



- El ASR convierte el habla en texto mediante aprendizaje automático, permitiendo comandos de voz y transcripción en tiempo real.
- Los sistemas modernos de ASR han pasado de modelos de fonemas separados (HMM-GMM) a modelos de aprendizaje profundo que predicen palabras completas.
- El rendimiento del ASR se mide por la Tasa de Error de Palabras (WER), con errores que provienen de sustituciones, eliminaciones o inserciones; una WER más baja = mejor calidad de transcripción.
- El futuro del ASR se centra en el procesamiento en el dispositivo para mayor privacidad y en el soporte para idiomas poco representados.
¿Cuándo fue la última vez que viste algo sin subtítulos?
Antes eran opcionales, pero ahora aparecen en videos cortos nos guste o no. Los subtítulos están tan integrados en el contenido que a veces ni los notamos.
El reconocimiento automático de voz (ASR), la capacidad de convertir palabras habladas en texto de forma rápida y precisa, es la tecnología que impulsa este cambio.
Cuando pensamos en un agente de voz con IA, pensamos en las palabras que elige, cómo las dice y el tono de voz.
Pero es fácil olvidar que la fluidez de nuestras interacciones depende de que el bot nos entienda. Y llegar a este punto —que el bot te entienda entre “eh” y “ah” en un entorno ruidoso— no ha sido sencillo.
Hoy vamos a hablar sobre la tecnología detrás de esos subtítulos: el reconocimiento automático de voz (ASR).
Permíteme presentarme: tengo una maestría en tecnología del habla y, en mi tiempo libre, me gusta leer sobre lo último en ASR e incluso construir cosas.
Te explicaré los conceptos básicos del ASR, veremos cómo funciona la tecnología y haré una predicción sobre hacia dónde podría ir.
¿Qué es el ASR?
El reconocimiento automático de voz (ASR), o conversión de voz a texto (STT), es el proceso de convertir el habla en texto escrito mediante tecnología de aprendizaje automático.
Las tecnologías que involucran el habla suelen integrar ASR de alguna manera; puede ser para subtitular videos, transcribir interacciones de soporte al cliente para su análisis, o como parte de una interacción con un asistente de voz, entre otros.
Algoritmos de Voz a Texto
Las tecnologías subyacentes han cambiado con los años, pero todas las versiones han consistido en dos componentes de alguna forma: datos y un modelo.
En el caso del ASR, los datos son habla etiquetada: archivos de audio de lenguaje hablado y sus transcripciones correspondientes.
El modelo es el algoritmo que se usa para predecir la transcripción a partir del audio. Los datos etiquetados se usan para entrenar el modelo, para que pueda generalizar con ejemplos de habla no vistos.
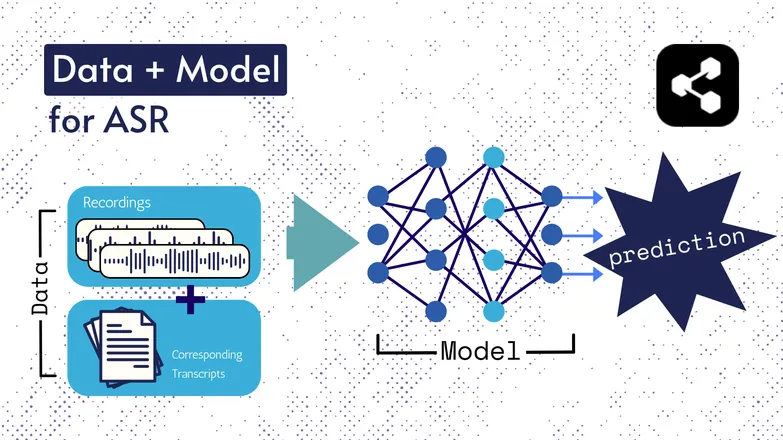
Es parecido a cómo puedes entender una serie de palabras, aunque nunca las hayas escuchado en ese orden o las diga alguien desconocido.
