



- ASR transforms speech into text using machine learning, enabling voice commands and real-time transcription.
- Modern ASR systems have shifted from separate phoneme models (HMM-GMM) to deep learning models that predict entire words.
- ASR performance is measured by Word Error Rate (WER), with errors coming from substitutions, deletions, or insertions; lower WER = better transcription quality.
- The future of ASR is focused on on-device processing for privacy and support for low-resource languages.
When was the last time you watched something without subtitles?
They used to be optional, but now they bounce across short-form videos whether we want them or not. Captions are so embedded in the content that you forget they’re there.
Automatic speech recognition (ASR) — the ability to quickly and accurately automate the conversion of spoken words into text — is the technology powering this shift.
When we think about an AI voice agent, we think about its word choice, delivery, and the voice it speaks in.
But it’s easy to forget that the fluidity of our interactions relies on the bot understanding us. And reaching this point — the bot understanding you through “um”s and “ah”s in a noisy environment — has been no walk in the park.
Today, we’re going to talk about the technology powering those captions: automatic speech recognition (ASR).
Allow me to introduce myself: I’ve got a master’s in speech technology, and in my spare time, I like to read up on the latest in ASR, and even build stuff.
I’ll explain to you the basics of ASR, peek under the hood at the technology, and take a guess at where the technology might go next.
What is ASR?
Automatic speech recognition (ASR), or speech-to-text (STT) is the process of converting speech into written text through the use of machine learning technology.
Technologies that involve speech often integrate ASR in some capacity; it can be for video captioning, transcribing customer support interactions for analysis, or part of a voice assistant interaction, to name a few.
Speech-to-Text Algorithms
The underlying technologies have changed over the years, but all iterations have consisted of two components in some form or another: data and a model.
In the case of ASR, the data is labeled speech – audio files of spoken language and their corresponding transcriptions.
The model is the algorithm used to predict the transcription from the audio. The labeled data is used to train the model, so that it can generalize across unseen speech examples.
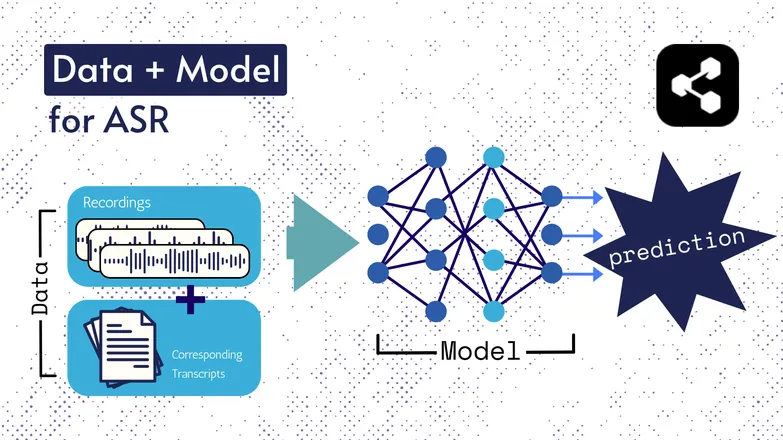
It’s a lot like how you can understand a series of words, even if you’ve never heard them in that particular order, or they’re spoken by a stranger.
Again, the kinds of models and their specifics have changed over time, and all the advances in speed and accuracy have come down to the size and specifications of the datasets and models.
Quick Aside: Feature Extraction
I spoke about features, or representations in my article on text-to-speech. They’re used in ASR models past and present.
Feature extraction — converting speech into features — is the first step in pretty much all ASR pipelines.
The short of it is that these features, often spectrograms, are the result of a mathematical calculation performed on speech, and convert speech into a format that emphasizes similarities across an utterance, and minimizes differences across speakers.
As in, the same utterance spoken by 2 different speakers will have similar spectrograms, regardless of how different their voices are.
I’m pointing this out to let you know that I’ll be speaking about models “predicting transcripts from speech”. That’s not technically true; models are predicting from features. But you can think of the feature extraction component as part of the model.
Early ASR: HMM-GMM
Hidden markov models (HMMs) and Gaussian mixture models (GMMs) are predictive models from before deep neural networks took over.
HMMs dominated ASR up until recently.
Given an audio file, the HMM would predict the duration of a phoneme, and the GMM would predict the phoneme itself.
That sounds backwards, and it kind of is, like:
- HMM: “The first 0.2 seconds is a phoneme.”
- GMM: “That phoneme is a G, as in Gary.”
Turning an audio clip into text would require a few extra components, namely:
- A pronunciation dictionary: an exhaustive list of the words in the vocabulary, with their corresponding pronunciations.
- A language model: Combinations of words in the vocabulary, and their probabilities of co-occurring.
So even if the GMM predicts /f/ over /s/, the language model knows it’s way more likely that the speaker said “a penny for your thoughts”, not foughts.
We had all these parts because, to put it bluntly, no part of this pipeline was exceptionally good.
