



- L’ASR transforme la parole en texte grâce à l’apprentissage automatique, permettant les commandes vocales et la transcription en temps réel.
- Les systèmes ASR modernes sont passés de modèles phonémiques séparés (HMM-GMM) à des modèles d’apprentissage profond qui prédisent des mots entiers.
- La performance de l’ASR se mesure par le taux d’erreur sur les mots (WER), les erreurs provenant de substitutions, suppressions ou insertions ; un WER plus bas = une meilleure qualité de transcription.
- L’avenir de l’ASR se concentre sur le traitement local pour la confidentialité et le support des langues peu dotées.
Quand avez-vous regardé quelque chose pour la dernière fois sans sous-titres ?
Avant, ils étaient optionnels, mais aujourd’hui ils défilent sur toutes les vidéos courtes, qu’on le veuille ou non. Les sous-titres sont tellement intégrés qu’on finit par les oublier.
La reconnaissance automatique de la parole (ASR) — la capacité à automatiser rapidement et précisément la conversion de la parole en texte — est la technologie qui rend cela possible.
Quand on pense à un agent vocal IA, on pense à son choix de mots, sa façon de s’exprimer et la voix qu’il utilise.
Mais il est facile d’oublier que la fluidité de nos échanges dépend de la capacité du bot à nous comprendre. Et arriver à ce point — que le bot vous comprenne malgré les « euh » et « hum » dans un environnement bruyant — n’a pas été une mince affaire.
Aujourd’hui, nous allons parler de la technologie derrière ces sous-titres : la reconnaissance automatique de la parole (ASR).
Je me présente : j’ai un master en technologies de la parole et, sur mon temps libre, j’aime me tenir au courant des nouveautés en ASR, et même créer des projets.
Je vais vous expliquer les bases de l’ASR, vous donner un aperçu de la technologie, et imaginer où elle pourrait aller ensuite.
Qu’est-ce que l’ASR ?
La reconnaissance automatique de la parole (ASR), ou speech-to-text (STT), est le processus qui consiste à convertir la parole en texte écrit grâce à des technologies d’apprentissage automatique.
Les technologies impliquant la parole intègrent souvent l’ASR d’une façon ou d’une autre : cela peut servir à sous-titrer des vidéos, à transcrire des conversations de support client pour analyse, ou à alimenter une interaction avec un assistant vocal, entre autres exemples.
Algorithmes de conversion parole-texte
Les technologies sous-jacentes ont évolué au fil des années, mais toutes les versions reposent toujours sur deux éléments : données et un modèle.
Dans le cas de l’ASR, les données sont de la parole annotée – des fichiers audio de langue parlée et leurs transcriptions correspondantes.
Le modèle est l’algorithme qui prédit la transcription à partir de l’audio. Les données annotées servent à entraîner le modèle pour qu’il puisse généraliser sur des exemples de parole inconnus.
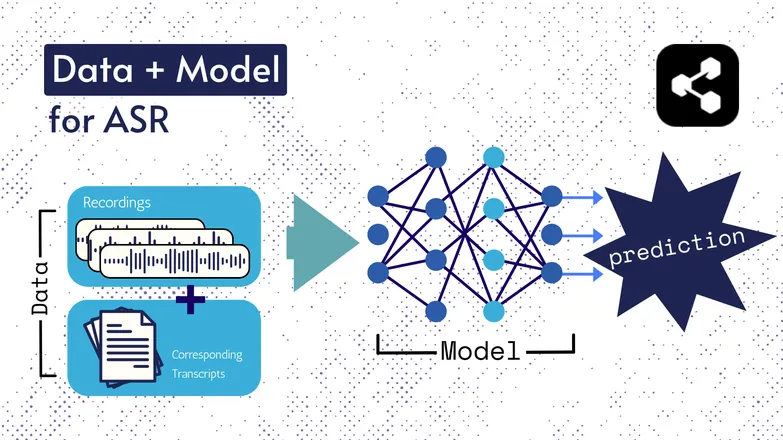
C’est un peu comme comprendre une suite de mots, même si vous ne les avez jamais entendus dans cet ordre ou prononcés par un inconnu.
Encore une fois, les types de modèles et leurs détails ont évolué, et tous les progrès en rapidité et en précision dépendent de la taille et des caractéristiques des jeux de données et des modèles.
