



- ASR mengubah ucapan menjadi teks menggunakan machine learning, memungkinkan perintah suara dan transkripsi secara real-time.
- Sistem ASR modern telah beralih dari model fonem terpisah (HMM-GMM) ke model deep learning yang memprediksi kata secara utuh.
- Kinerja ASR diukur dengan Word Error Rate (WER), di mana kesalahan berasal dari substitusi, penghapusan, atau penambahan kata; WER yang lebih rendah = kualitas transkripsi yang lebih baik.
- Masa depan ASR berfokus pada pemrosesan langsung di perangkat demi privasi dan dukungan untuk bahasa-bahasa dengan sumber daya terbatas.
Kapan terakhir kali Anda menonton sesuatu tanpa subtitle?
Dulu subtitle itu opsional, tapi sekarang mereka selalu muncul di video pendek, mau tidak mau. Teks sudah begitu menyatu dengan konten sampai-sampai kita lupa mereka ada.
Pengenalan ucapan otomatis (ASR) — kemampuan mengubah kata-kata yang diucapkan menjadi teks secara cepat dan akurat — adalah teknologi yang mendorong perubahan ini.
Saat kita memikirkan agen suara AI, kita membayangkan pilihan katanya, cara penyampaiannya, dan suara yang digunakan.
Namun mudah lupa bahwa kelancaran interaksi kita bergantung pada bot yang benar-benar memahami kita. Dan untuk sampai ke titik ini — bot memahami Anda meski ada “eh” dan “hmm” di lingkungan yang bising — bukanlah hal yang mudah.
Hari ini, kita akan membahas teknologi di balik teks otomatis itu: pengenalan ucapan otomatis (ASR).
Perkenalkan, saya memiliki gelar master di bidang teknologi ucapan, dan di waktu luang saya suka membaca perkembangan terbaru tentang ASR, bahkan membuat proyek sendiri.
Saya akan menjelaskan dasar-dasar ASR, mengulas teknologinya, dan mencoba menebak ke mana teknologi ini akan berkembang.
Apa itu ASR?
Pengenalan ucapan otomatis (ASR), atau speech-to-text (STT), adalah proses mengubah ucapan menjadi teks tertulis dengan teknologi machine learning.
Teknologi yang melibatkan ucapan sering mengintegrasikan ASR dalam berbagai bentuk; bisa untuk penambahan teks video, transkripsi interaksi layanan pelanggan untuk analisis, atau bagian dari interaksi asisten suara, dan masih banyak lagi.
Algoritma Speech-to-Text
Teknologi dasarnya telah berubah seiring waktu, namun semua versi selalu terdiri dari dua komponen: data dan model.
Pada ASR, datanya adalah ucapan berlabel – file audio bahasa lisan beserta transkripsinya.
Model adalah algoritma yang digunakan untuk memprediksi transkripsi dari audio. Data berlabel digunakan untuk melatih model, agar dapat mengenali pola dari contoh ucapan yang belum pernah didengar.
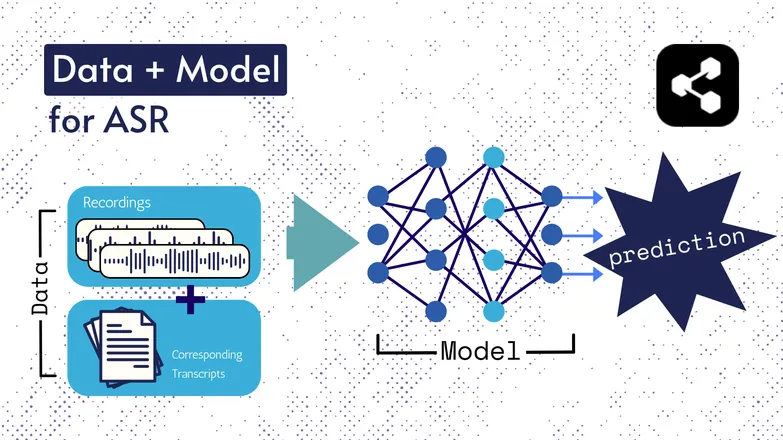
Ini mirip seperti Anda bisa memahami rangkaian kata, meski belum pernah mendengarnya dalam urutan itu, atau diucapkan oleh orang asing.
Sekali lagi, jenis model dan detailnya telah berubah seiring waktu, dan semua kemajuan dalam kecepatan serta akurasi bergantung pada ukuran dan spesifikasi dataset serta modelnya.
