



- ASR chuyển đổi lời nói thành văn bản bằng học máy, cho phép ra lệnh bằng giọng nói và chuyển đổi trực tiếp theo thời gian thực.
- Các hệ thống ASR hiện đại đã chuyển từ các mô hình âm vị riêng biệt (HMM-GMM) sang các mô hình học sâu dự đoán cả từ.
- Hiệu suất ASR được đo bằng Tỷ lệ lỗi từ (WER), với lỗi đến từ việc thay thế, xóa hoặc chèn; WER càng thấp thì chất lượng chuyển đổi càng tốt.
- Tương lai của ASR tập trung vào xử lý trực tiếp trên thiết bị để bảo vệ quyền riêng tư và hỗ trợ các ngôn ngữ ít tài nguyên.
Lần cuối bạn xem thứ gì đó mà không có phụ đề là khi nào?
Trước đây phụ đề là tùy chọn, nhưng giờ chúng xuất hiện khắp các video ngắn dù bạn có muốn hay không. Phụ đề đã trở thành một phần không thể thiếu đến mức bạn quên mất sự hiện diện của chúng.
Nhận dạng giọng nói tự động (ASR) — khả năng tự động chuyển đổi lời nói thành văn bản một cách nhanh chóng và chính xác — là công nghệ thúc đẩy sự thay đổi này.
Khi nghĩ về một tác nhân AI giọng nói, chúng ta thường nghĩ về cách chọn từ, cách truyền đạt và giọng nói của nó.
Nhưng dễ quên rằng sự mượt mà trong tương tác phụ thuộc vào việc bot hiểu được chúng ta. Và để đạt được điều này — bot hiểu bạn qua những tiếng “ừm”, “à” trong môi trường ồn ào — không hề đơn giản.
Hôm nay, chúng ta sẽ nói về công nghệ đứng sau những dòng phụ đề đó: nhận dạng giọng nói tự động (ASR).
Cho phép tôi giới thiệu: Tôi có bằng thạc sĩ về công nghệ giọng nói, và lúc rảnh tôi thích cập nhật những điều mới về ASR, thậm chí còn tự xây dựng vài thứ.
Tôi sẽ giải thích cho bạn những điều cơ bản về ASR, khám phá công nghệ bên trong, và dự đoán xem công nghệ này sẽ phát triển ra sao.
ASR là gì?
Nhận dạng giọng nói tự động (ASR), hay chuyển giọng nói thành văn bản (STT), là quá trình chuyển đổi lời nói thành văn bản bằng công nghệ học máy.
Các công nghệ liên quan đến giọng nói thường tích hợp ASR ở mức độ nào đó; có thể dùng cho phụ đề video, ghi lại cuộc trò chuyện hỗ trợ khách hàng để phân tích, hoặc là một phần của trợ lý giọng nói, chỉ kể vài ví dụ.
Thuật toán chuyển giọng nói thành văn bản
Các công nghệ nền tảng đã thay đổi theo thời gian, nhưng mọi phiên bản đều gồm hai thành phần dưới một hình thức nào đó: dữ liệu và mô hình.
Trong ASR, dữ liệu là giọng nói đã được gán nhãn – các tệp âm thanh và bản chép lời tương ứng.
Mô hình là thuật toán dùng để dự đoán bản chép lời từ âm thanh. Dữ liệu đã gán nhãn được dùng để huấn luyện mô hình, giúp nó có thể tổng quát hóa với các ví dụ giọng nói chưa từng gặp.
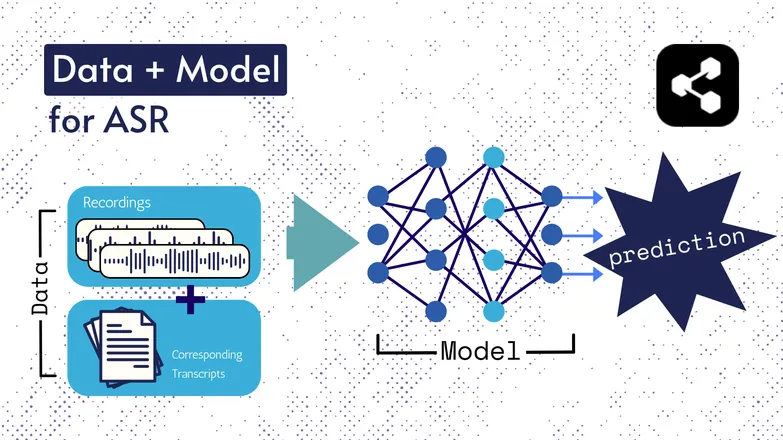
Nó khá giống cách bạn có thể hiểu một chuỗi từ, dù chưa từng nghe chúng theo thứ tự đó, hoặc do người lạ nói.