De nuevo, los tipos de modelos y sus detalles han cambiado con el tiempo, y todos los avances en velocidad y precisión se deben al tamaño y las características de los conjuntos de datos y modelos.
Nota rápida: Extracción de características
Hablé sobre características o representaciones en mi artículo sobre texto a voz. Se usan en modelos de ASR tanto antiguos como actuales.
La extracción de características —convertir el habla en características— es el primer paso en casi todas las cadenas de ASR.
En resumen, estas características, a menudo espectrogramas, son el resultado de un cálculo matemático sobre el habla y convierten el habla en un formato que resalta similitudes dentro de una frase y minimiza diferencias entre hablantes.
Es decir, la misma frase dicha por dos personas diferentes tendrá espectrogramas similares, sin importar cuán distintas sean sus voces.
Menciono esto para que sepas que hablaré de modelos que “predicen transcripciones a partir del habla”. Técnicamente no es así; los modelos predicen a partir de características. Pero puedes considerar la extracción de características como parte del modelo.
Primeros ASR: HMM-GMM
Modelos ocultos de Markov (HMM) y modelos de mezcla gaussiana (GMM) son modelos predictivos de antes de que las redes neuronales profundas dominaran.
Los HMM dominaron el ASR hasta hace poco.
Dado un archivo de audio, el HMM predecía la duración de un fonema y el GMM predecía el fonema en sí.
Suena al revés, y en cierto modo lo es, así:
- HMM: “Los primeros 0,2 segundos son un fonema.”
- GMM: “Ese fonema es una G, como en Gary.”
Convertir un clip de audio en texto requería algunos componentes extra, en concreto:
- Un diccionario de pronunciación: una lista exhaustiva de las palabras del vocabulario con sus pronunciaciones correspondientes.
- Un modelo de lenguaje: combinaciones de palabras del vocabulario y la probabilidad de que aparezcan juntas.
Así que, aunque el GMM prediga /f/ en vez de /s/, el modelo de lenguaje sabe que es mucho más probable que el hablante haya dicho “a penny for your thoughts” y no foughts.
Teníamos todas estas partes porque, siendo sinceros, ninguna parte de esta cadena era especialmente buena.
El HMM se equivocaba en las alineaciones, el GMM confundía sonidos parecidos: /s/ y /f/, /p/ y /t/, y ni hablar de las vocales.
Y luego el modelo de lenguaje arreglaba el desastre de fonemas incoherentes para que sonara más a lenguaje real.
ASR de extremo a extremo con aprendizaje profundo
Muchos de los componentes de una cadena de ASR se han unificado desde entonces.
En vez de entrenar modelos separados para ortografía, alineación y pronunciación, un solo modelo recibe el habla y produce (con suerte) palabras bien escritas y, hoy en día, también marcas de tiempo.
(Aunque en la práctica, a menudo se corrige o “recalifica” esta salida con un modelo de lenguaje adicional.)
Eso no significa que factores como la alineación y la ortografía no reciban atención especial. Todavía hay muchísima investigación enfocada en solucionar problemas muy concretos.
Es decir, los investigadores idean formas de modificar la arquitectura de un modelo para mejorar aspectos específicos de su rendimiento, como:
- Un decodificador RNN-Transducer condicionado por salidas previas para mejorar la ortografía.
- Reducción por convolución para limitar salidas en blanco y mejorar la alineación.
Sé que esto suena a chino. Solo me adelanto a que mi jefe pregunte “¿puedes dar un ejemplo sencillo?”
La respuesta es no.
No, no puedo.
¿Cómo se mide el rendimiento en ASR?
Cuando el ASR falla, se nota.
He visto caramelización transcrita como comunistas asiáticos. Crujiente como Chris p — ya te haces una idea.