Sedikit Catatan: Ekstraksi Fitur
Saya pernah membahas fitur, atau representasi dalam artikel saya tentang text-to-speech. Fitur ini digunakan di model ASR dulu maupun sekarang.
Ekstraksi fitur — mengubah ucapan menjadi fitur — adalah langkah pertama di hampir semua proses ASR.
Singkatnya, fitur-fitur ini, yang sering kali berupa spektrum, adalah hasil perhitungan matematis pada ucapan, dan mengubah ucapan ke format yang menonjolkan kesamaan dalam satu ujaran, serta meminimalkan perbedaan antar penutur.
Artinya, ucapan yang sama dari 2 pembicara berbeda akan menghasilkan spektrum yang mirip, meskipun suara mereka berbeda.
Saya tekankan ini agar Anda tahu bahwa saya akan membahas model yang “memprediksi transkrip dari ucapan”. Sebenarnya, model memprediksi dari fitur. Tapi Anda bisa menganggap ekstraksi fitur sebagai bagian dari model.
ASR Awal: HMM-GMM
Hidden markov models (HMMs) dan Gaussian mixture models (GMMs) adalah model prediktif sebelum deep neural networks menjadi dominan.
HMM mendominasi ASR hingga baru-baru ini.
Diberikan file audio, HMM akan memprediksi durasi fonem, dan GMM akan memprediksi fonemnya.
Kedengarannya terbalik, dan memang agak begitu, seperti:
- HMM: “0,2 detik pertama adalah satu fonem.”
- GMM: “Fonem itu adalah G, seperti pada Gary.”
Mengubah klip audio menjadi teks memerlukan beberapa komponen tambahan, yaitu:
- Kamus pelafalan: daftar lengkap kata dalam kosakata beserta pelafalan masing-masing.
- Model bahasa: Kombinasi kata dalam kosakata, beserta probabilitas kemunculannya bersama.
Jadi meski GMM memprediksi /f/ daripada /s/, model bahasa tahu kemungkinan besar pembicara mengatakan “a penny for your thoughts”, bukan foughts.
Semua bagian ini ada karena, terus terang, tidak ada satu pun bagian dari proses ini yang luar biasa bagus.
HMM sering salah memprediksi penyesuaian waktu, GMM sering keliru membedakan bunyi yang mirip: /s/ dan /f/, /p/ dan /t/, dan jangan tanya soal vokal.
Lalu model bahasa akan merapikan deretan fonem yang kacau menjadi sesuatu yang lebih mirip bahasa.
ASR End-to-End dengan Deep Learning
Banyak bagian dari proses ASR kini telah disederhanakan.
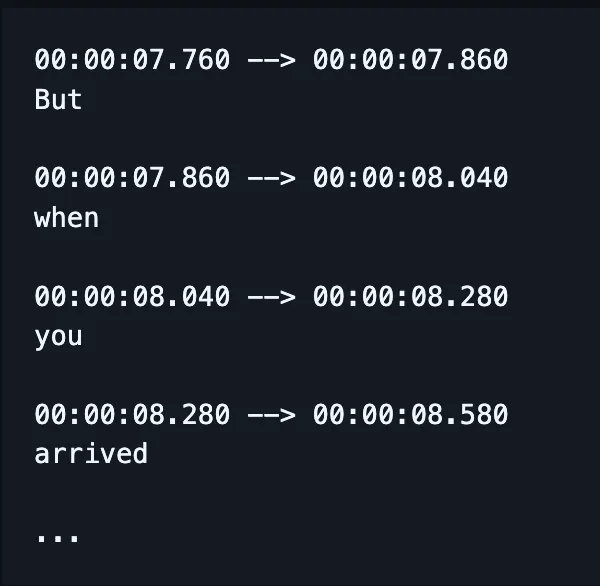
Alih-alih melatih model terpisah untuk ejaan, penyesuaian waktu, dan pelafalan, sebuah model tunggal kini dapat menerima ucapan dan menghasilkan kata-kata yang (semoga) dieja dengan benar, dan sekarang juga dengan penanda waktu.
(Walaupun implementasi sering memperbaiki atau “menilai ulang” hasil ini dengan model bahasa tambahan.)
Bukan berarti faktor-faktor berbeda — seperti penyesuaian waktu dan ejaan — tidak mendapat perhatian khusus. Masih banyak penelitian yang fokus pada solusi untuk masalah-masalah sangat spesifik.
Artinya, peneliti menemukan cara mengubah arsitektur model untuk menargetkan faktor tertentu dari performanya, misalnya:
- Decoder RNN-Transducer yang mempertimbangkan output sebelumnya untuk meningkatkan ejaan.