Một lần nữa, các loại mô hình và chi tiết của chúng đã thay đổi theo thời gian, và mọi tiến bộ về tốc độ, độ chính xác đều dựa vào kích thước và đặc điểm của bộ dữ liệu và mô hình.
Lưu ý nhanh: Trích xuất đặc trưng
Tôi đã nói về đặc trưng, hay biểu diễn trong bài viết về chuyển văn bản thành giọng nói. Chúng được sử dụng trong các mô hình ASR cả trước đây lẫn hiện tại.
Trích xuất đặc trưng — chuyển giọng nói thành các đặc trưng — là bước đầu tiên trong hầu hết các quy trình ASR.
Nói ngắn gọn, các đặc trưng này, thường là phổ tần, là kết quả của phép tính toán học trên âm thanh, và chuyển giọng nói thành định dạng làm nổi bật điểm giống nhau trong một câu nói, giảm thiểu sự khác biệt giữa các người nói.
Tức là, cùng một câu nói do 2 người khác nhau nói sẽ có phổ tần tương tự, dù giọng của họ khác nhau.
Tôi nhấn mạnh điều này để bạn biết rằng tôi sẽ nói về việc mô hình “dự đoán bản chép lời từ giọng nói”. Thực ra không hoàn toàn đúng; mô hình dự đoán từ đặc trưng. Nhưng bạn có thể xem phần trích xuất đặc trưng là một phần của mô hình.
ASR thời kỳ đầu: HMM-GMM
Mô hình markov ẩn (HMMs) và mô hình hỗn hợp Gaussian (GMMs) là các mô hình dự đoán trước khi mạng nơ-ron sâu xuất hiện.
HMM từng thống trị ASR cho đến gần đây.
Với một tệp âm thanh, HMM sẽ dự đoán thời lượng của một âm vị, còn GMM sẽ dự đoán đó là âm vị nào.
Nghe có vẻ ngược, và thực ra cũng hơi như vậy, ví dụ:
- HMM: “0,2 giây đầu là một âm vị.”
- GMM: “Âm vị đó là G, như trong Gary.”
Để chuyển một đoạn âm thanh thành văn bản cần thêm vài thành phần nữa, cụ thể là:
- Từ điển phát âm: danh sách đầy đủ các từ trong từ vựng, kèm phát âm tương ứng.
- Mô hình ngôn ngữ: Các tổ hợp từ trong từ vựng, cùng xác suất xuất hiện cùng nhau.
Vì vậy, dù GMM dự đoán /f/ thay vì /s/, mô hình ngôn ngữ biết rằng khả năng cao người nói đang nói “a penny for your thoughts”, chứ không phải foughts.
Chúng ta có tất cả các phần này vì, nói thẳng ra, không phần nào trong quy trình này thực sự tốt.
HMM dự đoán sai căn chỉnh, GMM nhầm lẫn các âm giống nhau: /s/ và /f/, /p/ và /t/, và còn chưa kể đến nguyên âm.
Sau đó mô hình ngôn ngữ sẽ sửa lại chuỗi âm vị rời rạc thành thứ gì đó giống ngôn ngữ hơn.
ASR đầu-cuối với học sâu
Nhiều thành phần trong quy trình ASR đã được hợp nhất lại.
Thay vì huấn luyện các mô hình riêng biệt cho chính tả, căn chỉnh và phát âm, một mô hình duy nhất nhận đầu vào là giọng nói và xuất ra (hy vọng là) từ đúng chính tả, và hiện nay còn có cả dấu thời gian.