La métrica que usamos para reflejar los errores matemáticamente es la tasa de error de palabras (WER). La fórmula de WER es:
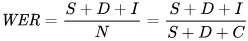
Donde:
- S es el número de sustituciones (palabras cambiadas en el texto predicho para que coincida con el texto de referencia)
- D es el número de eliminaciones (palabras que faltan en la salida en comparación con el texto de referencia)
- I es el número de inserciones (palabras adicionales en la salida en comparación con el texto de referencia)
- N es el número total de palabras en la referencia
Por ejemplo, si la referencia es “el gato se sentó”.
- Si el modelo dice “el gato se hundió”, eso es una sustitución.
- Si el modelo dice “gato se sentó”, eso es una eliminación.
- Si dice “el gato se ha sentado”, eso es una inserción.
¿Cuáles son las aplicaciones del ASR?
El ASR es una herramienta muy útil.
También ha mejorado nuestra calidad de vida al aportar más seguridad, accesibilidad y eficiencia en sectores clave.
Salud
Cuando le digo a médicos que investigo reconocimiento de voz, me dicen “ah, como Dragon.”
Antes de que existiera la IA generativa en el sector salud, los médicos tomaban notas verbales a 30 palabras por minuto y con un vocabulario limitado.
El reconocimiento automático de voz (ASR) ha sido fundamental para reducir el agotamiento generalizado que sufren los médicos.
Los médicos deben equilibrar montañas de papeleo con la atención a sus pacientes. Ya en 2018, los investigadores pedían el uso de transcripción digital en las consultas para mejorar la capacidad de los médicos de brindar atención.
Esto se debe a que documentar las consultas después de haberlas realizado no solo reduce el tiempo cara a cara con los pacientes, sino que también es mucho menos preciso que los resúmenes generados a partir de transcripciones de las consultas reales.
Hogares inteligentes
Tengo un chiste que siempre hago.
Cuando quiero apagar las luces pero no me apetece levantarme, aplaudo dos veces rápido, como si tuviera un interruptor por palmadas.
A mi pareja nunca le hace gracia.
Los hogares inteligentes activados por voz parecen tanto futuristas como un lujo innecesario. O eso parece.
Claro, son prácticos, pero en muchos casos permiten hacer cosas que de otro modo no serían posibles.
Un buen ejemplo es el consumo de energía: hacer pequeños ajustes en la iluminación o el termostato sería inviable durante el día si tuvieras que levantarte y girar una perilla.
La activación por voz hace que esos pequeños cambios sean más fáciles de realizar y, además, interpreta los matices del habla humana.
Por ejemplo, dices “¿puedes ponerlo un poco más fresco?” El asistente utiliza procesamiento de lenguaje natural para traducir tu petición en un cambio de temperatura, considerando muchos otros datos: la temperatura actual, el pronóstico del tiempo, el uso del termostato por otros usuarios, etc.
Tú haces la parte humana y dejas lo técnico al ordenador.
Diría que eso es mucho más sencillo que tener que adivinar cuántos grados bajar la calefacción según lo que sientes.
Y además es más eficiente energéticamente: hay informes de familias que han reducido el consumo de energía hasta en un 80% usando iluminación inteligente activada por voz, por dar un ejemplo.
Atención al cliente
Ya lo mencionamos en el sector salud, pero transcribir y resumir es mucho más efectivo que pedir a las personas que hagan resúmenes después de las interacciones.
De nuevo, ahorra tiempo y es más preciso. Lo que aprendemos una y otra vez es que la automatización libera tiempo para que las personas hagan mejor su trabajo.
Y esto es especialmente cierto en la atención al cliente, donde el soporte impulsado por ASR tiene una tasa de resolución en la primera llamada un 25% mayor.
La transcripción y el resumen ayudan a automatizar el proceso de encontrar una solución según el sentimiento y la consulta del cliente.
Asistentes dentro del coche
Aquí nos apoyamos en los asistentes para el hogar, pero merece la pena mencionarlo.
El reconocimiento de voz reduce la carga cognitiva y las distracciones visuales para los conductores.
