



- Binabago ng ASR ang sinasalita tungo sa teksto gamit ang machine learning, na nagpapagana sa voice commands at real-time na transcription.
- Ang mga makabagong sistema ng ASR ay lumipat mula sa magkakahiwalay na phoneme models (HMM-GMM) patungo sa deep learning models na kayang hulaan ang buong salita.
- Sinusukat ang performance ng ASR gamit ang Word Error Rate (WER), kung saan ang mga pagkakamali ay mula sa pagpapalit, pagtanggal, o pagdagdag ng salita; mas mababa ang WER = mas maganda ang kalidad ng transcription.
- Ang hinaharap ng ASR ay nakatuon sa pagproseso mismo sa device para sa privacy at suporta sa mga wikang kakaunti ang resources.
Kailan ka huling nanood ng palabas na walang subtitles?
Dati ay opsyonal lang ito, pero ngayon ay palaging lumalabas sa maiikling video kahit ayaw natin. Napaka-karaniwan na ng captions sa mga content kaya nakakalimutan mong nariyan sila.
Ang automatic speech recognition (ASR) — ang kakayahang mabilis at tumpak na gawing teksto ang sinasalitang salita — ang teknolohiyang nagpapalaganap ng pagbabagong ito.
Kapag iniisip natin ang isang AI voice agent, naiisip natin ang pagpili nito ng salita, paraan ng pagsasalita, at mismong boses.
Pero madaling makalimutan na ang pagiging natural ng ating usapan ay nakasalalay sa pag-unawa ng bot sa atin. At ang makarating sa puntong ito — na naiintindihan ka ng bot kahit may mga “uhm” at “ah” sa maingay na paligid — ay hindi naging madali.
Ngayon, pag-uusapan natin ang teknolohiyang nagpapagana sa mga caption na iyon: automatic speech recognition (ASR).
Hayaan ninyong ipakilala ko ang sarili ko: may master’s ako sa speech technology, at kapag may oras, nagbabasa ako tungkol sa mga bagong balita sa ASR, at minsan ay gumagawa rin ako ng mga proyekto.
Ipapaliwanag ko sa inyo ang mga pangunahing kaalaman sa ASR, sisilipin natin ang teknolohiya sa likod nito, at huhulaan kung saan pa ito patutungo.
Ano ang ASR?
Ang automatic speech recognition (ASR), o speech-to-text (STT), ay proseso ng pagbago ng sinasalita tungo sa nakasulat na teksto gamit ang teknolohiyang machine learning.
Ang mga teknolohiyang may kinalaman sa pagsasalita ay madalas na gumagamit ng ASR sa iba’t ibang paraan; maaaring para sa paglalagay ng caption sa video, pag-transcribe ng usapan sa customer support para sa pagsusuri, o bahagi ng voice assistant na interaksyon, at marami pang iba.
Mga Algoritmo ng Speech-to-Text
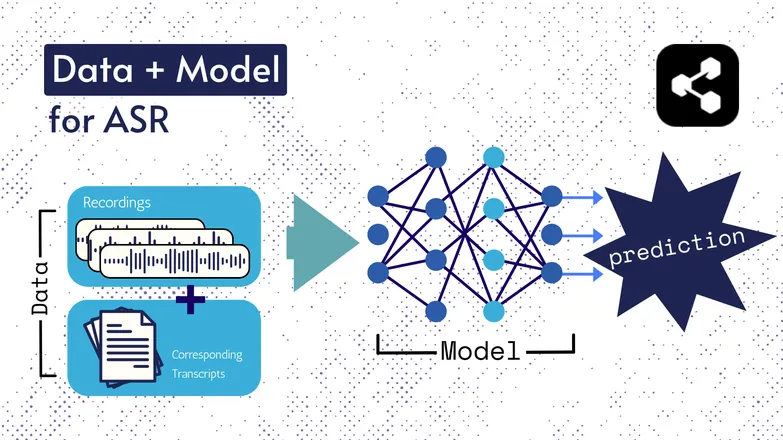
Nagbago na ang mga teknolohiyang ginagamit sa pagdaan ng panahon, pero lahat ng bersyon ay binubuo ng dalawang pangunahing bahagi: data at isang modelo.
