



- يقوم ASR بتحويل الكلام إلى نص باستخدام التعلم الآلي، مما يتيح الأوامر الصوتية والنسخ الفوري.
- انتقلت أنظمة ASR الحديثة من نماذج الفونيم المنفصلة (HMM-GMM) إلى نماذج التعلم العميق التي تتنبأ بالكلمات الكاملة.
- يتم قياس أداء ASR بمعدل خطأ الكلمات (WER)، حيث تنشأ الأخطاء من الاستبدالات أو الحذف أو الإدراج؛ كلما كان WER أقل، كانت جودة النسخ أفضل.
- يركز مستقبل ASR على المعالجة على الجهاز من أجل الخصوصية ودعم اللغات ذات الموارد المحدودة.
متى كانت آخر مرة شاهدت فيها شيئًا بدون ترجمات؟
كانت الترجمة في السابق اختيارية، أما الآن فهي تظهر في مقاطع الفيديو القصيرة سواء أردنا ذلك أم لا. أصبحت العناوين الفرعية جزءًا من المحتوى لدرجة أنك قد تنسى وجودها.
التعرف التلقائي على الكلام (ASR) — القدرة على تحويل الكلمات المنطوقة إلى نص بسرعة ودقة — هو التقنية التي تدعم هذا التحول.
عندما نفكر في وكيل صوتي بالذكاء الاصطناعي، نفكر في اختيار كلماته، وأسلوب إلقائه، والصوت الذي يتحدث به.
لكن من السهل أن ننسى أن سلاسة تفاعلنا تعتمد على فهم الروبوت لنا. والوصول إلى هذه المرحلة — أن يفهمك الروبوت رغم الترددات والكلام غير الواضح في بيئة صاخبة — لم يكن أمرًا سهلاً.
اليوم، سنتحدث عن التقنية التي تدعم هذه العناوين الفرعية: التعرف التلقائي على الكلام (ASR).
اسمحوا لي أن أقدم نفسي: أحمل درجة الماجستير في تقنيات الكلام، وفي وقت فراغي أحب متابعة آخر مستجدات ASR، بل وأقوم أحيانًا بتطوير بعض المشاريع.
سأشرح لكم أساسيات ASR، وألقي نظرة على التقنية من الداخل، وأتوقع إلى أين قد تتجه هذه التقنية لاحقًا.
ما هو ASR؟
التعرف التلقائي على الكلام (ASR)، أو التحويل من الكلام إلى نص (STT)، هو عملية تحويل الكلام إلى نص مكتوب باستخدام تقنيات التعلم الآلي.
غالبًا ما تدمج التقنيات التي تتعلق بالكلام ASR بشكل أو بآخر؛ فقد يكون ذلك لإضافة العناوين الفرعية للفيديو، أو نسخ تفاعلات دعم العملاء للتحليل، أو كجزء من تفاعل مساعد صوتي، على سبيل المثال لا الحصر.
خوارزميات التحويل من الكلام إلى نص
تغيرت التقنيات الأساسية على مر السنين، لكن جميع الإصدارات تضمنت عنصرين بشكل أو بآخر: البيانات والنموذج.
في حالة ASR، البيانات هي كلام موسوم — ملفات صوتية للغة المنطوقة مع نصوصها المطابقة.
النموذج هو الخوارزمية المستخدمة للتنبؤ بالنص من الصوت. تُستخدم البيانات الموسومة لتدريب النموذج، حتى يتمكن من التعميم على أمثلة كلام لم يسبق له رؤيتها.
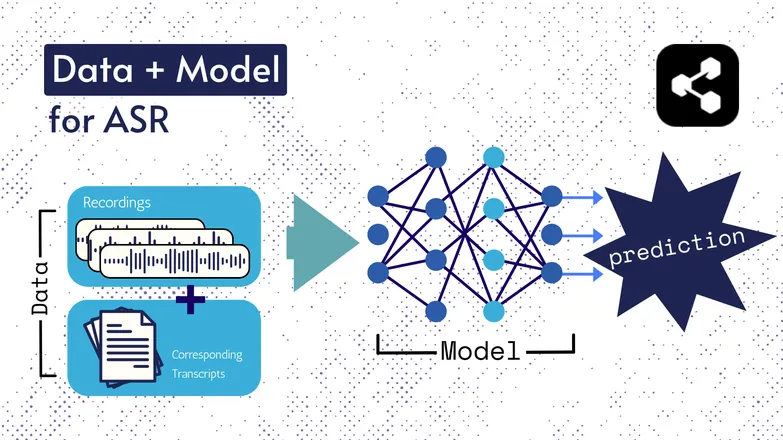
يشبه الأمر كيف يمكنك فهم سلسلة من الكلمات، حتى لو لم تسمعها بهذا الترتيب من قبل، أو إذا نطقها شخص غريب.
