



- ASR zet spraak om in tekst met behulp van machine learning, waardoor spraakopdrachten en realtime transcriptie mogelijk worden.
- Moderne ASR-systemen zijn overgestapt van aparte fonemodellen (HMM-GMM) naar deep learning-modellen die hele woorden voorspellen.
- ASR-prestaties worden gemeten met de Word Error Rate (WER), waarbij fouten ontstaan door vervangingen, weglatingen of toevoegingen; een lagere WER = betere transcriptiekwaliteit.
- De toekomst van ASR richt zich op verwerking op het apparaat zelf voor privacy en ondersteuning van talen met weinig middelen.
Wanneer heb je voor het laatst iets gekeken zonder ondertiteling?
Vroeger waren ze optioneel, maar nu verschijnen ze overal in korte video's, of we het nu willen of niet. Ondertitels zijn zo verweven met de inhoud dat je vergeet dat ze er zijn.
Automatische spraakherkenning (ASR) — het vermogen om snel en nauwkeurig gesproken woorden automatisch om te zetten in tekst — is de technologie die deze verschuiving mogelijk maakt.
Als we denken aan een AI-spraakagent, denken we aan zijn woordkeuze, manier van spreken en de stem waarmee hij spreekt.
Maar het is makkelijk te vergeten dat de soepelheid van onze interacties afhangt van het feit dat de bot ons begrijpt. En dat bereiken — de bot die je begrijpt ondanks 'eh' en 'uh' in een rumoerige omgeving — is geen eenvoudige opgave geweest.
Vandaag gaan we het hebben over de technologie achter die ondertitels: automatische spraakherkenning (ASR).
Even voorstellen: ik heb een master in spraaktechnologie en in mijn vrije tijd lees ik graag over de nieuwste ontwikkelingen in ASR, en bouw ik zelfs dingen.
Ik leg je de basis van ASR uit, kijk onder de motorkap van de technologie en doe een gok waar de technologie naartoe gaat.
Wat is ASR?
Automatische spraakherkenning (ASR), of spraak-naar-tekst (STT), is het proces waarbij spraak wordt omgezet in geschreven tekst met behulp van machine learning-technologie.
Technologieën waarbij spraak een rol speelt, integreren vaak op de een of andere manier ASR; bijvoorbeeld voor video-ondertiteling, het transcriberen van klantgesprekken voor analyse, of als onderdeel van een spraakassistent-interactie, om er een paar te noemen.
Spraak-naar-tekst-algoritmen
De onderliggende technologieën zijn door de jaren heen veranderd, maar alle varianten bestaan uit twee onderdelen in een of andere vorm: data en een model.
In het geval van ASR is de data gelabelde spraak – audiobestanden van gesproken taal met bijbehorende transcripties.
Het model is het algoritme dat de transcriptie uit de audio voorspelt. De gelabelde data wordt gebruikt om het model te trainen, zodat het kan generaliseren naar onbekende spraakvoorbeelden.
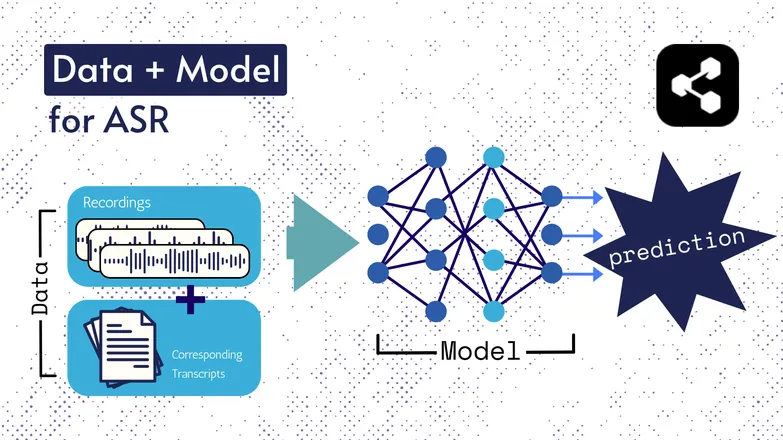
Het lijkt op hoe jij een reeks woorden kunt begrijpen, zelfs als je ze nog nooit in die volgorde hebt gehoord, of als ze door een onbekende worden uitgesproken.