Sa kaso ng ASR, ang data ay mga labeled na pagsasalita – mga audio file ng sinasalita at ang kanilang kaukulang transcription.
Ang modelo ay ang algorithm na ginagamit para hulaan ang transcription mula sa audio. Ginagamit ang labeled data para sanayin ang modelo, para matuto itong mag-generalize sa mga hindi pa naririnig na halimbawa ng pagsasalita.
Parang ganito rin kung paano mo nauunawaan ang isang serye ng mga salita, kahit hindi mo pa narinig sa ganoong pagkakasunod, o iba ang nagsalita.
Muli, nagbago na ang klase ng mga modelo at detalye nito sa pagdaan ng panahon, at lahat ng pag-unlad sa bilis at katumpakan ay nakasalalay sa laki at kalidad ng datasets at mga modelo.
Saglit na Usapan: Feature Extraction
Nabanggit ko ang features, o representations sa aking artikulo tungkol sa text-to-speech. Ginagamit ang mga ito sa mga ASR model noon at ngayon.
Ang feature extraction — ang pagbago ng pagsasalita tungo sa features — ang unang hakbang sa halos lahat ng ASR pipeline.
Sa madaling salita, ang mga features na ito, kadalasan ay spectrograms, ay resulta ng matematikal na kalkulasyon sa pagsasalita, at ginagawang anyo ang speech na nagpapalakas ng pagkakatulad ng isang sinambit, at nagpapaliit ng pagkakaiba ng mga nagsasalita.
Ibig sabihin, ang parehong sinabi ng dalawang magkaibang tao ay magkakaroon ng magkahawig na spectrogram, kahit magkaiba ang boses nila.
Binabanggit ko ito para malaman ninyo na kapag sinabi kong ang mga modelo ay “naghuhula ng transcript mula sa speech”, hindi iyon eksaktong totoo; mula sila sa features. Pero maaari ninyong ituring na bahagi ng modelo ang feature extraction.
Unang ASR: HMM-GMM
Ang Hidden markov models (HMMs) at Gaussian mixture models (GMMs) ay mga predictive model bago pa man naghari ang deep neural networks.
Ang HMMs ang namayani sa ASR hanggang kamakailan lang.
Kapag may audio file, huhulaan ng HMM ang tagal ng isang phoneme, at huhulaan naman ng GMM kung aling phoneme iyon.
Medyo baligtad pakinggan, at totoo nga, parang ganito:
- HMM: “Ang unang 0.2 segundo ay isang phoneme.”
- GMM: “Ang phoneme na iyon ay G, gaya ng sa Gary.”
Para gawing teksto ang isang audio clip, kailangan pa ng ilang karagdagang bahagi, tulad ng:
- Isang pronunciation dictionary: isang kumpletong listahan ng mga salita sa bokabularyo, kasama ang kanilang mga bigkas.
- Isang language model: Mga kombinasyon ng salita sa bokabularyo, at ang posibilidad na magkasama silang lumitaw.
Kaya kahit ang GMM ay pumili ng /f/ kaysa /s/, alam ng language model na mas malamang na sinabi ng nagsasalita ang “a penny for your thoughts”, hindi foughts.
Mayroon tayong lahat ng bahaging ito dahil, sa totoo lang, walang bahagi ng pipeline na ito ang talagang mahusay.
Madalas magkamali ang HMM sa pag-align, at nalilito ang GMM sa magkahawig na tunog: /s/ at /f/, /p/ at /t/, at huwag na nating pag-usapan ang mga patinig.
At pagkatapos, ang language model ang nag-aayos ng magulong phoneme para maging mas katulad ng totoong wika.
End-to-End ASR gamit ang Deep Learning
Marami sa mga bahagi ng ASR pipeline ay pinagsama-sama na ngayon.