مرة أخرى، تغيرت أنواع النماذج وتفاصيلها مع الوقت، وجميع التحسينات في السرعة والدقة اعتمدت على حجم ومواصفات مجموعات البيانات والنماذج.
ملاحظة سريعة: استخراج الميزات
تحدثت عن الميزات أو التمثيلات في مقالتي حول التحويل من النص إلى الكلام. يتم استخدامها في نماذج ASR القديمة والحديثة.
استخراج الميزات — تحويل الكلام إلى ميزات — هو الخطوة الأولى في معظم عمليات ASR.
ببساطة، هذه الميزات، وغالبًا ما تكون مخططات طيفية، هي نتيجة عملية حسابية رياضية تُجرى على الكلام، وتحول الكلام إلى صيغة تبرز التشابهات عبر الجملة، وتقلل من الفروق بين المتحدثين.
أي أن الجملة نفسها إذا نطقها متحدثان مختلفان سيكون لديهما مخططات طيفية متشابهة، بغض النظر عن اختلاف أصواتهم.
أشير إلى ذلك لأوضح أنني سأتحدث عن نماذج "تتنبأ بالنصوص من الكلام". هذا ليس دقيقًا من الناحية التقنية؛ النماذج تتنبأ من الميزات. لكن يمكنك اعتبار استخراج الميزات جزءًا من النموذج.
ASR المبكر: HMM-GMM
نماذج ماركوف المخفية (HMMs) ونماذج المزيج الغاوسي (GMMs) هي نماذج تنبؤية سبقت الشبكات العصبية العميقة.
هيمنت HMMs على ASR حتى وقت قريب.
عند إعطاء ملف صوتي، تتنبأ HMM بمدة الفونيم، بينما تتنبأ GMM بالفونيم نفسه.
يبدو ذلك معكوسًا، وهو كذلك نوعًا ما، مثل:
- HMM: "أول 0.2 ثانية هي فونيم."
- GMM: "ذلك الفونيم هو G، كما في Gary."
تحويل مقطع صوتي إلى نص كان يتطلب بعض المكونات الإضافية، وهي:
- قاموس النطق: قائمة شاملة بالكلمات في المفردات مع نطقها المقابل.
- نموذج لغوي: مجموعات الكلمات في المفردات واحتمالية تكرارها معًا.
لذا حتى إذا توقعت GMM صوت /f/ بدلاً من /s/، يعرف النموذج اللغوي أنه من المرجح أن المتحدث قال "a penny for your thoughts" وليس foughts.
كان لدينا كل هذه الأجزاء لأنه، بصراحة، لم يكن أي جزء من هذه العملية جيدًا بشكل استثنائي.
كانت HMM تخطئ في التوافق الزمني، وكانت GMM تخلط بين الأصوات المتشابهة: /s/ و/f/، /p/ و/t/، ولا داعي للحديث عن حروف العلة.
ثم يأتي النموذج اللغوي ليصحح الفوضى الناتجة عن الفونيمات غير المفهومة إلى شيء أقرب للغة.
ASR الشامل باستخدام التعلم العميق
تم دمج العديد من أجزاء خط أنابيب ASR منذ ذلك الحين.
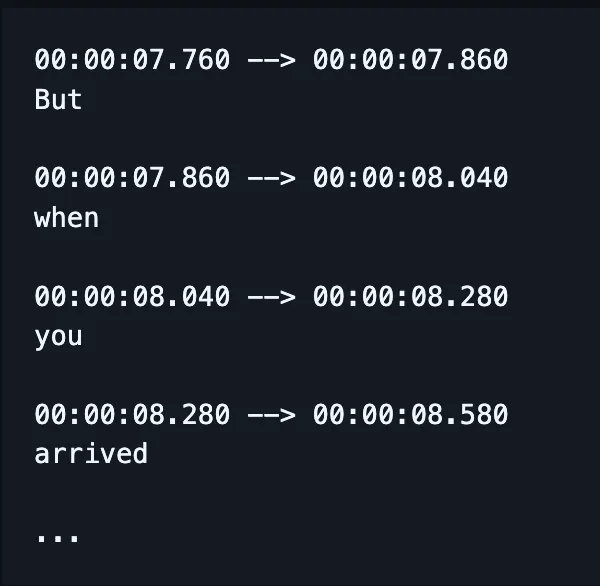
بدلاً من تدريب نماذج منفصلة للتعامل مع التهجئة والتوافق والنطق، يأخذ نموذج واحد الكلام ويُنتج كلمات مكتوبة بشكل صحيح غالبًا، وكذلك الطوابع الزمنية في الوقت الحاضر.