(Dù vậy, các phiên bản triển khai thường điều chỉnh, hoặc “chấm lại” kết quả này bằng một mô hình ngôn ngữ bổ sung.)
Điều này không có nghĩa là các yếu tố khác nhau — như căn chỉnh và chính tả — không được chú ý riêng. Vẫn còn rất nhiều nghiên cứu tập trung vào việc khắc phục các vấn đề rất cụ thể.
Tức là, các nhà nghiên cứu nghĩ ra cách thay đổi kiến trúc mô hình để cải thiện các yếu tố nhất định về hiệu suất, ví dụ:
- Bộ giải mã RNN-Transducer dựa trên đầu ra trước đó để cải thiện chính tả.
- Giảm mẫu bằng tích chập để hạn chế kết quả trống, giúp căn chỉnh tốt hơn.
Tôi biết điều này nghe vô lý. Tôi chỉ đang chuẩn bị trước khi sếp hỏi “có ví dụ dễ hiểu không?”
Câu trả lời là không.
Tôi không thể.
Hiệu suất ASR được đo như thế nào?
Khi ASR hoạt động kém, bạn sẽ nhận ra ngay.
Tôi từng thấy caramelization bị chuyển thành communist Asians. Crispiness thành Chris p — bạn hiểu ý rồi đấy.
Chỉ số dùng để phản ánh lỗi một cách toán học là tỷ lệ lỗi từ (WER). Công thức WER là:
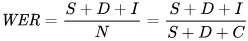
Trong đó:
- S là số thay thế (từ bị thay đổi trong văn bản dự đoán để khớp với văn bản tham chiếu)
- D là số xóa (từ bị thiếu trong kết quả so với văn bản tham chiếu)
- I là số chèn (từ dư trong kết quả so với văn bản tham chiếu)
- N là tổng số từ trong văn bản tham chiếu
Ví dụ, văn bản tham chiếu là “the cat sat.”
- Nếu mô hình xuất ra “the cat sank”, đó là một lần thay thế.
- Nếu mô hình xuất ra “cat sat”, đó là một lần xóa.
- Nếu kết quả là “the cat has sat”, đó là một lần chèn.
ASR được ứng dụng vào đâu?
ASR là một công cụ hữu ích.
Nó cũng giúp nâng cao chất lượng cuộc sống nhờ tăng an toàn, khả năng tiếp cận và hiệu quả trong các ngành quan trọng.
Y tế
Khi tôi nói với các bác sĩ rằng tôi nghiên cứu nhận dạng giọng nói, họ thường nói “à, giống như Dragon.”
Trước khi có AI tạo sinh trong y tế, các bác sĩ ghi chú bằng lời nói với tốc độ 30 từ/phút và vốn từ hạn chế.
ASR đã giúp giảm đáng kể tình trạng kiệt sức phổ biến ở các bác sĩ.
Các bác sĩ phải cân bằng giữa núi giấy tờ và việc chăm sóc bệnh nhân. Ngay từ năm 2018, các nhà nghiên cứu đã kêu gọi sử dụng chuyển đổi văn bản số trong các buổi khám để giúp bác sĩ nâng cao chất lượng chăm sóc.
Bởi vì việc ghi lại nội dung buổi khám sau đó không chỉ làm giảm thời gian tiếp xúc trực tiếp với bệnh nhân mà còn kém chính xác hơn nhiều so với việc tóm tắt từ bản ghi thực tế.
Nhà thông minh
Tôi có một trò đùa nhỏ.
Khi tôi muốn tắt đèn mà không muốn đứng dậy, tôi vỗ tay hai lần liên tiếp — như thể tôi có một thiết bị cảm biến vỗ tay.
Bạn đời tôi chẳng bao giờ cười.
Nhà thông minh điều khiển bằng giọng nói vừa mang cảm giác tương lai vừa hơi xa xỉ. Hoặc ít nhất là như vậy.
Đúng là tiện lợi, nhưng trong nhiều trường hợp, chúng còn giúp thực hiện những việc mà bình thường không thể làm được.