The HMM would mis-predict alignments, the GMM would mistake similar sounds: /s/ and /f/, /p/ and /t/, and don’t even get me started on vowels.
And then the language model would clean up the mess of incoherent phonemes into something more language-y.
End-to-End ASR with Deep Learning
A lot of the parts of an ASR pipeline have since been consolidated.
Instead of training separate models to handle spelling, alignment, and pronunciation, a single model takes in speech and outputs (hopefully) correctly spelled words, and, nowadays, timestamps as well.
(Although implementations often correct, or “re-score” this output with an additional language model.)
That’s not to say that different factors — like alignment and spelling — don’t get unique attention. There are still mountains of literature focused on implementing fixes to highly targeted issues.
That is, researchers come up with ways to alter a model’s architecture that target specific factors of its performance, like:
- An RNN-Transducer decoder conditioned on previous outputs to improve spelling.
- Convolutional downsampling to limit blank outputs, improving alignment.
I know this is nonsense. I’m just getting ahead of my boss being like “can you give a plain-English example?”
The answer is no.
No I can’t.
How is Performance Measured in ASR?
When ASR does a bad job you know it.
I’ve seen caramelization transcribed as communist Asians. Crispiness to Chris p — you get the idea.
The metric we use to reflect errors mathematically is word error rate (WER). The formula for WER is:
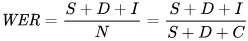
Where:
- S is number of substitutions (words changed in the predicted text in order to match the reference text)
- D is number of deletions (words missing from the output, compared to the reference text)
- I is the number of insertions (additional words in the output, compared to the reference text)
- N is the total number of words in the reference
So, say the reference is “the cat sat.”
- If the model outputs “the cat sank”, that’s a substitution.
- If the model outputs “cat sat”, that’s a deletion.
- If it outputs “the cat has sat”, that’s an insertion.
What are the Applications of ASR?
ASR is a nifty tool.
It’s also helped us improve our quality of life through improved safety, accessibility, and efficiency in crucial industries.
Healthcare
When I tell doctors that I research speech recognition, they go “oh, like Dragon.”
Before we had generative AI in healthcare, doctors were taking verbal notes at 30-words-per-minute with a limited vocabulary.
ASR has been massively successful at curbing the widespread burnout doctors experience.
Physicians balance mountains of paperwork with the need to attend to their patients. As early as 2018, researchers were pleading for the use of digital transcription in consultations to improve doctors’ ability to provide care.
That’s because having to document consultations retroactively not only takes away from face-time with patients, but it’s also much less accurate than summarizations of transcriptions of actual consultations.
Smart Homes
I have this joke I do.
When I want to turn the lights off but I don’t feel like getting up, I clap twice in quick succession — as if I had a clapper.
My partner never laughs.
Voice-activated smart-homes feel both futuristic and shamefully indulgent. Or so it seems.
Sure, they’re convenient, but in many cases they make it possible to do things that are otherwise not available.
A great example is energy consumption: making minor tweaks to lighting and thermostat would be infeasible throughout the day if you had to get up and toy around with a dial.
Voice activation means those minor tweaks are not only easier to make, but it reads the nuance of human speech.
For example, you say “can you make it a touch cooler?” The assistant uses natural language processing to translate your request into a change in temperature, factoring in a whole slew of other data: the current temperature, the weather forecast, other users’ thermostat usage data, etc.
You do the human part, and leave the computer-y stuff to the computer.
I’d argue that’s way easier than you having to guess how many degrees to turn the heat down based on your feeling.
And it’s more energy efficient: there are reports of families reducing energy consumption by 80% with voice-activated smart lighting, to give one example.
Customer Support
We talked about this with healthcare, but transcribing-and-summarizing is much more effective than people giving retroactive summaries of interactions.
Again, it saves time and it’s more accurate. What we learn time and time again is that automations free up time for people to do their jobs better.
And nowhere is that more true than in customer support, where ASR-boosted customer support has a 25% higher first-call resolution rate.
Transcription and summarization helps automate the process of figuring out a solution based on a customer’s sentiment and query.
In-Car Assistants
We’re piggybacking off the home assistants here, but it’s well worth a mention.
Voice recognition reduces cognitive load and visual distractions for drivers.
And with distractions accounting for up to 30% of collisions, implementing the technology is a safety no-brainer.
Speech Pathology
ASR has long been used as a tool in assessing and treating speech pathologies.
It’s helpful to remember that machines don’t only automate tasks, they do things that humans can’t.
Speech recognition can detect subtleties in speech that are nearly imperceptible to the human ear, catching specifics of affected speech that would otherwise fly under the radar.
The Future of ASR
STT has gotten good enough that we don’t think about it anymore.
But behind the scenes, researchers are hard at work making it even more powerful and accessible — and less noticeable.
I picked some exciting trends that leverage advancements in ASR, and sprinkled in some of my own thoughts.
On-Device Speech Recognition
Most ASR solutions run in the cloud. I’m sure you’ve heard that before. That means the model runs on a remote computer, somewhere else.