(مع ذلك، غالبًا ما يتم تصحيح أو "إعادة تقييم" هذا الناتج باستخدام نموذج لغوي إضافي.)
هذا لا يعني أن العوامل المختلفة — مثل التوافق والتهجئة — لا تحظى باهتمام خاص. لا تزال هناك الكثير من الأبحاث التي تركز على معالجة مشكلات محددة للغاية.
أي أن الباحثين يبتكرون طرقًا لتعديل بنية النموذج لمعالجة عوامل معينة في أدائه، مثل:
- مُفسر RNN-Transducer مشروط بالمخرجات السابقة لتحسين التهجئة.
- استخدام الطبقات الالتفافية لتقليل المخرجات الفارغة، مما يحسن التوافق.
أعلم أن هذا يبدو معقدًا. فقط أستبق سؤال مديري: "هل يمكنك إعطاء مثال مبسط؟"
الإجابة هي لا.
لا أستطيع.
كيف يتم قياس الأداء في ASR؟
عندما يكون أداء ASR سيئًا، ستلاحظ ذلك فورًا.
رأيت كلمة caramelization تُنسخ إلى communist Asians. وCrispiness إلى Chris p —، وهكذا.
المقياس الذي نستخدمه لقياس الأخطاء رياضيًا هو معدل خطأ الكلمات (WER). الصيغة لمعدل الخطأ هي:
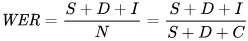
حيث:
- S هو عدد الاستبدالات (الكلمات التي تم تغييرها في النص المتوقع لتطابق النص المرجعي)
- D هو عدد الحذف (الكلمات المفقودة من الناتج مقارنة بالنص المرجعي)
- I هو عدد الإدراجات (الكلمات الإضافية في الناتج مقارنة بالنص المرجعي)
- N هو إجمالي عدد الكلمات في النص المرجعي
لنفترض أن النص المرجعي هو "the cat sat."
- إذا أعطى النموذج "the cat sank"، فهذا استبدال.
- إذا أعطى النموذج "cat sat"، فهذا حذف.
- إذا أعطى "the cat has sat"، فهذا إدراج.
ما هي تطبيقات ASR؟
ASR أداة مفيدة.
كما ساعدنا على تحسين جودة حياتنا من خلال تعزيز السلامة، وتسهيل الوصول، وزيادة الكفاءة في قطاعات حيوية.
الرعاية الصحية
عندما أخبر الأطباء أنني أبحث في مجال التعرف على الكلام، يقولون "آه، مثل Dragon."
قبل أن يكون لدينا الذكاء الاصطناعي التوليدي في الرعاية الصحية، كان الأطباء يدونون الملاحظات شفهياً بسرعة 30 كلمة في الدقيقة وبمفردات محدودة.
لقد حققت تقنية التعرف التلقائي على الكلام نجاحاً كبيراً في الحد من الإرهاق المنتشر بين الأطباء.
يوازن الأطباء بين جبال من الأعمال الورقية وضرورة رعاية مرضاهم. منذ عام 2018، كان الباحثون يحثون على استخدام النسخ الرقمي في الاستشارات لتحسين قدرة الأطباء على تقديم الرعاية.
وذلك لأن توثيق الاستشارات بأثر رجعي لا يقلل فقط من الوقت الذي يقضيه الطبيب مع المرضى، بل يكون أيضاً أقل دقة بكثير من تلخيصات النسخ الفعلية للاستشارات.
المنازل الذكية
لدي نكتة أقولها دائماً.
عندما أرغب في إطفاء الأنوار ولا أشعر بالنهوض، أصفق مرتين بسرعة — كما لو كان لدي جهاز تصفيق.
شريكتي لا تضحك أبداً.