Ví dụ điển hình là tiết kiệm năng lượng: việc điều chỉnh nhỏ về đèn hay nhiệt độ sẽ rất bất tiện nếu bạn phải đứng dậy và vặn núm điều chỉnh suốt cả ngày.
Kích hoạt bằng giọng nói giúp những điều chỉnh nhỏ này dễ thực hiện hơn, đồng thời hiểu được sắc thái trong lời nói của con người.
Ví dụ, bạn nói “có thể làm mát hơn một chút không?” Trợ lý sẽ dùng xử lý ngôn ngữ tự nhiên để chuyển yêu cầu của bạn thành thay đổi nhiệt độ, đồng thời xem xét nhiều dữ liệu khác: nhiệt độ hiện tại, dự báo thời tiết, dữ liệu sử dụng nhiệt độ của người dùng khác, v.v.
Bạn làm phần của con người, còn máy tính lo phần của nó.
Tôi cho rằng như vậy dễ hơn nhiều so với việc bạn phải đoán nên giảm nhiệt bao nhiêu độ dựa trên cảm giác.
Và nó còn tiết kiệm năng lượng hơn: có những báo cáo cho thấy các gia đình giảm tiêu thụ điện năng tới 80% nhờ sử dụng hệ thống chiếu sáng thông minh điều khiển bằng giọng nói, chỉ là một ví dụ.
Hỗ trợ Khách hàng
Chúng ta đã nói về điều này trong lĩnh vực y tế, nhưng việc ghi âm và tóm tắt hiệu quả hơn nhiều so với việc mọi người tự kể lại các tương tác sau đó.
Một lần nữa, nó tiết kiệm thời gian và chính xác hơn. Điều chúng ta rút ra là tự động hóa giúp mọi người có thêm thời gian để làm việc tốt hơn.
Và điều này càng đúng hơn trong lĩnh vực hỗ trợ khách hàng, nơi dịch vụ hỗ trợ có ASR đạt tỷ lệ giải quyết ngay lần gọi đầu tiên cao hơn 25%.
Chuyển đổi và tóm tắt giúp tự động hóa quá trình tìm giải pháp dựa trên cảm xúc và câu hỏi của khách hàng.
Trợ lý trên xe hơi
Chúng ta đang tận dụng ý tưởng từ trợ lý trong nhà, nhưng lĩnh vực này cũng rất đáng chú ý.
Nhận diện giọng nói giúp giảm tải nhận thức và hạn chế xao nhãng cho tài xế.
Và vì các yếu tố gây xao nhãng chiếm tới 30% số vụ va chạm, việc áp dụng công nghệ này là lựa chọn an toàn hiển nhiên.
Âm ngữ trị liệu
ASR từ lâu đã được sử dụng như một công cụ đánh giá và điều trị các rối loạn ngôn ngữ.
Cần nhớ rằng máy móc không chỉ tự động hóa công việc, mà còn làm được những điều con người không thể.
Nhận diện giọng nói có thể phát hiện những khác biệt rất nhỏ trong lời nói mà tai người gần như không nhận ra, giúp nhận diện chi tiết các vấn đề mà bình thường dễ bị bỏ qua.
Tương lai của ASR
STT đã phát triển đến mức chúng ta không còn để ý đến nó nữa.
Nhưng phía sau, các nhà nghiên cứu vẫn không ngừng cải tiến để công nghệ này mạnh mẽ và dễ tiếp cận hơn — đồng thời ít gây chú ý hơn.
Tôi chọn ra một số xu hướng thú vị tận dụng sự phát triển của ASR, và thêm vào một vài ý kiến cá nhân.
Nhận diện giọng nói trên thiết bị
Hầu hết các giải pháp ASR đều chạy trên đám mây. Chắc bạn đã nghe rồi. Nghĩa là mô hình chạy trên máy tính từ xa, ở một nơi khác.
Họ làm vậy vì bộ xử lý nhỏ trên điện thoại của bạn không đủ mạnh để chạy mô hình lớn, hoặc sẽ mất rất nhiều thời gian để chuyển đổi bất cứ thứ gì.
Thay vào đó, âm thanh của bạn được gửi qua internet đến máy chủ từ xa có GPU mạnh mẽ mà bạn không thể mang theo trong túi. GPU này chạy mô hình ASR và trả lại bản chuyển đổi cho thiết bị của bạn.