Nogmaals, de soorten modellen en hun details zijn in de loop der tijd veranderd, en alle vooruitgang in snelheid en nauwkeurigheid komt neer op de grootte en specificaties van de datasets en modellen.
Korte zijstap: Feature Extractie
Ik sprak over features, of representaties in mijn artikel over tekst-naar-spraak. Ze worden gebruikt in ASR-modellen, vroeger en nu.
Feature extractie — spraak omzetten in features — is de eerste stap in vrijwel alle ASR-processen.
Kort gezegd zijn deze features, vaak spectrogrammen, het resultaat van een wiskundige bewerking op spraak, en zetten ze spraak om in een formaat dat overeenkomsten binnen een uiting benadrukt en verschillen tussen sprekers minimaliseert.
Dus: dezelfde uiting, uitgesproken door twee verschillende sprekers, levert vergelijkbare spectrogrammen op, ongeacht hoe verschillend hun stemmen zijn.
Ik geef dit aan zodat je weet dat ik het heb over modellen die 'transcripties voorspellen uit spraak'. Dat is technisch gezien niet helemaal juist; modellen voorspellen op basis van features. Maar je kunt het onderdeel feature extractie als deel van het model zien.
Vroege ASR: HMM-GMM
Hidden Markov-modellen (HMM's) en Gaussian Mixture Models (GMM's) zijn voorspellende modellen van vóór deep neural networks de standaard werden.
HMM's waren tot voor kort dominant in ASR.
Bij een audiobestand voorspelde de HMM de duur van een foneem, en de GMM voorspelde het foneem zelf.
Dat klinkt omgekeerd, en dat is het eigenlijk ook, bijvoorbeeld:
- HMM: “De eerste 0,2 seconde is een foneem.”
- GMM: “Dat foneem is een G, zoals in Gerrit.”
Om van een audioclip naar tekst te gaan, waren er nog een paar extra onderdelen nodig, namelijk:
- Een uitspraakwoordenboek: een volledige lijst van de woorden in de woordenschat, met hun bijbehorende uitspraken.
- Een taalmodel: combinaties van woorden in de woordenschat, en de waarschijnlijkheid dat ze samen voorkomen.
Dus zelfs als de GMM /f/ voorspelt in plaats van /s/, weet het taalmodel dat het veel waarschijnlijker is dat de spreker 'a penny for your thoughts' zei, en niet foughts.
We hadden al deze onderdelen omdat, om het maar direct te zeggen, geen enkel deel van deze keten echt goed was.
De HMM voorspelde uitlijningen verkeerd, de GMM haalde vergelijkbare klanken door elkaar: /s/ en /f/, /p/ en /t/, en over klinkers zal ik maar niet beginnen.
En dan ruimde het taalmodel de rommel van onsamenhangende fonemen op tot iets dat meer op taal leek.
End-to-End ASR met Deep Learning
Veel onderdelen van een ASR-keten zijn inmiddels samengevoegd.
In plaats van aparte modellen te trainen voor spelling, uitlijning en uitspraak, neemt één model nu spraak op en geeft (hopelijk) correct gespelde woorden, en tegenwoordig ook tijdsaanduidingen.
(Hoewel implementaties deze output vaak corrigeren of 'herwaarderen' met een extra taalmodel.)
Dat betekent niet dat verschillende factoren — zoals uitlijning en spelling — geen aparte aandacht krijgen. Er is nog steeds veel onderzoek naar het oplossen van zeer specifieke problemen.
Dat wil zeggen: onderzoekers bedenken manieren om de architectuur van een model aan te passen die gericht zijn op specifieke prestatieaspecten, zoals:
- Een RNN-Transducer-decoder die rekening houdt met eerdere uitkomsten om spelling te verbeteren.
- Convolutionele downsampling om lege uitkomsten te beperken en de uitlijning te verbeteren.
Ik weet dat dit onbegrijpelijk klinkt. Ik loop alvast vooruit op mijn baas die vraagt: 'Kun je een voorbeeld in gewone taal geven?'
Het antwoord is nee.
Nee, dat kan ik niet.
Hoe meet je prestaties bij ASR?
Als ASR het slecht doet, merk je het meteen.
Ik heb caramelization zien transcriberen als communist Asians. Crispiness werd Chris p — je snapt het idee.