تبدو المنازل الذكية التي تعمل بالصوت مستقبلية وفاخرة بشكل محرج في نفس الوقت. أو هكذا يبدو الأمر.
صحيح أنها مريحة، لكنها في كثير من الحالات تتيح القيام بأشياء لا يمكن تحقيقها بطرق أخرى.
مثال رائع هو استهلاك الطاقة: إجراء تعديلات بسيطة على الإضاءة أو منظم الحرارة سيكون غير عملي طوال اليوم إذا كان عليك النهوض والتلاعب بالمقبض.
تفعيل الصوت يعني أن هذه التعديلات البسيطة ليست أسهل فقط، بل إنه يفهم أيضاً تفاصيل الكلام البشري.
على سبيل المثال، تقول "هل يمكنك جعل الجو أبرد قليلاً؟" يستخدم المساعد معالجة اللغة الطبيعية لترجمة طلبك إلى تغيير في درجة الحرارة، مع الأخذ في الاعتبار مجموعة من البيانات الأخرى: درجة الحرارة الحالية، توقعات الطقس، بيانات استخدام منظم الحرارة من مستخدمين آخرين، وغيرها.
أنت تقوم بالجزء البشري، ودع الأمور التقنية للكمبيوتر.
وأرى أن هذا أسهل بكثير من أن تحاول تخمين عدد الدرجات التي يجب أن تخفضها بناءً على شعورك.
وهي أكثر كفاءة في استهلاك الطاقة أيضًا: هناك تقارير عن عائلات قللت استهلاك الطاقة بنسبة 80٪ باستخدام الإضاءة الذكية التي تعمل بالصوت، كمثال واحد فقط.
دعم العملاء
تحدثنا عن هذا في الرعاية الصحية، لكن النسخ والتلخيص أكثر فعالية بكثير من تلخيص الأشخاص للتفاعلات بأثر رجعي.
مرة أخرى، يوفر الوقت ويكون أكثر دقة. ما نتعلمه مراراً وتكراراً هو أن الأتمتة توفر وقتاً للناس ليؤدوا أعمالهم بشكل أفضل.
ولا يظهر ذلك بشكل أوضح من دعم العملاء، حيث أن دعم العملاء المعزز بتقنية التعرف التلقائي على الكلام (ASR) يحقق معدل حل للمكالمة الأولى أعلى بنسبة 25٪.
يساعد النسخ والتلخيص في أتمتة عملية إيجاد حل بناءً على مشاعر العميل واستفساره.
المساعدون داخل السيارات
نحن نستفيد هنا من المساعدين المنزليين، لكن الأمر يستحق الذكر.
التعرف على الصوت يقلل من العبء الذهني والتشتت البصري للسائقين.
ومع أن التشتت يسبب ما يصل إلى 30٪ من الحوادث، فإن تطبيق هذه التقنية يعد خيارًا بديهيًا لتعزيز السلامة.
علم أمراض النطق
يُستخدم التعرف التلقائي على الكلام منذ فترة طويلة كـ أداة لتقييم وعلاج اضطرابات النطق.
من المفيد أن نتذكر أن الآلات لا تقوم فقط بأتمتة المهام، بل تنجز أشياء لا يستطيع البشر القيام بها.
يمكن لتقنية التعرف على الكلام اكتشاف الفروق الدقيقة في النطق التي يصعب على الأذن البشرية ملاحظتها، والتقاط تفاصيل في الكلام المتأثر قد تمر دون انتباه.
مستقبل التعرف التلقائي على الكلام
لقد أصبح تحويل الكلام إلى نص جيداً بما فيه الكفاية لدرجة أننا لم نعد نفكر فيه.
لكن في الكواليس، يعمل الباحثون بجد لجعله أكثر قوة وسهولة في الوصول — وأقل وضوحاً للمستخدم.
اخترت بعض الاتجاهات المثيرة التي تستفيد من تطورات التعرف التلقائي على الكلام، وأضفت بعضاً من آرائي الشخصية.
التعرف على الكلام على الجهاز
معظم حلول التعرف التلقائي على الكلام تعمل في السحابة. أنا متأكد أنك سمعت ذلك من قبل. هذا يعني أن النموذج يعمل على جهاز كمبيوتر بعيد، في مكان آخر.
يفعلون ذلك لأن معالج هاتفك الصغير لا يستطيع بالضرورة تشغيل نموذجهم الضخم، أو سيستغرق الأمر وقتاً طويلاً لنسخ أي شيء.