Y considerando que las distracciones representan hasta el 30% de las colisiones, implementar esta tecnología es una decisión obvia para la seguridad.
Patología del habla
El ASR se ha utilizado durante mucho tiempo como herramienta para evaluar y tratar patologías del habla.
Conviene recordar que las máquinas no solo automatizan tareas, también hacen cosas que los humanos no pueden.
El reconocimiento de voz puede detectar sutilezas en el habla que son casi imperceptibles para el oído humano, identificando detalles de un habla afectada que de otro modo pasarían desapercibidos.
El futuro del ASR
El reconocimiento de voz a texto (STT) ha mejorado tanto que ya ni pensamos en ello.
Pero detrás de escena, los investigadores siguen trabajando para hacerlo aún más potente, accesible y menos intrusivo.
He seleccionado algunas tendencias interesantes que aprovechan los avances en ASR, junto con algunas reflexiones personales.
Reconocimiento de voz en el dispositivo
La mayoría de las soluciones ASR funcionan en la nube. Seguro que ya lo has oído. Eso significa que el modelo se ejecuta en un ordenador remoto, en otro lugar.
Esto se hace porque el pequeño procesador de tu teléfono no puede ejecutar modelos tan grandes, o tardaría muchísimo en transcribir cualquier cosa.
En su lugar, tu audio se envía por internet a un servidor remoto con una GPU demasiado potente como para llevarla en el bolsillo. La GPU ejecuta el modelo ASR y devuelve la transcripción a tu dispositivo.
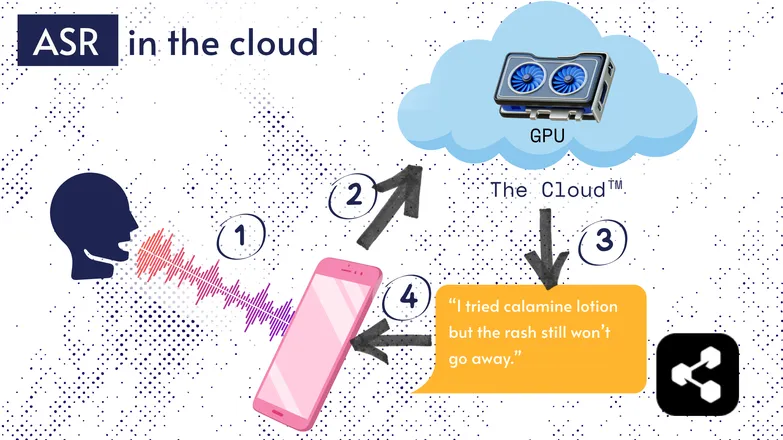
Por motivos de eficiencia energética y seguridad (no todo el mundo quiere que sus datos personales circulen por internet), se ha investigado mucho para hacer modelos lo suficientemente compactos como para ejecutarse directamente en tu dispositivo, ya sea un teléfono, un ordenador o un navegador.
Yo mismo escribí una tesis sobre la cuantización de modelos ASR para que puedan funcionar en el dispositivo. Picovoice es una empresa canadiense que desarrolla IA de voz de baja latencia en el dispositivo, y parecen interesantes.
El ASR en el dispositivo hace que la transcripción sea más accesible y económica, con potencial para llegar a comunidades de bajos ingresos.
Interfaz centrada en la transcripción
La brecha entre el audio y las transcripciones se está reduciendo. ¿Qué significa esto?
Editores de video como Premiere Pro y Descript te permiten navegar tus grabaciones a través de una transcripción: haz clic en una palabra y te lleva a la marca de tiempo.
¿Tuviste que grabar varias tomas? Elige tu favorita y borra las demás, como en un editor de texto. El video se recorta automáticamente por ti.
Editar solo con la forma de onda es frustrante, pero con editores basados en transcripción es facilísimo.
