz fazla lüks gibi. Ya da öyle görünüyor.
Elbette, kullanışlılar; ama çoğu durumda, başka türlü mümkün olmayan şeyleri yapmayı sağlıyorlar.
Bunun güzel bir örneği enerji tüketimi: Gün içinde aydınlatma ve termostatta küçük ayarlamalar yapmak, kalkıp düğmelerle uğraşmak zorunda olsanız neredeyse imkansız olurdu.
Sesli komutlar sayesinde bu küçük ayarlamaları yapmak hem daha kolay hem de insan konuşmasının inceliklerini algılayabiliyor.
Örneğin, "biraz daha serin yapabilir misin?" diyorsunuz. Asistan, doğal dil işleme kullanarak isteğinizi sıcaklık değişikliğine çeviriyor ve mevcut sıcaklık, hava durumu tahmini, diğer kullanıcıların termostat verileri gibi birçok başka veriyi de hesaba katıyor.
İnsan işini siz yapıyorsunuz, bilgisayara ait işleri de bilgisayara bırakıyorsunuz.
Bence bu, hislerinize göre kaç derece azaltmanız gerektiğini tahmin etmeye çalışmaktan çok daha kolay.
Ve ayrıca daha enerji verimli: Örneğin, sesle kontrol edilen akıllı aydınlatma kullanan ailelerin enerji tüketimini %80'e kadar azalttığı rapor ediliyor.
Müşteri Desteği
Bunu sağlıkta da konuştuk, ancak görüşmeleri yazıya döküp özetlemek, insanların etkileşimleri sonradan özetlemesinden çok daha etkili.
Yine, zaman kazandırıyor ve daha doğru oluyor. Defalarca gördüğümüz gibi, otomasyonlar insanların işlerini daha iyi yapabilmeleri için zaman kazandırıyor.
Ve bu durumun en çok geçerli olduğu alan müşteri desteği; ASR destekli müşteri hizmetlerinde ilk aramada çözüm oranı %25 daha yüksek.
Transkripsiyon ve özetleme, müşterinin duygusu ve sorusuna göre çözüm bulma sürecini otomatikleştirmeye yardımcı oluyor.
Araba İçi Asistanlar
Burada ev asistanlarından yola çıkıyoruz, ama yine de bahsetmeye değer.
Ses tanıma, sürücüler için zihinsel yükü ve görsel dikkat dağınıklığını azaltıyor.
Ve dikkat dağınıklığının çarpışmaların %30'una kadarını oluşturduğu düşünüldüğünde, bu teknolojiyi uygulamak güvenlik açısından tartışmasız bir gereklilik.
Konuşma Patolojisi
ASR uzun süredir konuşma bozukluklarının değerlendirilmesi ve tedavisinde bir araç olarak kullanılıyor.
Makinelerin sadece işleri otomatikleştirmediğini, insanların yapamayacağı şeyleri de yaptığını hatırlamakta fayda var.
Konuşma tanıma, insan kulağının neredeyse algılayamayacağı konuşma inceliklerini tespit edebilir; böylece etkilenen konuşmadaki ayrıntıları yakalayabilir.
ASR'nin Geleceği
STT artık o kadar iyi ki, çoğu zaman farkına bile varmıyoruz.
Ama perde arkasında, araştırmacılar onu daha da güçlü, erişilebilir ve daha az fark edilir yapmak için çalışıyor.
ASR'deki gelişmeleri kullanan bazı heyecan verici eğilimleri seçtim ve kendi düşüncelerimi de ekledim.
Cihaz Üzerinde Konuşma Tanıma
Çoğu ASR çözümü bulutta çalışır. Eminim bunu daha önce duymuşsunuzdur. Yani model başka bir yerde, uzaktaki bir bilgisayarda çalışıyor.
Bunun nedeni, telefonunuzun küçük işlemcisinin devasa modeli çalıştırmaya yetmemesi ya da herhangi bir şeyi yazıya dökmenin çok uzun sürmesidir.