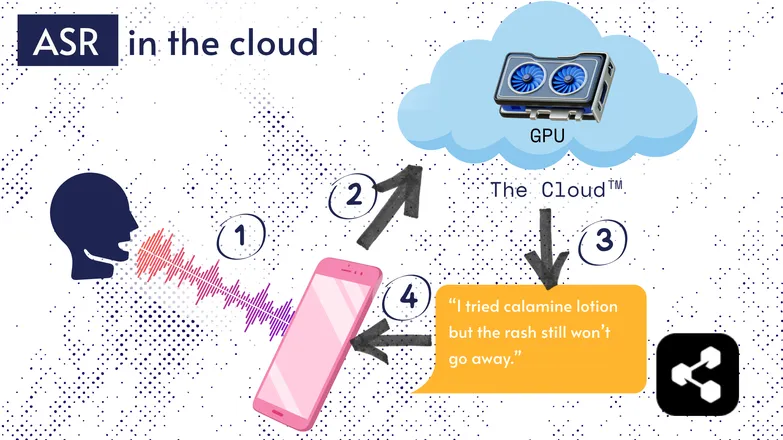
Vì lý do tiết kiệm năng lượng và bảo mật (không phải ai cũng muốn dữ liệu cá nhân của mình trôi nổi trên mạng), rất nhiều nghiên cứu đã tập trung vào việc thu nhỏ mô hình để có thể chạy trực tiếp trên thiết bị, dù là điện thoại, máy tính hay trình duyệt.
Chính tôi đã viết luận văn về lượng tử hóa mô hình ASR để chạy trên thiết bị. Picovoice là một công ty Canada phát triển AI giọng nói trên thiết bị với độ trễ thấp, và họ có vẻ rất thú vị.
ASR trên thiết bị giúp chuyển đổi văn bản với chi phí thấp hơn, mở ra cơ hội cho các cộng đồng thu nhập thấp.
Giao diện ưu tiên bản ghi
Khoảng cách giữa âm thanh và bản chuyển đổi ngày càng thu hẹp. Điều đó có nghĩa gì?
Các phần mềm chỉnh sửa video như Premiere Pro và Descript cho phép bạn điều hướng bản ghi qua bản chuyển đổi: nhấp vào một từ sẽ đưa bạn đến đúng thời điểm đó.
Phải quay lại vài lần? Hãy chọn bản bạn thích và xóa những bản còn lại, giống như chỉnh sửa văn bản. Hệ thống sẽ tự động cắt gọn video cho bạn.
Việc chỉnh sửa chỉ dựa vào sóng âm rất khó chịu, nhưng lại cực kỳ dễ dàng khi dùng trình chỉnh sửa dựa trên bản chuyển đổi.
Tương tự, các dịch vụ nhắn tin như WhatsApp đang chuyển đổi ghi chú thoại của bạn thành văn bản và cho phép bạn tua nhanh qua đoạn ghi âm bằng cách lướt qua văn bản. Trượt ngón tay qua một từ, bạn sẽ được đưa đến đúng đoạn ghi đó.

Chuyện vui: Tôi thực sự đã xây dựng một thứ tương tự như thế này khoảng một tuần trước khi Apple công bố tính năng tương tự.
Những ví dụ này cho thấy các công nghệ phức tạp bên trong lại mang đến sự đơn giản và trực quan cho người dùng cuối.
Bình đẳng, hòa nhập và ngôn ngữ ít tài nguyên
Cuộc chiến vẫn chưa kết thúc.
ASR hoạt động rất tốt với tiếng Anh và các ngôn ngữ phổ biến, nhiều tài nguyên khác. Nhưng điều này không đúng với các ngôn ngữ ít tài nguyên.
Vẫn còn khoảng cách với các nhóm thiểu số phương ngữ, người có rối loạn ngôn ngữ, và các vấn đề khác liên quan đến bình đẳng trong công nghệ giọng nói.
Xin lỗi vì làm giảm không khí tích cực. Phần này gọi là “tương lai” của ASR. Và tôi chọn hướng tới một tương lai mà chúng ta có thể tự hào.