- Convolutional downsampling untuk membatasi output kosong, sehingga penyesuaian waktu lebih baik.
Saya tahu ini terdengar rumit. Saya hanya mengantisipasi atasan saya yang akan bertanya “bisa kasih contoh yang mudah dimengerti?”
Jawabannya tidak bisa.
Tidak bisa.
Bagaimana Kinerja ASR Diukur?
Kalau ASR bekerja buruk, Anda pasti tahu.
Saya pernah melihat caramelization ditranskripsi jadi communist Asians. Crispiness jadi Chris p — Anda paham maksudnya.
Metrik yang kita gunakan untuk mengukur kesalahan secara matematis adalah word error rate (WER). Rumus WER adalah:
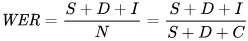
Di mana:
- S adalah jumlah substitusi (kata yang diubah pada teks prediksi agar sesuai dengan referensi)
- D adalah jumlah penghapusan (kata yang hilang dari output dibanding referensi)
- I adalah jumlah penambahan (kata tambahan pada output dibanding referensi)
- N adalah jumlah total kata pada referensi
Misalnya, referensi adalah “the cat sat.”
- Jika model menghasilkan “the cat sank”, itu substitusi.
- Jika model menghasilkan “cat sat”, itu penghapusan.
- Jika hasilnya “the cat has sat”, itu penambahan.
Apa Saja Aplikasi ASR?
ASR adalah alat yang sangat berguna.
Teknologi ini juga membantu meningkatkan kualitas hidup kita lewat peningkatan keamanan, aksesibilitas, dan efisiensi di berbagai sektor penting.
Kesehatan
Saat saya bilang ke dokter bahwa saya meneliti pengenalan ucapan, mereka bilang “oh, seperti Dragon.”
Sebelum ada AI generatif di bidang kesehatan, dokter mencatat secara lisan dengan kecepatan 30 kata per menit dan kosakata yang terbatas.
ASR sangat berhasil mengurangi kelelahan yang sering dialami para dokter.
Dokter harus menyeimbangkan tumpukan dokumen dengan kebutuhan untuk merawat pasien. Sejak 2018, para peneliti sudah menganjurkan penggunaan transkripsi digital dalam konsultasi untuk meningkatkan kemampuan dokter dalam memberikan perawatan.
Ini karena mendokumentasikan konsultasi secara retroaktif tidak hanya mengurangi waktu tatap muka dengan pasien, tapi juga jauh kurang akurat dibandingkan ringkasan dari transkripsi konsultasi yang sebenarnya.
Rumah Pintar
Saya punya lelucon tentang ini.
Saat ingin mematikan lampu tapi malas bangun, saya bertepuk tangan dua kali dengan cepat—seolah-olah punya alat clapper.
Pasangan saya tidak pernah tertawa.
Rumah pintar yang diaktifkan suara terasa futuristik sekaligus agak berlebihan. Atau setidaknya begitu kesannya.
Memang praktis, tapi dalam banyak kasus, teknologi ini memungkinkan hal-hal yang sebelumnya tidak bisa dilakukan.
Contohnya konsumsi energi: melakukan penyesuaian kecil pada lampu dan termostat akan sulit dilakukan sepanjang hari jika harus bangun dan memutar tombol.
Dengan aktivasi suara, penyesuaian kecil itu jadi lebih mudah, dan sistem bisa memahami nuansa dalam ucapan manusia.
Misalnya, Anda berkata “bisa dibuat sedikit lebih dingin?” Asisten menggunakan pemrosesan bahasa alami untuk menerjemahkan permintaan Anda menjadi perubahan suhu, dengan mempertimbangkan banyak data lain: suhu saat ini, prakiraan cuaca, data penggunaan termostat pengguna lain, dan sebagainya.
Anda melakukan bagian manusianya, dan biarkan komputer mengurus bagian komputernya.
Menurut saya, ini jauh lebih mudah daripada Anda harus menebak berapa derajat suhu harus diturunkan berdasarkan perasaan.
Dan ini juga lebih hemat energi: ada laporan keluarga yang mengurangi konsumsi energi hingga 80% dengan pencahayaan pintar yang diaktifkan suara, sebagai salah satu contohnya.
Dukungan Pelanggan
Kita sudah membahas ini di bidang kesehatan, tapi proses transkripsi dan ringkasan jauh lebih efektif daripada orang yang merangkum interaksi secara retroaktif.
Lagi-lagi, ini menghemat waktu dan lebih akurat. Yang terus kita pelajari adalah otomatisasi memberi lebih banyak waktu bagi orang untuk bekerja lebih baik.