They do this because your phone’s little processor can’t necessarily run their huge model, or it would take forever to transcribe anything.
Instead, your audio is sent, via the internet, to a remote server running a GPU way too heavy to carry around in your pocket. The GPU runs the ASR model, and returns the transcription to your device.
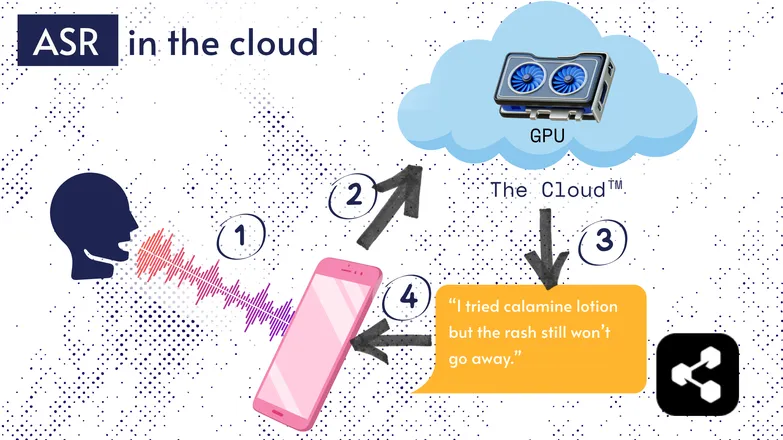
For reasons of energy efficiency and security (not everyone wants their personal data floating around cyberspace), lots of research has been poured into making models compact enough to run directly on your device, be it a phone, computer, or a browser engine.
Yours truly wrote a thesis on quantizing ASR models so they can run on-device. Picovoice is a Canadian company building low-latency on-device voice AI, and they seem cool.
On-device ASR makes transcription available at a lower cost, with the potential to service low-income communities.
Transcript-First UI
The gap between audio and transcriptions is shrinking. What does that mean?
Video editors like Premiere Pro and Descript let you navigate your recordings through a transcript: click on a word and it brings you to the timestamp.
Had to do a few takes? Pick your favorite and erase the others, text-editor style. It automatically trims up the video for you.
It’s mighty frustrating to do that sort of editing with just a waveform, but stupid easy when you have transcript-based editors.
Similarly, messaging services like WhatsApp are transcribing your voice notes and letting you scrub through them via the text. Slide your finger over a word, and you’re taken to that part of the recording.

Funny story: I actually built something like this about a week before Apple announced a similar feature.
These examples show how complex under-the-hood technologies bring simplicity and intuitiveness to end-user applications.
Equity, Inclusion, and Low-Resource Languages
The battle’s not yet won.
ASR works great in English, and other common, well-resourced languages. That’s not necessarily the case for low-resource languages.
There’s a gap in dialectal minorities, affected speech, and other issues with equity in voice technology.
Sorry to hamper the good vibes. This section’s called the “future” of ASR. And I choose to look forward to a future we can be proud of.
If we’re going to advance, we ought to do it together, or risk increasing societal inequality.
Start Using ASR Today
No matter your business, using ASR is a no-brainer — except you’re probably wondering how to get started. How do you implement ASR? How do you pass that data on to other tools?
Botpress comes with easy-to-use transcription cards. They can be integrated into a drag-and-drop flow, augmented with dozens of integrations across applications and communication channels.
Start building today. It’s free.
FAQs
How accurate is modern ASR for different accents and noisy environments?
Modern ASR systems are impressively accurate for common accents in major languages, achieving word error rates (WER) under 10% in clean conditions, but accuracy drops noticeably with heavy accents, dialects, or significant background noise. Vendors like Google and Microsoft train models on diverse speech data, but perfect transcription in noisy environments still remains a challenge.
Is ASR reliable for transcribing specialized jargon or industry-specific terms?
ASR is less reliable out-of-the-box for specialized jargon or industry-specific terms because its training data usually skews toward general speech; unfamiliar words can be mistranscribed or omitted. However, enterprise solutions allow custom vocabularies, domain-specific language models, and pronunciation dictionaries to improve recognition of technical terms in fields like healthcare, law, or engineering.
What’s the difference between free ASR tools and enterprise-grade solutions?
The difference between free ASR tools and enterprise-grade solutions lies in accuracy, scalability, customization, and privacy controls: free tools often have higher error rates, limited language support, and usage caps, while enterprise solutions offer lower WER, domain-specific customization, integrations, service-level agreements (SLAs), and robust security features for handling sensitive data.
How does ASR protect user privacy and sensitive information during transcription?
ASR protects user privacy through encryption during data transmission and offers options like running models on-device to avoid sending speech data to external servers. Many enterprise providers also comply with privacy regulations such as GDPR or HIPAA and can anonymize data to safeguard sensitive information.
How expensive are cloud-based ASR services versus on-device solutions?
Cloud-based ASR services typically charge per audio minute or by usage tiers, with costs ranging from $0.03–$1.00+ per minute depending on accuracy and features, while on-device solutions involve upfront development costs and licensing fees.