De forma similar, servicios de mensajería como WhatsApp transcriben tus notas de voz y te permiten desplazarte por ellas usando el texto. Desliza el dedo sobre una palabra y saltas a esa parte de la grabación.

Historia curiosa: yo en realidad construí algo parecido aproximadamente una semana antes de que Apple anunciara una función similar.
Estos ejemplos muestran cómo tecnologías complejas hacen que las aplicaciones para el usuario final sean más simples e intuitivas.
Equidad, inclusión y lenguas poco representadas
La batalla aún no está ganada.
El ASR funciona muy bien en inglés y otros idiomas comunes y con muchos recursos. No es necesariamente así para los idiomas poco representados.
Hay una brecha en dialectos minoritarios, habla afectada y otros problemas relacionados con la equidad en la tecnología de voz.
Perdón por cortar el buen rollo. Esta sección se llama el “futuro” del ASR. Y elijo mirar hacia un futuro del que podamos sentirnos orgullosos.
Si vamos a avanzar, debemos hacerlo juntos, o corremos el riesgo de aumentar la desigualdad social.
Empieza a usar ASR hoy mismo
No importa tu negocio, usar ASR es una decisión obvia — aunque probablemente te preguntes cómo empezar. ¿Cómo se implementa ASR? ¿Cómo se transfiere esa información a otras herramientas?
Botpress incluye tarjetas de transcripción fáciles de usar. Se pueden integrar en un flujo de trabajo visual, y ampliar con decenas de integraciones en aplicaciones y canales de comunicación.
Empieza a construir hoy. Es gratis.
Preguntas frecuentes
¿Qué tan preciso es el ASR moderno para diferentes acentos y ambientes ruidosos?
Los sistemas ASR modernos son sorprendentemente precisos para acentos comunes en los principales idiomas, logrando tasas de error de palabras (WER) inferiores al 10% en condiciones óptimas, pero la precisión disminuye notablemente con acentos marcados, dialectos o mucho ruido de fondo. Proveedores como Google y Microsoft entrenan modelos con datos de voz diversos, pero la transcripción perfecta en ambientes ruidosos sigue siendo un reto.
¿Es confiable el ASR para transcribir jerga especializada o términos específicos de una industria?
El ASR es menos confiable de forma predeterminada para jerga especializada o términos específicos de una industria porque su entrenamiento suele estar orientado al habla general; las palabras poco comunes pueden transcribirse mal o no aparecer. Sin embargo, las soluciones empresariales permiten vocabularios personalizados, modelos de lenguaje específicos de dominio y diccionarios de pronunciación para mejorar el reconocimiento de términos técnicos en áreas como salud, derecho o ingeniería.
¿Cuál es la diferencia entre las herramientas ASR gratuitas y las soluciones empresariales?
La diferencia entre las herramientas ASR gratuitas y las soluciones empresariales está en la precisión, escalabilidad, personalización y controles de privacidad: las gratuitas suelen tener más errores, menos idiomas y límites de uso, mientras que las empresariales ofrecen menor WER, personalización por sector, integraciones, acuerdos de nivel de servicio (SLA) y funciones de seguridad robustas para datos sensibles.
¿Cómo protege el ASR la privacidad del usuario y la información sensible durante la transcripción?
ASR protege la privacidad del usuario mediante el cifrado durante la transmisión de datos y ofrece opciones como ejecutar los modelos en el propio dispositivo para evitar enviar datos de voz a servidores externos. Muchos proveedores empresariales también cumplen con normativas de privacidad como GDPR o HIPAA y pueden anonimizar los datos para proteger la información sensible.
¿Qué tan costosos son los servicios ASR en la nube en comparación con las soluciones en el dispositivo?
Los servicios ASR en la nube suelen cobrar por minuto de audio o por niveles de uso, con precios que van desde $0.03 hasta más de $1.00 por minuto según la precisión y las funciones, mientras que las soluciones en dispositivo implican costos iniciales de desarrollo y licencias.