Dan hal ini paling terasa di layanan pelanggan, di mana dukungan pelanggan yang didukung ASR memiliki tingkat penyelesaian panggilan pertama 25% lebih tinggi.
Transkripsi dan ringkasan membantu mengotomatisasi proses mencari solusi berdasarkan sentimen dan pertanyaan pelanggan.
Asisten di Dalam Mobil
Kita meniru konsep asisten rumah di sini, tapi tetap layak disebutkan.
Pengenalan suara mengurangi beban kognitif dan gangguan visual bagi pengemudi.
Dan karena gangguan menyumbang hingga 30% kecelakaan, penerapan teknologi ini jelas penting untuk keselamatan.
Patologi Wicara
ASR sudah lama digunakan sebagai alat untuk menilai dan menangani gangguan bicara.
Penting diingat bahwa mesin tidak hanya mengotomatisasi tugas, tapi juga melakukan hal-hal yang tidak bisa dilakukan manusia.
Pengenalan suara dapat mendeteksi detail halus dalam ucapan yang hampir tidak terdengar oleh telinga manusia, menangkap ciri khas ucapan yang mungkin terlewatkan.
Masa Depan ASR
STT kini sudah sangat baik hingga kita tidak lagi memikirkannya.
Namun di balik layar, para peneliti terus bekerja keras agar teknologi ini makin kuat, mudah diakses, dan makin tidak terasa kehadirannya.
Saya memilih beberapa tren menarik yang memanfaatkan kemajuan ASR, dan menambahkan sedikit pemikiran saya sendiri.
Pengenalan Suara di Perangkat
Sebagian besar solusi ASR berjalan di cloud. Saya yakin Anda sudah sering mendengarnya. Artinya, model dijalankan di komputer jarak jauh, bukan di perangkat Anda.
Ini dilakukan karena prosesor kecil di ponsel Anda belum tentu mampu menjalankan model besar mereka, atau proses transkripsi akan sangat lama.
Sebagai gantinya, audio Anda dikirim melalui internet ke server jarak jauh yang menjalankan GPU yang terlalu besar untuk dibawa di saku. GPU menjalankan model ASR, lalu mengirimkan hasil transkripsi ke perangkat Anda.
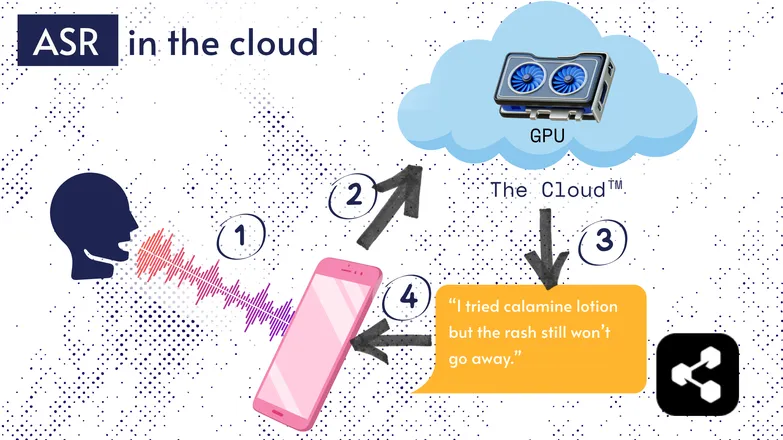
Demi efisiensi energi dan keamanan (tidak semua orang ingin data pribadinya tersebar di dunia maya), banyak penelitian dilakukan untuk membuat model cukup ringkas agar bisa dijalankan langsung di perangkat Anda, baik itu ponsel, komputer, atau browser.
Saya sendiri menulis tesis tentang kuantisasi model ASR agar bisa dijalankan di perangkat. Picovoice adalah perusahaan Kanada yang mengembangkan AI suara di perangkat dengan latensi rendah, dan mereka tampak menarik.
ASR di perangkat membuat transkripsi lebih terjangkau, dengan potensi menjangkau komunitas berpenghasilan rendah.
UI Berbasis Transkrip
Jarak antara audio dan transkripsi makin kecil. Apa artinya?
Editor video seperti Premiere Pro dan Descript memungkinkan Anda menavigasi rekaman lewat transkrip: klik kata, langsung ke waktu rekaman tersebut.
Harus mengulang beberapa kali? Pilih yang paling kamu suka dan hapus sisanya, seperti mengedit teks. Video akan dipotong secara otomatis untukmu.