Sa halip na magsanay ng magkakahiwalay na modelo para sa spelling, alignment, at bigkas, isang modelo na lang ang tumatanggap ng speech at naglalabas ng (sana) tamang spelling ng mga salita, at ngayon, pati timestamps.
(Bagamat kadalasan ay kinokorek o “ni-re-rescore” pa ang output na ito gamit ang karagdagang language model.)
Hindi ibig sabihin na ang iba’t ibang aspeto — gaya ng alignment at spelling — ay hindi nabibigyan ng pansin. Marami pa ring pag-aaral na nakatuon sa pag-aayos ng mga tiyak na isyu.
Ibig sabihin, gumagawa ang mga researcher ng paraan para baguhin ang disenyo ng modelo na nakatuon sa partikular na aspeto ng performance nito, gaya ng:
- Isang RNN-Transducer decoder na nakaayon sa mga naunang output para mapabuti ang spelling.
- Convolutional downsampling para mabawasan ang blank output, at mapaganda ang alignment.
Alam kong parang walang saysay ito. Nauuna lang akong magpaliwanag bago tanungin ng boss ko ng “pwede bang gawing mas simple?”
Ang sagot ay hindi.
Hindi ko kaya.
Paano Sinusukat ang Performance ng ASR?
Kapag pumalpak ang ASR, halata agad.
Nakita ko na ang caramelization ay na-transcribe bilang communist Asians. Crispiness naging Chris p — alam mo na ang ibig kong sabihin.
Ang sukatan na ginagamit natin para masukat ang mga pagkakamali ay word error rate (WER). Ang formula ng WER ay:
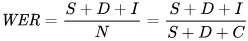
Kung saan:
- S ay bilang ng substitutions (mga salitang pinalitan sa hinulaang teksto para tumugma sa reference text)
- D ay bilang ng deletions (mga salitang nawala sa output, kumpara sa reference text)
- I ay bilang ng insertions (dagdag na mga salita sa output, kumpara sa reference text)
- N ang kabuuang bilang ng mga salita sa reference
Halimbawa, ang reference ay “the cat sat.”
- Kung ang output ng modelo ay “the cat sank”, iyon ay substitution.
- Kung ang output ay “cat sat”, iyon ay deletion.
- Kung “the cat has sat” ang output, iyon ay insertion.
Ano ang mga Gamit ng ASR?
Ang ASR ay isang kapaki-pakinabang na kasangkapan.
Nakatulong din ito upang mapabuti ang kalidad ng ating buhay sa pamamagitan ng mas ligtas, mas madaling ma-access, at mas episyenteng mga industriya.
Pangkalusugan
Kapag sinasabi ko sa mga doktor na nagsasaliksik ako tungkol sa speech recognition, sinasabi nila “ah, parang Dragon.”
Bago nagkaroon ng generative AI sa pangangalagang pangkalusugan, ang mga doktor ay nagtatala ng pasalitang tala sa bilis na 30 salita kada minuto gamit ang limitadong bokabularyo.
Malaki ang naitulong ng ASR sa pagbawas ng matinding pagkapagod na nararanasan ng mga doktor.
Pinagsasabay ng mga doktor ang sandamakmak na papeles at ang pangangailangang asikasuhin ang kanilang mga pasyente. Noong 2018 pa lang, may mga mananaliksik nang nanawagan na gamitin ang digital transcription sa mga konsultasyon para mapabuti ang kakayahan ng mga doktor na magbigay ng pangangalaga.
Ito ay dahil ang pagdodokumento ng konsultasyon pagkatapos ng aktwal na usapan ay hindi lang kumakain ng oras na dapat sana ay para sa pasyente, kundi mas hindi rin ito eksakto kumpara sa buod mula sa aktwal na transcription ng konsultasyon.
Smart Homes
May biro ako tungkol dito.
Kapag gusto kong patayin ang ilaw pero tinatamad akong bumangon, pumapalakpak ako ng dalawang beses nang sunod-sunod—parang may clapper ako.
Hindi kailanman natatawa ang aking kapareha.