De maatstaf die we gebruiken om fouten wiskundig weer te geven is de word error rate (WER). De formule voor WER is:
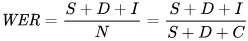
Waarbij:
- S is het aantal vervangingen (woorden die in de voorspelde tekst zijn gewijzigd om overeen te komen met de referentietekst)
- D is het aantal verwijderingen (woorden die ontbreken in de output ten opzichte van de referentietekst)
- I is het aantal toevoegingen (extra woorden in de output ten opzichte van de referentietekst)
- N is het totaal aantal woorden in de referentie
Stel, de referentie is 'de kat zat.'
- Als het model 'de kat zonk' geeft, is dat een vervanging.
- Als het model 'kat zat' geeft, is dat een verwijdering.
- Als het 'de kat heeft gezeten' geeft, is dat een toevoeging.
Wat zijn de toepassingen van ASR?
ASR is een handig hulpmiddel.
Het heeft ons ook geholpen onze levenskwaliteit te verbeteren door meer veiligheid, toegankelijkheid en efficiëntie in belangrijke sectoren.
Zorg
Als ik artsen vertel dat ik onderzoek doe naar spraakherkenning, zeggen ze: 'Oh, zoals Dragon.'
Voordat we generatieve AI in de gezondheidszorg hadden, maakten artsen mondelinge aantekeningen met een beperkt vocabulaire en een tempo van 30 woorden per minuut.
ASR heeft enorm geholpen om de wijdverspreide burn-out onder artsen te verminderen.
Artsen moeten bergen papierwerk combineren met de zorg voor hun patiënten. Al in 2018 riepen onderzoekers op tot het gebruik van digitale transcriptie tijdens consulten om artsen te helpen betere zorg te bieden.
Dat komt omdat het achteraf documenteren van consulten niet alleen ten koste gaat van de tijd met patiënten, maar ook veel minder nauwkeurig is dan het samenvatten van transcripties van daadwerkelijke gesprekken.
Smart Homes
Ik heb hier een grapje over.
Als ik het licht uit wil doen maar geen zin heb om op te staan, klap ik twee keer snel achter elkaar — alsof ik een clapper heb.
Mijn partner lacht nooit.
Spraakgestuurde smart homes voelen zowel futuristisch als een beetje overdadig. Of zo lijkt het.
Ze zijn zeker handig, maar in veel gevallen maken ze dingen mogelijk die anders niet zouden kunnen.
Een goed voorbeeld is energieverbruik: kleine aanpassingen aan verlichting of thermostaat zijn gedurende de dag onpraktisch als je telkens moet opstaan en aan een knop moet draaien.
Met spraakbediening zijn die kleine aanpassingen niet alleen makkelijker, maar begrijpt het systeem ook de nuances van menselijke spraak.
Zeg bijvoorbeeld: “kan het iets koeler?” De assistent gebruikt natuurlijke taalverwerking om je verzoek om te zetten in een temperatuurwijziging, waarbij allerlei andere gegevens worden meegenomen: de huidige temperatuur, het weerbericht, het gebruik van andere gebruikers, enzovoort.
Jij doet het menselijke deel, en laat het technische werk aan de computer over.
Dat is volgens mij veel makkelijker dan zelf inschatten hoeveel graden je de verwarming lager moet zetten op gevoel.
En het is ook energiezuiniger: er zijn meldingen van gezinnen die tot 80% minder energie verbruiken dankzij spraakgestuurde slimme verlichting, om maar een voorbeeld te geven.
Klantenservice
We hadden het hier al over in de gezondheidszorg, maar transcriptie en samenvatting zijn veel effectiever dan mensen die achteraf een samenvatting geven van een gesprek.
Het bespaart opnieuw tijd en is nauwkeuriger. Wat we steeds weer zien, is dat automatisering mensen tijd geeft om hun werk beter te doen.
En nergens geldt dat meer dan bij de klantenservice, waar door ASR ondersteunde klantenservice een 25% hogere oplossing bij het eerste contact behaalt.
Transcriptie en samenvatting helpen het proces te automatiseren om een oplossing te vinden op basis van de stemming en vraag van de klant.
In-Car Assistants
We bouwen hier voort op de thuisassistenten, maar het verdient zeker een vermelding.