Petite parenthèse : extraction de caractéristiques
J’ai parlé des caractéristiques, ou représentations dans mon article sur la synthèse vocale. Elles sont utilisées dans les modèles ASR, anciens comme récents.
L’extraction de caractéristiques — transformer la parole en caractéristiques — est la première étape dans quasiment tous les pipelines ASR.
En résumé, ces caractéristiques, souvent des spectrogrammes, résultent d’un calcul mathématique appliqué à la parole, et transforment la parole dans un format qui met en avant les similarités au sein d’un même énoncé, tout en minimisant les différences entre locuteurs.
Autrement dit, le même énoncé prononcé par deux locuteurs différents produira des spectrogrammes similaires, peu importe la différence de voix.
Je précise cela pour vous signaler que je vais parler de modèles qui « prédisent des transcriptions à partir de la parole ». Ce n’est pas tout à fait exact ; les modèles prédisent à partir des caractéristiques. Mais vous pouvez considérer l’extraction de caractéristiques comme faisant partie du modèle.
Premiers ASR : HMM-GMM
Les modèles de Markov cachés (HMM) et les modèles de mélanges gaussiens (GMM) sont des modèles prédictifs utilisés avant que les réseaux neuronaux profonds ne s’imposent.
Les HMM ont dominé l’ASR jusqu’à récemment.
À partir d’un fichier audio, le HMM prédisait la durée d’un phonème, et le GMM prédisait le phonème lui-même.
Cela semble inversé, et ça l’est un peu, comme :
- HMM : « Les 0,2 premières secondes correspondent à un phonème. »
- GMM : « Ce phonème est un G, comme dans Gary. »
Pour transformer un extrait audio en texte, il fallait quelques éléments supplémentaires, notamment :
- Un dictionnaire de prononciation : une liste exhaustive des mots du vocabulaire, avec leur prononciation correspondante.
- Un modèle de langue : combinaisons de mots du vocabulaire, et leurs probabilités d’apparaître ensemble.
Donc même si le GMM prédit /f/ au lieu de /s/, le modèle de langue sait qu’il est bien plus probable que la personne ait dit « a penny for your thoughts » et non foughts.
On avait toutes ces parties parce que, pour être franc, aucune étape de cette chaîne n’était exceptionnellement performante.
Le HMM se trompait sur les alignements, le GMM confondait les sons proches : /s/ et /f/, /p/ et /t/, et je ne parle même pas des voyelles.
Et ensuite, le modèle de langue transformait ce chaos de phonèmes incohérents en quelque chose de plus proche du langage.
ASR de bout en bout avec l’apprentissage profond
De nombreux éléments du pipeline ASR ont depuis été regroupés.
Au lieu d’entraîner des modèles séparés pour l’orthographe, l’alignement et la prononciation, un seul modèle prend la parole en entrée et produit (avec un peu de chance) des mots correctement orthographiés, et, aujourd’hui, des repères temporels aussi.
(Même si, en pratique, on corrige ou « réévalue » souvent cette sortie avec un modèle de langue supplémentaire.)
Cela ne veut pas dire que des aspects comme l’alignement ou l’orthographe ne reçoivent pas d’attention particulière. Il existe encore une multitude de publications qui cherchent à corriger des problèmes très spécifiques.
C’est-à-dire que des chercheurs imaginent des modifications d’architecture de modèle pour cibler certains aspects de la performance, comme :
- Un décodeur RNN-Transducer conditionné sur les sorties précédentes pour améliorer l’orthographe.
- Un sous-échantillonnage convolutionnel pour limiter les sorties vides et améliorer l’alignement.
Je sais que ça paraît abscons. J’anticipe juste la question de mon chef : « tu peux donner un exemple concret ? »
La réponse est non.
Non, je ne peux pas.
Comment mesure-t-on la performance de l’ASR ?
Quand l’ASR fonctionne mal, on le remarque tout de suite.
J’ai déjà vu caramelization transcrit par communist Asians. Crispiness transformé en Chris p — vous voyez le genre.