Pakiramdam mo, ang mga smart-home na pinapagana ng boses ay parehong makabago at nakakalulong. O parang ganun.
Oo, maginhawa sila, pero sa maraming pagkakataon, nagbibigay sila ng kakayahang gawin ang mga bagay na hindi mo magagawa dati.
Isang magandang halimbawa ay ang paggamit ng enerhiya: mahirap baguhin ang ilaw at thermostat nang madalas sa maghapon kung kailangan mo pang bumangon at mag-adjust ng dial.
Sa voice activation, mas madali nang gawin ang maliliit na pagbabago, at naiintindihan pa nito ang mga pahiwatig sa pananalita ng tao.
Halimbawa, kapag sinabi mong “puwede bang gawing mas malamig ng kaunti?” Gamit ang natural language processing, isinasalin ng assistant ang hiling mo sa pagbabago ng temperatura, isinasaalang-alang ang iba pang datos: kasalukuyang temperatura, taya ng panahon, datos ng paggamit ng thermostat ng ibang tao, atbp.
Gawin mo ang bahagi mong tao, at hayaan mo na sa computer ang mga gawain ng computer.
Mas madali nga naman iyon kaysa hulaan mo kung ilang degree ang dapat ibaba base lang sa pakiramdam mo.
At mas matipid pa ito sa enerhiya: may mga ulat ng mga pamilyang nakabawas ng konsumo ng kuryente ng hanggang 80% gamit ang voice-activated na matalinong ilaw, bilang isang halimbawa.
Suporta sa Kostumer
Napag-usapan na natin ito sa healthcare, pero mas epektibo talaga ang pag-transcribe at pagbuod kaysa sa pagbibigay ng buod ng interaksyon pagkatapos ng aktwal na usapan.
Muli, nakakatipid ito ng oras at mas eksakto. Paulit-ulit nating natutuklasan na ang mga awtomasyon ay nagpapalaya ng oras para mas magampanan ng tao ang kanilang trabaho.
At lalo itong totoo sa customer support, kung saan ang customer support na pinalakas ng ASR ay may 25% mas mataas na first-call resolution rate.
Tinutulungan ng transcription at summarization na gawing awtomatiko ang paghahanap ng solusyon batay sa damdamin at tanong ng customer.
In-Car Assistants
Sumasabay tayo sa mga home assistant dito, pero sulit talagang banggitin.
Binabawasan ng pagkilala sa boses ang pagod sa pag-iisip at mga sagabal sa paningin para sa mga nagmamaneho.
At dahil ang mga sagabal ay nagdudulot ng hanggang 30% ng mga banggaan, ang pagpapatupad ng teknolohiyang ito ay malinaw na hakbang para sa kaligtasan.
Speech Pathology
Matagal nang ginagamit ang ASR bilang kasangkapan sa pagsusuri at paggamot ng mga suliranin sa pagsasalita.
Mahalagang tandaan na hindi lang gawain ang naia-automate ng mga makina, kundi nagagawa rin nila ang mga bagay na hindi kayang gawin ng tao.
Kayang matukoy ng pagkilala sa boses ang mga banayad na pagkakaiba sa pananalita na halos hindi marinig ng tao, kaya nahuhuli ang mga detalye ng apektadong pananalita na madalas hindi napapansin.
Ang Hinaharap ng ASR
Umabot na sa puntong hindi na natin napapansin ang STT dahil sobrang husay na nito.
Pero sa likod ng lahat, puspusang nagtatrabaho ang mga mananaliksik para gawing mas makapangyarihan, mas abot-kaya, at mas hindi halata ang teknolohiya.
Pinili ko ang ilang kapana-panabik na uso na gumagamit ng mga bagong tuklas sa ASR, at nagdagdag ng sarili kong pananaw.
On-Device Speech Recognition
Karamihan ng ASR ay tumatakbo sa cloud. Sigurado akong narinig mo na iyon. Ibig sabihin, ang modelo ay tumatakbo sa isang remote na computer, sa ibang lugar.