Spraakherkenning vermindert de mentale belasting en visuele afleiding voor bestuurders.
En omdat afleiding tot 30% van de aanrijdingen veroorzaakt, is het invoeren van deze technologie een logische keuze voor de veiligheid.
Logopedie
ASR wordt al lange tijd gebruikt als hulpmiddel bij het beoordelen en behandelen van spraakstoornissen.
Het is goed om te onthouden dat machines niet alleen taken automatiseren, maar ook dingen doen die mensen niet kunnen.
Spraakherkenning kan subtiliteiten in spraak opvangen die voor het menselijk oor bijna niet waarneembaar zijn, en zo details detecteren die anders onopgemerkt zouden blijven.
De toekomst van ASR
STT is inmiddels zo goed geworden dat we er niet meer bij stilstaan.
Maar achter de schermen werken onderzoekers hard om het nog krachtiger, toegankelijker en minder opvallend te maken.
Ik heb een paar interessante trends uitgekozen die voortbouwen op de vooruitgang in ASR, met wat eigen gedachten erbij.
On-Device Spraakherkenning
De meeste ASR-oplossingen draaien in de cloud. Dat heb je vast vaker gehoord. Dat betekent dat het model draait op een externe computer, ergens anders.
Dat doen ze omdat de processor van je telefoon vaak niet krachtig genoeg is voor zo'n groot model, of het zou veel te lang duren om iets te transcriberen.
In plaats daarvan wordt je audio via internet verstuurd naar een externe server met een GPU die veel te zwaar is om in je broekzak te stoppen. De GPU draait het ASR-model en stuurt de transcriptie terug naar je apparaat.
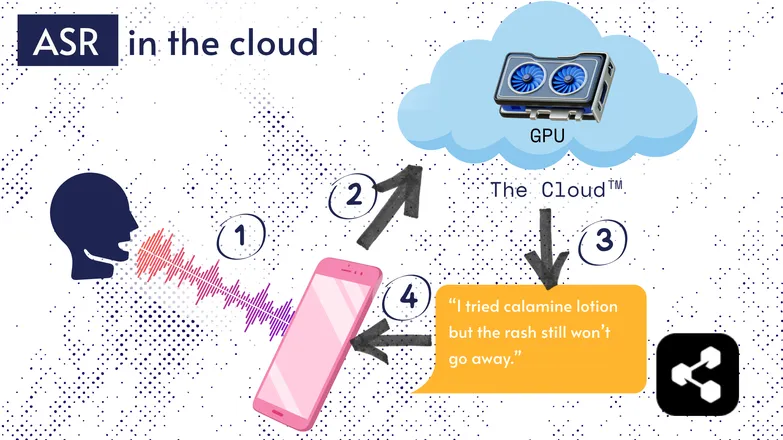
Omwille van energiezuinigheid en privacy (niet iedereen wil dat zijn persoonlijke data overal rondzweeft), is er veel onderzoek gedaan om modellen klein genoeg te maken zodat ze direct op je apparaat kunnen draaien, of dat nu een telefoon, computer of browser is.
Ikzelf heb een scriptie geschreven over het kwantiseren van ASR-modellen zodat ze op het apparaat zelf kunnen draaien. Picovoice is een Canadees bedrijf dat werkt aan snelle on-device voice-AI, en dat ziet er veelbelovend uit.
On-device ASR maakt transcriptie goedkoper beschikbaar, met de mogelijkheid om ook minderbedeelde gemeenschappen te bedienen.
Transcript-First UI
De kloof tussen audio en transcripties wordt kleiner. Wat betekent dat?
Videobewerkers zoals Premiere Pro en Descript laten je door je opnames navigeren via een transcript: klik op een woord en je springt naar het juiste tijdstip.
Meerdere pogingen nodig gehad? Kies je favoriet en verwijder de rest, net als in een teksteditor. De video wordt automatisch voor je bijgesneden.
Het is behoorlijk frustrerend om zo te editen met alleen een geluidsweergave, maar transcript-gebaseerde editors maken het juist heel eenvoudig.
Op dezelfde manier transcriberen berichtenapps zoals WhatsApp je spraakberichten en kun je via de tekst door het bericht scrollen. Veeg over een woord en je springt naar dat deel van de opname.