Sangat merepotkan mengedit hanya dengan gelombang suara, tapi jadi sangat mudah dengan editor berbasis transkrip.
Begitu juga layanan pesan seperti WhatsApp yang mentranskripsi pesan suara dan memungkinkan Anda menelusurinya lewat teks. Geser jari ke kata tertentu, Anda langsung ke bagian rekaman itu.

Cerita lucu: Saya sebenarnya membuat sesuatu seperti ini sekitar seminggu sebelum Apple mengumumkan fitur serupa.
Contoh-contoh ini menunjukkan bagaimana teknologi kompleks di balik layar membawa kemudahan dan kejelasan pada aplikasi untuk pengguna akhir.
Kesetaraan, Inklusi, dan Bahasa Sumber Daya Rendah
Perjuangan belum selesai.
ASR bekerja sangat baik untuk bahasa Inggris dan bahasa umum lain yang sumber dayanya banyak. Tapi tidak selalu demikian untuk bahasa dengan sumber daya rendah.
Ada kesenjangan pada dialek minoritas, ucapan yang terpengaruh, dan masalah lain terkait kesetaraan dalam teknologi suara.
Maaf mengurangi semangat positif. Bagian ini membahas “masa depan” ASR. Dan saya memilih menantikan masa depan yang bisa kita banggakan.
Jika ingin maju, kita harus melakukannya bersama, atau risiko ketimpangan sosial akan makin besar.
Mulai Gunakan ASR Hari Ini
Apa pun jenis bisnismu, menggunakan ASR adalah pilihan yang jelas — tapi kamu mungkin bertanya-tanya bagaimana cara memulainya. Bagaimana cara mengimplementasikan ASR? Bagaimana cara meneruskan data itu ke alat lain?
Botpress menyediakan kartu transkripsi yang mudah digunakan. Kartu ini bisa diintegrasikan ke dalam flow drag-and-drop, dilengkapi dengan puluhan integrasi ke berbagai aplikasi dan saluran komunikasi.
Mulai bangun hari ini. Gratis.
FAQ
Seberapa akurat ASR modern untuk berbagai aksen dan lingkungan yang bising?
Sistem ASR modern sangat akurat untuk aksen umum dalam bahasa utama, dengan tingkat kesalahan kata (WER) di bawah 10% dalam kondisi bersih, namun akurasi menurun secara signifikan pada aksen berat, dialek, atau kebisingan latar yang tinggi. Vendor seperti Google dan Microsoft melatih model dengan data suara yang beragam, tetapi transkripsi sempurna di lingkungan bising masih menjadi tantangan.
Apakah ASR dapat diandalkan untuk mentranskripsi istilah khusus atau jargon industri?
ASR kurang andal secara langsung untuk jargon khusus atau istilah industri karena data pelatihannya biasanya lebih banyak pada percakapan umum; kata-kata yang tidak dikenal bisa salah transkripsi atau terlewat. Namun, solusi untuk perusahaan memungkinkan penambahan kosakata khusus, model bahasa khusus bidang, dan kamus pengucapan untuk meningkatkan pengenalan istilah teknis di bidang seperti kesehatan, hukum, atau teknik.
Apa perbedaan antara alat ASR gratis dan solusi enterprise?
Perbedaan antara alat ASR gratis dan solusi enterprise terletak pada akurasi, skalabilitas, penyesuaian, dan kontrol privasi: alat gratis biasanya memiliki tingkat kesalahan lebih tinggi, dukungan bahasa terbatas, dan batasan penggunaan, sedangkan solusi enterprise menawarkan WER lebih rendah, penyesuaian khusus domain, integrasi, perjanjian tingkat layanan (SLA), serta fitur keamanan kuat untuk menangani data sensitif.
Bagaimana ASR melindungi privasi pengguna dan informasi sensitif selama transkripsi?
ASR melindungi privasi pengguna dengan enkripsi selama transmisi data dan menyediakan opsi seperti menjalankan model di perangkat agar data suara tidak dikirim ke server eksternal. Banyak penyedia tingkat perusahaan juga mematuhi regulasi privasi seperti GDPR atau HIPAA dan dapat menganonimkan data untuk menjaga keamanan informasi sensitif.
Seberapa mahal layanan ASR berbasis cloud dibandingkan solusi di perangkat?
Layanan ASR berbasis cloud biasanya mengenakan biaya per menit audio atau berdasarkan tingkat penggunaan, dengan harga mulai dari $0,03–$1,00+ per menit tergantung akurasi dan fitur, sementara solusi di perangkat melibatkan biaya pengembangan awal dan lisensi.