بدلاً من ذلك، يتم إرسال صوتك عبر الإنترنت إلى خادم بعيد يعمل عليه وحدة معالجة رسومات ضخمة لا يمكن حملها في جيبك. تقوم وحدة معالجة الرسومات بتشغيل نموذج التعرف التلقائي على الكلام، ثم تعيد النص إلى جهازك.
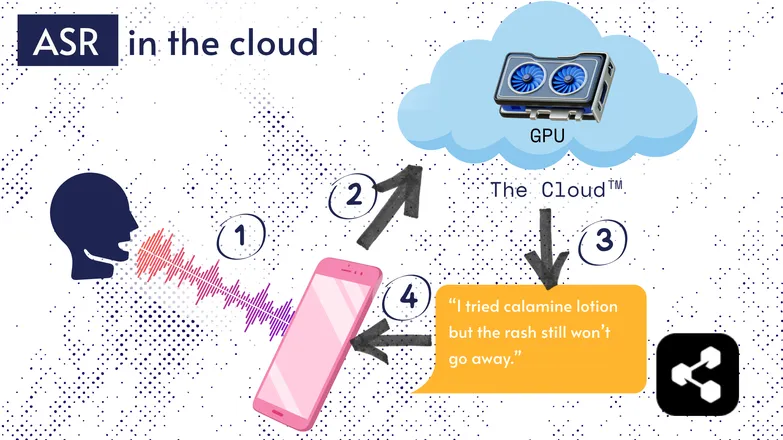
لأسباب تتعلق بكفاءة الطاقة والأمان (ليس الجميع يرغب في أن تظل بياناته الشخصية تتنقل عبر الإنترنت)، تم تكريس الكثير من الأبحاث لجعل النماذج صغيرة بما يكفي لتعمل مباشرة على جهازك، سواء كان هاتفاً أو كمبيوتراً أو متصفحاً.
كتبت بنفسي أطروحة حول تقليل حجم نماذج التعرف التلقائي على الكلام (quantizing ASR) لتعمل على الجهاز. Picovoice هي شركة كندية تطور ذكاءً صوتياً منخفض التأخير على الأجهزة، ويبدون رائعين.
يتيح التعرف التلقائي على الكلام على الجهاز إمكانية النسخ بتكلفة أقل، مع إمكانية خدمة المجتمعات ذات الدخل المنخفض.
واجهة المستخدم المعتمدة على النص المنقول أولاً
الفجوة بين الصوت والنصوص تتقلص. ماذا يعني ذلك؟
محررو الفيديو مثل Premiere Pro وDescript يتيحون لك التنقل في تسجيلاتك عبر النص: انقر على كلمة وستنتقل إلى توقيتها الزمني.
هل اضطررت لإعادة التسجيل عدة مرات؟ اختر المقطع المفضل لديك وامسح البقية، كما في محرر النصوص. سيقوم النظام تلقائيًا بقص الفيديو نيابة عنك.
من المزعج جداً القيام بهذا النوع من التحرير باستخدام شكل الموجة فقط، لكنه سهل جداً عندما يكون لديك محررات تعتمد على النص.
وبالمثل، تقوم خدمات المراسلة مثل WhatsApp بنسخ ملاحظاتك الصوتية وتتيح لك التنقل فيها عبر النص. مرر إصبعك فوق كلمة، وستنتقل إلى ذلك الجزء من التسجيل.

قصة طريفة: لقد أنشأت شيئًا مشابهًا لهذا قبل أسبوع تقريبًا من إعلان Apple عن ميزة مماثلة.
تُظهر هذه الأمثلة كيف أن التقنيات المعقدة خلف الكواليس تجلب البساطة وسهولة الاستخدام لتطبيقات المستخدم النهائي.
العدالة والشمول واللغات منخفضة الموارد
المعركة لم تُحسم بعد.
يعمل التعرف التلقائي على الكلام بشكل ممتاز في الإنجليزية وغيرها من اللغات الشائعة ذات الموارد الجيدة. لكن هذا ليس الحال دائماً مع اللغات منخفضة الموارد.
هناك فجوة في اللهجات الأقلية، والكلام المتأثر، وقضايا أخرى تتعلق بـ العدالة في تقنيات الصوت.