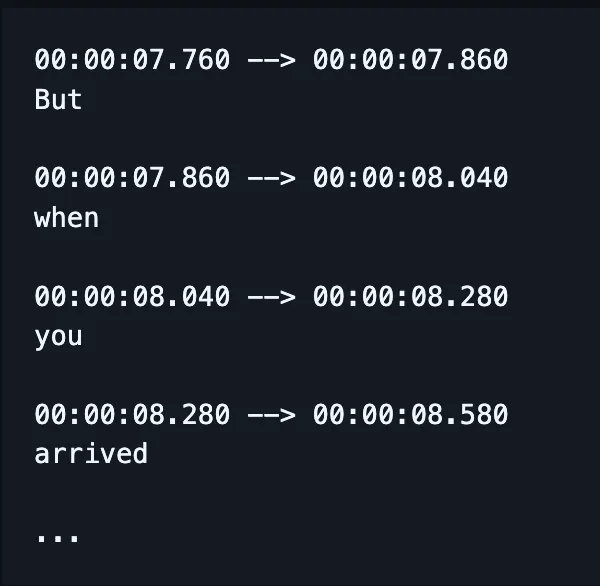
L’indicateur utilisé pour quantifier les erreurs est le taux d’erreur sur les mots (WER). La formule du WER est la suivante :
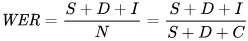
Où :
- S est le nombre de substitutions (mots modifiés dans le texte prédit pour correspondre au texte de référence)
- D est le nombre de suppressions (mots manquants dans la sortie, par rapport au texte de référence)
- I est le nombre d’insertions (mots ajoutés dans la sortie, par rapport au texte de référence)
- N est le nombre total de mots dans le texte de référence
Par exemple, si le texte de référence est « le chat est assis. »
- Si le modèle produit « le chat a coulé », c’est une substitution.
- Si le modèle produit « chat assis », c’est une suppression.
- S’il produit « le chat s’est assis », c’est une insertion.
Quelles sont les applications de l’ASR ?
L’ASR est un outil très pratique.
Il a aussi permis d’améliorer notre qualité de vie grâce à une meilleure sécurité, accessibilité et efficacité dans des secteurs clés.
Santé
Quand je dis à des médecins que je travaille sur la reconnaissance vocale, ils me répondent « ah, comme Dragon. »
Avant l’arrivée de l’IA générative dans la santé, les médecins prenaient des notes orales à 30 mots par minute avec un vocabulaire limité.
La reconnaissance automatique de la parole (ASR) a grandement contribué à réduire l’épuisement professionnel généralisé chez les médecins.
Les médecins jonglent entre une montagne de paperasse et la nécessité de s’occuper de leurs patients. Dès 2018, des chercheurs plaidaient pour l’utilisation de la transcription numérique lors des consultations afin d’améliorer la qualité des soins.
En effet, devoir documenter les consultations après coup réduit non seulement le temps passé avec les patients, mais c’est aussi bien moins précis que des résumés issus de transcriptions des échanges réels.
Maisons intelligentes
J’ai une blague à ce sujet.
Quand je veux éteindre la lumière sans me lever, je tape deux fois dans mes mains — comme si j’avais un clapet.
Mon partenaire ne rit jamais.
Les maisons intelligentes à commande vocale semblent à la fois futuristes et un peu exagérées. Du moins, c’est l’impression que ça donne.
C’est vrai, c’est pratique, mais dans bien des cas, cela permet de faire des choses qui seraient autrement impossibles.
Un bon exemple : la gestion de l’énergie. Ajuster l’éclairage ou le thermostat serait difficile à faire tout au long de la journée si vous deviez vous lever à chaque fois pour tourner un bouton.
La commande vocale rend ces petits ajustements non seulement plus simples, mais elle comprend aussi les nuances du langage humain.
Par exemple, vous dites « tu peux baisser un peu la température ? » L’assistant utilise le traitement du langage naturel pour traduire votre demande en modification de température, en prenant en compte de nombreux autres paramètres : température actuelle, prévisions météo, habitudes des autres utilisateurs, etc.
Vous faites la partie humaine, et laissez l’ordinateur gérer le reste.
C’est bien plus simple que d’essayer de deviner de combien de degrés il faut baisser le chauffage selon votre ressenti.
Et c’est aussi plus économe en énergie : certaines familles ont réduit leur consommation d’énergie de 80 % grâce à l’éclairage intelligent activé par la voix, pour ne citer qu’un exemple.
Support client
On l’a vu dans le domaine de la santé, mais la transcription et le résumé sont bien plus efficaces que de simples comptes rendus faits après coup.
Encore une fois, cela fait gagner du temps et c’est plus précis. Ce qu’on constate à chaque fois, c’est que l’automatisation libère du temps pour mieux faire son travail.