Nếu muốn phát triển, chúng ta nên cùng nhau tiến lên, nếu không sẽ làm gia tăng bất bình đẳng xã hội.
Bắt đầu sử dụng ASR ngay hôm nay
Dù bạn kinh doanh lĩnh vực nào, sử dụng ASR là điều nên làm — chỉ là bạn có thể đang băn khoăn bắt đầu từ đâu. Làm sao để triển khai ASR? Làm sao để chuyển dữ liệu đó sang các công cụ khác?
Botpress cung cấp các thẻ chuyển đổi văn bản dễ sử dụng. Bạn có thể tích hợp chúng vào quy trình kéo-thả, kết hợp với hàng chục tích hợp trên các ứng dụng và kênh giao tiếp.
Bắt đầu xây dựng ngay hôm nay. Miễn phí.
Câu hỏi thường gặp
ASR hiện đại chính xác đến mức nào với các giọng nói khác nhau và trong môi trường ồn ào?
Các hệ thống ASR hiện đại rất chính xác với các giọng phổ biến ở những ngôn ngữ lớn, đạt tỷ lệ lỗi từ dưới 10% trong điều kiện lý tưởng, nhưng độ chính xác giảm rõ rệt với giọng nặng, phương ngữ hoặc nhiều tiếng ồn nền. Các nhà cung cấp như Google và Microsoft huấn luyện mô hình trên dữ liệu giọng nói đa dạng, nhưng việc chuyển âm hoàn hảo trong môi trường ồn ào vẫn là một thách thức.
ASR có đáng tin cậy khi chuyển âm các thuật ngữ chuyên ngành hoặc từ vựng đặc thù không?
ASR mặc định kém chính xác hơn với thuật ngữ chuyên ngành hoặc từ vựng đặc thù vì dữ liệu huấn luyện thường thiên về ngôn ngữ phổ thông; các từ lạ có thể bị nhận sai hoặc bỏ qua. Tuy nhiên, các giải pháp doanh nghiệp cho phép bổ sung từ vựng tùy chỉnh, mô hình ngôn ngữ theo lĩnh vực và từ điển phát âm để cải thiện khả năng nhận diện thuật ngữ kỹ thuật trong các lĩnh vực như y tế, pháp luật hoặc kỹ thuật.
Sự khác biệt giữa công cụ ASR miễn phí và giải pháp doanh nghiệp là gì?
Sự khác biệt giữa công cụ ASR miễn phí và giải pháp doanh nghiệp nằm ở độ chính xác, khả năng mở rộng, tùy chỉnh và kiểm soát quyền riêng tư: công cụ miễn phí thường có tỷ lệ lỗi cao hơn, hỗ trợ ngôn ngữ hạn chế và giới hạn sử dụng, trong khi giải pháp doanh nghiệp cung cấp WER thấp hơn, tùy chỉnh theo lĩnh vực, tích hợp, cam kết dịch vụ (SLA) và các tính năng bảo mật mạnh mẽ để xử lý dữ liệu nhạy cảm.
ASR bảo vệ quyền riêng tư và thông tin nhạy cảm của người dùng như thế nào trong quá trình chuyển âm?
ASR bảo vệ quyền riêng tư của người dùng bằng cách mã hóa dữ liệu trong quá trình truyền và cung cấp các tùy chọn như chạy mô hình trực tiếp trên thiết bị để tránh gửi dữ liệu giọng nói ra máy chủ bên ngoài. Nhiều nhà cung cấp cho doanh nghiệp cũng tuân thủ các quy định về bảo mật như GDPR hoặc HIPAA và có thể ẩn danh dữ liệu để bảo vệ thông tin nhạy cảm.
Dịch vụ ASR dựa trên đám mây có đắt hơn so với giải pháp trên thiết bị không?
Các dịch vụ ASR dựa trên nền tảng đám mây thường tính phí theo phút âm thanh hoặc theo các gói sử dụng, với chi phí từ $0,03–$1,00+ mỗi phút tùy vào độ chính xác và tính năng, trong khi các giải pháp trên thiết bị yêu cầu chi phí phát triển ban đầu và phí bản quyền.