Ginagawa nila ito dahil hindi sapat ang maliit na processor ng telepono mo para patakbuhin ang napakalaking model nila, o kaya'y sobrang tagal bago matapos ang transcription.
Sa halip, ipinapadala ang audio mo, gamit ang internet, sa isang remote server na may GPU na sobrang bigat para dalhin sa bulsa. Doon pinapatakbo ang ASR model, at ibinabalik ang transcription sa device mo.
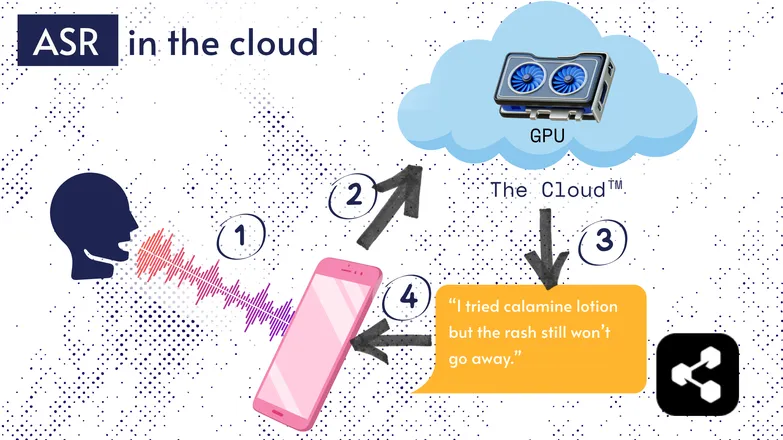
Dahil sa usapin ng pagtitipid ng enerhiya at seguridad (hindi lahat gusto na palutang-lutang ang personal na datos nila sa internet), maraming pananaliksik ang inilaan para gawing compact ang mga modelo para tumakbo mismo sa device mo—telepono man, computer, o browser engine.
Ako mismo ay nagsulat ng tesis tungkol sa pag-quantize ng ASR models para tumakbo ito on-device. Ang Picovoice ay isang kumpanyang Canadian na gumagawa ng low-latency on-device voice AI, at mukhang maganda ang ginagawa nila.
Ginagawang mas abot-kaya ng on-device ASR ang transcription, na may potensyal na makatulong sa mga komunidad na mababa ang kita.
Transcript-First UI
Lumiit na ang agwat ng audio at transcription. Ano ang ibig sabihin nito?
Pinapayagan ka ng mga video editor tulad ng Premiere Pro at Descript na mag-navigate sa recording gamit ang transcript: i-click mo ang salita at dadalhin ka nito sa tamang oras sa video.
Kailangan mong ulitin ng ilang beses? Piliin ang paborito mo at burahin ang iba, parang sa text editor. Kusang inaayos ng sistema ang video para sa iyo.
Nakakainis gawin ang ganitong pag-edit gamit lang ang waveform, pero sobrang dali kapag transcript-based editor ang gamit mo.
Ganon din sa mga messaging service tulad ng WhatsApp—ina-transcribe na nila ang voice notes mo at puwede mong i-scrub ang audio gamit ang text. I-slide mo lang ang daliri mo sa salita, at dadalhin ka nito sa bahaging iyon ng recording.

Nakakatawang kwento: nakagawa ako ng ganito mga isang linggo bago inanunsyo ng Apple ang katulad na tampok.
Ipinapakita ng mga halimbawang ito kung paano nagdadala ng kasimplehan at pagiging intuitive ang mga komplikadong teknolohiya sa likod ng mga end-user na aplikasyon.
Pagkakapantay-pantay, Inklusyon, at Mga Wikang Kulang sa Yaman
Hindi pa tapos ang laban.
Mahusay gumagana ang ASR sa Ingles at iba pang karaniwang wikang may sapat na mapagkukunan. Hindi ito palaging ganito para sa mga wikang kulang sa mapagkukunan.
May kakulangan para sa mga minoridad ng diyalekto, apektadong pananalita, at iba pang isyu sa pagkakapantay-pantay sa teknolohiyang tinig.