Grappig verhaal: ik had zoiets als dit gebouwd ongeveer een week voordat Apple een vergelijkbare functie aankondigde.
Deze voorbeelden laten zien hoe complexe technologieën onder de motorkap zorgen voor eenvoud en gebruiksgemak in applicaties voor eindgebruikers.
Gelijkheid, inclusie en talen met beperkte middelen
De strijd is nog niet gestreden.
ASR werkt uitstekend in het Engels en andere veelgebruikte, goed ondersteunde talen. Dat geldt niet altijd voor talen met weinig middelen.
Er is een kloof bij dialecten, afwijkende spraak en andere kwesties rond gelijkheid in spraaktechnologie.
Sorry dat ik de positieve sfeer onderbreek. Dit deel heet de “toekomst” van ASR. En ik kies ervoor om uit te kijken naar een toekomst waar we trots op kunnen zijn.
Als we vooruit willen, moeten we dat samen doen, anders vergroten we de maatschappelijke ongelijkheid.
Begin vandaag nog met ASR
Welke branche je ook hebt, ASR gebruiken is een logische stap — maar je vraagt je waarschijnlijk af hoe je moet beginnen. Hoe implementeer je ASR? Hoe geef je die data door aan andere tools?
Botpress biedt gebruiksvriendelijke transcriptiekaarten. Je kunt ze integreren in een drag-and-drop flow en aanvullen met tientallen integraties voor applicaties en communicatiekanalen.
Begin vandaag nog met bouwen. Het is gratis.
Veelgestelde vragen
Hoe nauwkeurig is moderne ASR voor verschillende accenten en in rumoerige omgevingen?
Moderne ASR-systemen zijn indrukwekkend nauwkeurig voor gangbare accenten in grote talen, met woordfoutpercentages (WER) onder de 10% in rustige omstandigheden. De nauwkeurigheid neemt echter merkbaar af bij sterke accenten, dialecten of veel achtergrondgeluid. Leveranciers zoals Google en Microsoft trainen hun modellen op diverse spraakdata, maar perfecte transcriptie in lawaaierige omgevingen blijft een uitdaging.
Is ASR betrouwbaar voor het transcriberen van gespecialiseerd jargon of branchespecifieke termen?
ASR is minder betrouwbaar voor gespecialiseerd jargon of branchespecifieke termen, omdat de trainingsdata meestal gericht is op algemene spraak; onbekende woorden kunnen verkeerd getranscribeerd of weggelaten worden. Zakelijke oplossingen bieden echter de mogelijkheid om aangepaste woordenlijsten, domeinspecifieke taalmodellen en uitspraakwoordenboeken toe te voegen, zodat technische termen in bijvoorbeeld de zorg, juridische sector of techniek beter herkend worden.
Wat is het verschil tussen gratis ASR-tools en zakelijke oplossingen?
Het verschil tussen gratis ASR-tools en zakelijke oplossingen zit in nauwkeurigheid, schaalbaarheid, maatwerk en privacy: gratis tools hebben vaak een hogere foutmarge, beperkte taalondersteuning en gebruikslimieten, terwijl zakelijke oplossingen een lagere WER, domeinspecifiek maatwerk, integraties, service level agreements (SLA’s) en sterke beveiligingsfuncties bieden voor het verwerken van gevoelige data.
Hoe beschermt ASR de privacy van gebruikers en gevoelige informatie tijdens transcriptie?
ASR beschermt de privacy van gebruikers door versleuteling tijdens de gegevensoverdracht en biedt opties zoals het uitvoeren van modellen op het apparaat zelf, zodat spraakgegevens niet naar externe servers worden gestuurd. Veel zakelijke aanbieders voldoen ook aan privacywetgeving zoals de AVG of HIPAA en kunnen gegevens anonimiseren om gevoelige informatie te beschermen.
Hoe duur zijn cloudgebaseerde ASR-diensten in vergelijking met oplossingen op het apparaat zelf?
Cloudgebaseerde ASR-diensten rekenen meestal per audiominuut of via gebruiksniveaus, met kosten van $0,03 tot meer dan $1,00 per minuut afhankelijk van nauwkeurigheid en functies, terwijl on-device oplossingen eenmalige ontwikkelkosten en licentiekosten met zich meebrengen.