C’est particulièrement vrai dans le support client, où l’assistance boostée par l’ASR affiche un taux de résolution au premier appel supérieur de 25 %.
La transcription et le résumé automatisent l’identification de solutions en fonction du ressenti et de la demande du client.
Assistants embarqués en voiture
On s’inspire ici des assistants à la maison, mais cela mérite d’être mentionné.
La reconnaissance vocale réduit la charge mentale et les distractions visuelles pour les conducteurs.
Et puisque les distractions sont responsables de jusqu’à 30 % des collisions, adopter cette technologie est une évidence pour la sécurité.
Orthophonie
L’ASR est utilisé depuis longtemps comme outil d’évaluation et de traitement des troubles de la parole.
Il est utile de rappeler que les machines ne font pas qu’automatiser des tâches, elles réalisent aussi ce que l’humain ne peut pas faire.
La reconnaissance vocale peut détecter des subtilités dans la parole quasiment imperceptibles à l’oreille humaine, repérant des particularités qui passeraient autrement inaperçues.
L’avenir de l’ASR
La reconnaissance vocale (STT) est devenue si performante qu’on n’y pense même plus.
Mais en coulisses, les chercheurs travaillent à la rendre encore plus puissante, accessible — et discrète.
J’ai sélectionné quelques tendances prometteuses qui exploitent les avancées de l’ASR, et ajouté quelques réflexions personnelles.
Reconnaissance vocale sur l’appareil
La plupart des solutions ASR fonctionnent dans le cloud. Vous avez sûrement déjà entendu ça. Cela signifie que le modèle tourne sur un ordinateur distant, ailleurs.
C’est parce que le processeur de votre téléphone n’est pas forcément capable de faire tourner ces modèles volumineux, ou alors la transcription prendrait un temps fou.
À la place, votre audio est envoyé via Internet à un serveur distant équipé d’un GPU bien trop puissant pour tenir dans votre poche. Le GPU exécute le modèle ASR et renvoie la transcription sur votre appareil.
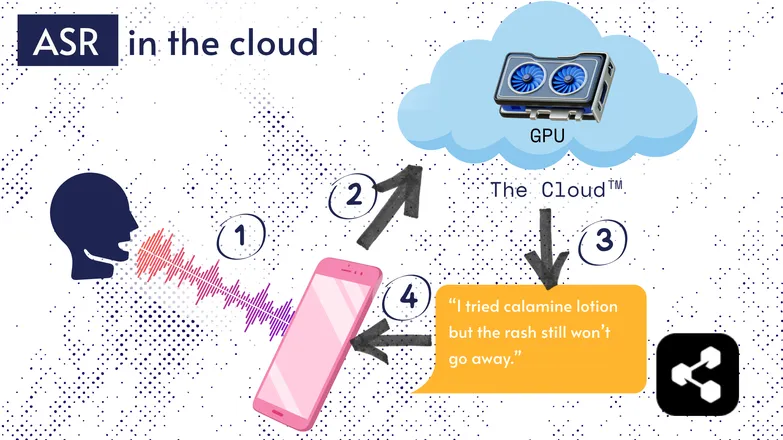
Pour des raisons d’efficacité énergétique et de sécurité (tout le monde ne veut pas que ses données personnelles circulent sur Internet), beaucoup de recherches visent à rendre les modèles suffisamment compacts pour fonctionner directement sur votre appareil : téléphone, ordinateur ou navigateur.
J’ai moi-même rédigé un mémoire sur la quantification des modèles ASR pour les faire tourner en local. Picovoice est une entreprise canadienne qui développe une IA vocale à faible latence sur appareil, et ils ont l’air prometteurs.
L’ASR embarqué rend la transcription plus accessible et moins coûteuse, ce qui peut bénéficier aux communautés à faibles revenus.
Interface « Transcript-First »
L’écart entre l’audio et la transcription se réduit. Qu’est-ce que ça signifie?
Des éditeurs vidéo comme Premiere Pro ou Descript permettent de naviguer dans vos enregistrements via une transcription: cliquez sur un mot et vous êtes transporté à l’instant correspondant.
Besoin de plusieurs prises ? Choisissez votre préférée et supprimez les autres, comme dans un éditeur de texte. La vidéo est automatiquement découpée pour vous.
C’est très frustrant de monter uniquement avec une forme d’onde, mais c’est d’une simplicité déconcertante avec un éditeur basé sur la transcription.