Pasensya na kung nabawasan ang saya. Ang bahaging ito ay tinatawag na “hinaharap” ng ASR. At pinipili kong tumingin sa hinaharap na maipagmamalaki natin.
Kung uusad tayo, dapat sabay-sabay, kung hindi ay baka lumaki pa ang hindi pagkakapantay-pantay sa lipunan.
Simulan ang Paggamit ng ASR Ngayon
Anuman ang negosyo mo, ang paggamit ng ASR ay malinaw na desisyon — pero malamang iniisip mo kung paano magsisimula. Paano mo ipapatupad ang ASR? Paano mo ipapasa ang datos sa iba pang mga kasangkapan?
May madaling gamitin na mga transcription card ang Botpress. Maaari itong isama sa drag-and-drop na daloy, at palawakin gamit ang dose-dosenang integrasyon sa iba’t ibang aplikasyon at channel ng komunikasyon.
Simulan ang paggawa ngayon. Libre ito.
FAQs
Gaano katumpak ang makabagong ASR para sa iba’t ibang punto at maingay na kapaligiran?
Ang mga makabagong ASR system ay kahanga-hanga ang katumpakan para sa karaniwang punto sa malalaking wika, na umaabot sa word error rate (WER) na mas mababa sa 10% sa malinis na kondisyon, ngunit bumababa ang katumpakan kapag mabigat ang punto, diyalekto, o malakas ang ingay sa paligid. Ang mga vendor tulad ng Google at Microsoft ay nagsasanay ng mga modelo gamit ang iba’t ibang uri ng pagsasalita, pero nananatiling hamon ang perpektong transkripsyon sa maingay na kapaligiran.
Maaasahan ba ang ASR sa pag-transcribe ng espesyalisadong jargon o mga terminong pang-industriya?
Hindi gaanong maaasahan ang ASR agad-agad para sa espesyalisadong jargon o mga terminong pang-industriya dahil karaniwan ay nakatuon ang training data nito sa pangkalahatang pagsasalita; maaaring mali ang pagkaka-transcribe o hindi maisama ang mga hindi pamilyar na salita. Gayunpaman, pinapayagan ng mga enterprise solution ang custom na bokabularyo, mga domain-specific na language model, at mga diksyunaryo ng bigkas para mapabuti ang pagkilala sa mga teknikal na termino sa larangan ng kalusugan, batas, o inhinyeriya.
Ano ang pinagkaiba ng libreng ASR tools at enterprise-grade na solusyon?
Ang pinagkaiba ng libreng ASR na mga tool at enterprise-grade na mga solusyon ay nasa katumpakan, scalability, customization, at privacy controls: mas mataas ang error rate, limitadong suporta sa wika, at may usage cap ang mga libreng tool, samantalang ang enterprise-grade na mga solusyon ay may mas mababang WER, domain-specific na customization, mga integrasyon, SLA, at matibay na seguridad para sa sensitibong datos.
Paano pinoprotektahan ng ASR ang privacy ng gumagamit at sensitibong impormasyon habang nagta-transcribe?
Pinoprotektahan ng ASR ang privacy ng user sa pamamagitan ng pag-encrypt ng data habang ipinapadala ito at nagbibigay ng mga opsyon tulad ng pagpapatakbo ng modelo mismo sa device para hindi na kailangang ipadala ang speech data sa labas. Maraming enterprise provider din ang sumusunod sa mga regulasyon sa privacy gaya ng GDPR o HIPAA at kayang gawing anonymous ang data para maprotektahan ang sensitibong impormasyon.
Gaano kamahal ang cloud-based na ASR kumpara sa mga solusyong on-device?
Karaniwan, ang mga cloud-based na ASR service ay naniningil kada minuto ng audio o ayon sa usage tier, na may presyo mula $0.03–$1.00+ bawat minuto depende sa katumpakan at mga tampok, habang ang on-device na solusyon ay nangangailangan ng paunang gastos sa pag-develop at bayad sa lisensya.