Bunun yerine, sesiniz internet üzerinden, cebinizde taşıyamayacağınız kadar güçlü bir GPU'ya sahip uzak bir sunucuya gönderilir. GPU, ASR modelini çalıştırır ve transkripti cihazınıza geri gönderir.
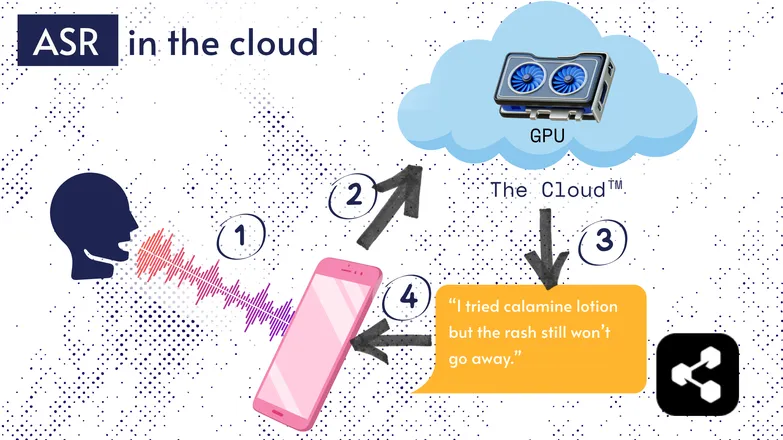
Enerji verimliliği ve güvenlik nedenleriyle (herkes kişisel verilerinin internette dolaşmasını istemez), modelleri doğrudan cihazınızda çalışacak kadar küçük hale getirmek için çok fazla araştırma yapıldı; ister telefon, ister bilgisayar, ister tarayıcı motoru olsun.
Ben de ASR modellerinin kuantizasyonu üzerine bir tez yazdım, böylece cihaz üzerinde çalışabiliyorlar. Picovoice ise düşük gecikmeli cihaz üstü sesli yapay zeka geliştiren Kanadalı bir şirket ve oldukça ilginç görünüyorlar.
Cihaz üstü ASR, transkripsiyonu daha düşük maliyetle erişilebilir kılarak, düşük gelirli topluluklara hizmet etme potansiyeli sunuyor.
Transkript-Öncelikli Arayüz
Ses ile transkriptler arasındaki fark kapanıyor. Bu ne anlama geliyor?
Premiere Pro ve Descript gibi video editörleri, kayıtlarınızı bir transkript üzerinden gezmenizi sağlıyor: bir kelimeye tıklayınca sizi o zaman damgasına götürüyor.
Birden fazla deneme mi yaptınız? Favorinizi seçin ve diğerlerini metin düzenleyici tarzında silin. Video otomatik olarak sizin için kırpılır.
Sadece dalga formuyla bu tür düzenleme yapmak çok zor, ama transkript tabanlı editörlerle inanılmaz kolay.
Benzer şekilde, WhatsApp gibi mesajlaşma servisleri sesli notlarınızı yazıya döküyor ve metin üzerinden hızlıca gezmenizi sağlıyor. Parmağınızı bir kelimenin üzerinde kaydırınca, kaydın o kısmına gidiyorsunuz.

Komik bir hikaye: Aslında bunun gibi bir şeyi Apple benzer bir özellik duyurmadan yaklaşık bir hafta önce ben geliştirmiştim.
Bu örnekler, karmaşık altyapı teknolojilerinin son kullanıcı uygulamalarına nasıl sadelik ve sezgisellik kattığını gösteriyor.
Eşitlik, Kapsayıcılık ve Kaynakları Az Olan Diller
Mücadele henüz bitmedi.
ASR, İngilizce ve diğer yaygın, iyi kaynaklı dillerde harika çalışıyor. Ancak kaynakları az olan dillerde durum aynı değil.
Diyalektik azınlıklar, etkilenmiş konuşmalar ve sesli teknolojide eşitlik gibi konularda hâlâ bir boşluk var.