De même, des messageries comme WhatsApp transcrivent vos messages vocaux et vous permettent de naviguer dans l’audio via le texte. Faites glisser votre doigt sur un mot, et vous arrivez à ce moment précis de l’enregistrement.

Petite anecdote : j’ai en fait développé quelque chose de similaire environ une semaine avant qu’Apple n’annonce une fonctionnalité comparable.
Ces exemples montrent comment des technologies complexes en coulisses apportent simplicité et intuitivité aux applications destinées aux utilisateurs.
Équité, inclusion et langues peu dotées
La bataille n’est pas encore gagnée.
L’ASR fonctionne très bien en anglais et dans d’autres langues courantes et bien dotées. Ce n’est pas forcément le cas pour les langues peu dotées.
Il existe des écarts pour les minorités dialectales, les troubles de la parole et d’autres enjeux liés à l’équité dans la technologie vocale.
Désolé de casser l’ambiance. Cette section s’appelle «l’avenir» de l’ASR. Et je préfère croire à un futur dont on pourra être fier.
Si nous voulons avancer, faisons-le ensemble, sinon nous risquons d’aggraver les inégalités sociales.
Commencez à utiliser l’ASR dès aujourd’hui
Quel que soit votre secteur, utiliser l’ASR est une évidence — mais vous vous demandez sûrement comment commencer. Comment mettre en place l’ASR ? Comment transmettre ces données à d’autres outils ?
Botpress propose des cartes de transcription simples à utiliser. Elles s’intègrent dans un flow en glisser-déposer, et peuvent être enrichies avec des dizaines d’intégrations à travers différentes applications et canaux de communication.
Commencez à créer dès aujourd’hui. C’est gratuit.
FAQ
Quelle est la précision de l’ASR moderne pour différents accents et dans des environnements bruyants ?
Les systèmes ASR modernes sont très précis pour les accents courants dans les principales langues, atteignant des taux d’erreur de mots (WER) inférieurs à 10 % dans des conditions idéales, mais la précision diminue nettement avec des accents marqués, des dialectes ou beaucoup de bruit de fond. Des fournisseurs comme Google et Microsoft entraînent leurs modèles sur des données vocales variées, mais obtenir une transcription parfaite dans un environnement bruyant reste un défi.
L’ASR est-il fiable pour transcrire le jargon spécialisé ou les termes propres à un secteur ?
L’ASR est moins fiable par défaut pour le jargon spécialisé ou les termes propres à un secteur, car ses données d’entraînement sont généralement orientées vers le langage courant ; les mots inconnus peuvent être mal retranscrits ou ignorés. Cependant, les solutions professionnelles permettent d’ajouter des vocabulaires personnalisés, des modèles linguistiques spécifiques à un domaine et des dictionnaires de prononciation pour améliorer la reconnaissance des termes techniques dans des domaines comme la santé, le droit ou l’ingénierie.
Quelle est la différence entre les outils ASR gratuits et les solutions professionnelles?
La différence entre les outils ASR gratuits et les solutions professionnelles concerne la précision, l’évolutivité, la personnalisation et la gestion de la confidentialité: les outils gratuits ont souvent un taux d’erreur plus élevé, un support linguistique limité et des restrictions d’utilisation, tandis que les solutions professionnelles offrent un WER plus bas, une personnalisation par domaine, des intégrations, des accords de niveau de service (SLA) et des fonctionnalités de sécurité avancées pour les données sensibles.
Comment l’ASR protège-t-il la vie privée des utilisateurs et les informations sensibles lors de la transcription ?
La reconnaissance automatique de la parole protège la vie privée des utilisateurs grâce au chiffrement lors de la transmission des données et propose des options comme l’exécution des modèles directement sur l’appareil, évitant ainsi l’envoi des données vocales vers des serveurs externes. De nombreux fournisseurs pour les entreprises respectent également des réglementations telles que le RGPD ou l’HIPAA et peuvent anonymiser les données pour protéger les informations sensibles.
Quel est le coût des services ASR dans le cloud par rapport aux solutions embarquées ?
Les services ASR dans le cloud facturent généralement à la minute audio ou par paliers d’utilisation, avec des coûts allant de 0,03 $ à plus de 1,00 $ la minute selon la précision et les fonctionnalités, tandis que les solutions embarquées impliquent des coûts de développement initiaux et des frais de licence.