عذراً لإفساد الأجواء الإيجابية. هذا القسم يسمى "مستقبل" التعرف التلقائي على الكلام. وأختار أن أتطلع إلى مستقبل يمكننا أن نفخر به.
إذا كنا سنحقق تقدماً، يجب أن نقوم بذلك معاً، وإلا سنخاطر بزيادة عدم المساواة في المجتمع.
ابدأ باستخدام التعرف التلقائي على الكلام اليوم
بغض النظر عن مجال عملك، استخدام تقنية ASR أمر بديهي — لكنك ربما تتساءل عن كيفية البدء. كيف يمكنك تنفيذ ASR؟ كيف تنقل هذه البيانات إلى أدوات أخرى؟
يأتي Botpress ببطاقات نسخ سهلة الاستخدام. يمكن دمجها في سير عمل بالسحب والإفلات، مع إمكانية تعزيزها بعشرات التكاملات عبر التطبيقات وقنوات التواصل.
ابدأ البناء اليوم. إنه مجاني.
الأسئلة الشائعة
ما مدى دقة تقنية ASR الحديثة مع اللهجات المختلفة والبيئات المليئة بالضوضاء؟
أنظمة ASR الحديثة دقيقة للغاية مع اللهجات الشائعة في اللغات الرئيسية، حيث تحقق معدلات خطأ في الكلمات (WER) أقل من 10٪ في الظروف المثالية، لكن الدقة تنخفض بشكل ملحوظ مع اللهجات الثقيلة أو الضوضاء الخلفية الكبيرة. تقوم شركات مثل Google وMicrosoft بتدريب النماذج على بيانات صوتية متنوعة، لكن النسخ المثالي في البيئات المزعجة لا يزال يمثل تحديًا.
هل يمكن الاعتماد على ASR في نسخ المصطلحات المتخصصة أو المصطلحات الخاصة بالصناعات المختلفة؟
تقنية ASR أقل موثوقية بشكل افتراضي مع المصطلحات المتخصصة أو الكلمات الخاصة بالصناعات، لأن بيانات التدريب غالبًا ما تركز على الكلام العام؛ فقد يتم نسخ الكلمات غير المألوفة بشكل خاطئ أو تجاهلها. ومع ذلك، تتيح الحلول المؤسسية إضافة قوائم مفردات مخصصة ونماذج لغوية متخصصة وقواميس نطق لتحسين التعرف على المصطلحات التقنية في مجالات مثل الرعاية الصحية أو القانون أو الهندسة.
ما الفرق بين أدوات التعرف التلقائي على الكلام المجانية والحلول المؤسسية؟
يكمن الفرق بين أدوات التعرف التلقائي على الكلام المجانية والحلول المؤسسية في الدقة، وقابلية التوسع، والتخصيص، وضوابط الخصوصية: غالباً ما تكون الأدوات المجانية أقل دقة، وتدعم لغات محدودة، ولها حدود استخدام، بينما توفر الحلول المؤسسية معدلات خطأ أقل، وتخصيصاً خاصاً بالمجال، وتكاملات، واتفاقيات مستوى الخدمة (SLA)، وميزات أمان قوية للتعامل مع البيانات الحساسة.
كيف تحمي تقنية ASR خصوصية المستخدم والمعلومات الحساسة أثناء النسخ؟
تحمي تقنية التعرف التلقائي على الكلام خصوصية المستخدم من خلال تشفير البيانات أثناء نقلها، كما توفر خيارات مثل تشغيل النماذج على الجهاز نفسه لتجنب إرسال بيانات الصوت إلى خوادم خارجية. العديد من مزودي الخدمات للمؤسسات يلتزمون أيضاً بلوائح الخصوصية مثل اللائحة العامة لحماية البيانات (GDPR) أو قانون نقل وحماية معلومات التأمين الصحي (HIPAA)، ويمكنهم إخفاء هوية البيانات لحماية المعلومات الحساسة.
ما مدى تكلفة خدمات التعرف التلقائي على الكلام السحابية مقارنةً بالحلول التي تعمل على الجهاز؟
عادةً ما تفرض خدمات ASR السحابية رسومًا لكل دقيقة صوتية أو حسب مستويات الاستخدام، وتتراوح التكاليف بين 0.03 و1.00 دولار أمريكي أو أكثر للدقيقة حسب الدقة والميزات، بينما تتطلب الحلول المحلية تكاليف تطوير أولية ورسوم ترخيص.