Keyifli havayı bozduğum için üzgünüm. Burası ASR'nin "geleceği" bölümü. Ve ben, gurur duyacağımız bir geleceğe bakmayı seçiyorum.
İlerlemek istiyorsak, bunu birlikte yapmalıyız; yoksa toplumsal eşitsizliği artırma riskiyle karşı karşıya kalırız.
ASR'yi Bugün Kullanmaya Başlayın
İşiniz ne olursa olsun, ASR kullanmak mantıklı — ancak muhtemelen nereden başlayacağınızı merak ediyorsunuz. ASR'ı nasıl uygularsınız? Bu verileri diğer araçlara nasıl aktarırsınız?
Botpress, kullanımı kolay transkripsiyon kartlarıyla birlikte gelir. Bunlar, sürükle-bırak akışına entegre edilebilir ve uygulamalar ile iletişim kanalları arasında onlarca entegrasyonla güçlendirilebilir.
Hemen oluşturmaya başlayın. Ücretsiz.
Sıkça Sorulan Sorular
Modern ASR farklı aksanlar ve gürültülü ortamlar için ne kadar doğru çalışıyor?
Modern ASR sistemleri, büyük dillerdeki yaygın aksanlar için oldukça yüksek doğruluk sunar ve temiz koşullarda kelime hata oranı (WER) %10'un altındadır; ancak ağır aksan, lehçe veya yoğun arka plan gürültüsünde doğruluk belirgin şekilde düşer. Google ve Microsoft gibi sağlayıcılar modellerini çeşitli konuşma verileriyle eğitir, ancak gürültülü ortamlarda kusursuz transkript hâlâ zordur.
ASR, özel terimler veya sektöre özgü jargonları yazıya dökmekte güvenilir mi?
ASR, kutudan çıktığı haliyle özel terimler veya sektöre özgü jargonlar için daha az güvenilirdir; çünkü eğitim verileri genellikle genel konuşmaya odaklanır ve bilinmeyen kelimeler yanlış yazılabilir veya atlanabilir. Ancak kurumsal çözümler, teknik terimlerin tanınmasını geliştirmek için özel kelime listeleri, alan odaklı dil modelleri ve telaffuz sözlükleri sunar (örneğin sağlık, hukuk veya mühendislikte).
Ücretsiz ASR araçları ile kurumsal çözümler arasındaki fark nedir?
Ücretsiz ASR araçları ile kurumsal çözümler arasındaki fark doğruluk, ölçeklenebilirlik, özelleştirme ve gizlilik kontrollerindedir: Ücretsiz araçlar genellikle daha yüksek hata oranlarına, sınırlı dil desteğine ve kullanım kısıtlamalarına sahipken, kurumsal çözümler daha düşük WER, alan odaklı özelleştirme, entegrasyonlar, hizmet seviyesi anlaşmaları (SLA) ve hassas veriler için güçlü güvenlik özellikleri sunar.
ASR, transkripsiyon sırasında kullanıcı gizliliğini ve hassas bilgileri nasıl korur?
ASR, veri iletimi sırasında şifreleme kullanarak kullanıcı gizliliğini korur ve konuşma verisinin harici sunuculara gönderilmemesi için cihaz üzerinde çalışan modeller gibi seçenekler sunar. Birçok kurumsal sağlayıcı ayrıca GDPR veya HIPAA gibi gizlilik düzenlemelerine uyar ve hassas bilgileri korumak için verileri anonimleştirebilir.
Bulut tabanlı ASR hizmetleri ile cihaz üzerindeki çözümler arasında maliyet farkı nedir?
Bulut tabanlı ASR hizmetleri genellikle ses dakikası başına veya kullanım kademelerine göre ücretlendirir; doğruluk ve özelliklere bağlı olarak dakika başı maliyetler 0,03–1,00+ dolar arasında değişir. Cihaz üzerinde çalışan çözümler ise başlangıçta geliştirme ve lisans ücretleri gerektirir.



