



- ASR wandelt Sprache mithilfe von maschinellem Lernen in Text um und ermöglicht so Sprachbefehle und Echtzeit-Transkriptionen.
- Moderne ASR-Systeme haben sich von getrennten Phonem-Modellen (HMM-GMM) hin zu Deep-Learning-Modellen entwickelt, die ganze Wörter vorhersagen.
- Die Leistung von ASR wird anhand der Wortfehlerrate (WER) gemessen. Fehler entstehen durch Ersetzungen, Auslassungen oder Einfügungen; eine niedrigere WER bedeutet eine bessere Transkriptionsqualität.
- Die Zukunft von ASR liegt im geräteinternen Verarbeiten zum Schutz der Privatsphäre und in der Unterstützung von Sprachen mit wenig Ressourcen.
Wann hast du zuletzt etwas ohne Untertitel gesehen?
Früher waren sie optional, heute laufen sie über Kurzvideos, ob wir wollen oder nicht. Untertitel sind so fest im Inhalt verankert, dass man sie kaum noch wahrnimmt.
Automatische Spracherkennung (ASR) – die Fähigkeit, gesprochene Worte schnell und präzise automatisch in Text umzuwandeln – ist die Technologie, die diesen Wandel ermöglicht.
Wenn wir an einen KI-Sprachagenten denken, denken wir an seine Wortwahl, die Art, wie er spricht, und seine Stimme.
Dabei vergisst man leicht, dass die Qualität unserer Interaktion davon abhängt, wie gut der Bot uns versteht. Und bis zu dem Punkt zu kommen, an dem der Bot dich trotz „Ähm“ und „Öh“ in lauter Umgebung versteht, war alles andere als einfach.
Heute sprechen wir über die Technologie hinter diesen Untertiteln: automatische Spracherkennung (ASR).
Kurz zu mir: Ich habe einen Master in Sprachtechnologie und lese in meiner Freizeit gerne über die neuesten Entwicklungen in der ASR – und baue auch selbst Dinge.
Ich erkläre dir die Grundlagen von ASR, gebe einen Einblick in die Technik dahinter und wage einen Ausblick, wohin sich die Technologie entwickeln könnte.
Was ist ASR?
Automatische Spracherkennung (ASR), auch Speech-to-Text (STT) genannt, ist der Prozess, gesprochene Sprache mithilfe von maschinellem Lernen in geschriebenen Text umzuwandeln.
Technologien, die Sprache nutzen, integrieren ASR oft auf irgendeine Weise: zum Beispiel für Video-Untertitel, die Transkription von Kundengesprächen zur Analyse oder als Teil einer Sprachassistenten-Interaktion, um nur einige zu nennen.
Speech-to-Text-Algorithmen
Die zugrundeliegenden Technologien haben sich im Laufe der Jahre verändert, aber alle Varianten bestehen im Grunde aus zwei Komponenten: Daten und einem Modell.
Im Fall von ASR sind die Daten gelabelte Sprachaufnahmen – also Audiodateien mit gesprochener Sprache und den dazugehörigen Transkriptionen.
Das Modell ist der Algorithmus, der aus dem Audio die Transkription vorhersagt. Die gelabelten Daten dienen dazu, das Modell zu trainieren, damit es auch unbekannte Sprachbeispiele verarbeiten kann.
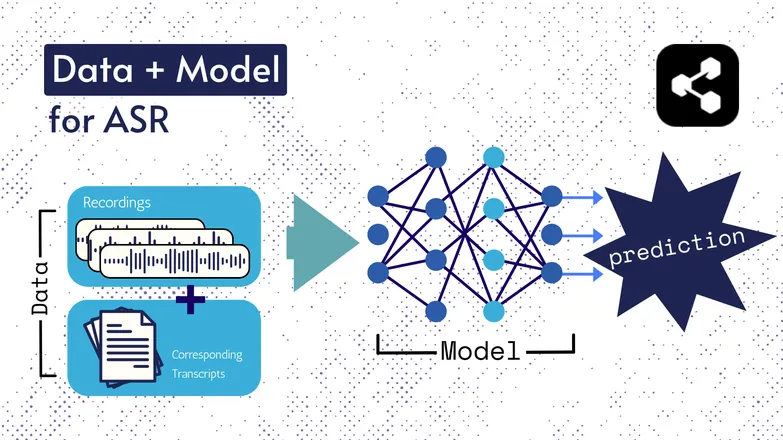
Es ist ein bisschen so, wie wenn du eine Reihe von Wörtern verstehst, auch wenn du sie noch nie in genau dieser Reihenfolge gehört hast oder sie von jemand Fremdem gesprochen werden.
Auch hier haben sich die Modellarten und ihre Details im Laufe der Zeit verändert, und alle Fortschritte bei Geschwindigkeit und Genauigkeit hängen von der Größe und Qualität der Datensätze und Modelle ab.
Kurz erklärt: Merkmalsextraktion
Ich habe in meinem Artikel über Text-to-Speech über Features bzw. Repräsentationen gesprochen. Sie werden in ASR-Modellen – früher wie heute – verwendet.
Merkmalsextraktion – also das Umwandeln von Sprache in Merkmale – ist der erste Schritt in praktisch jeder ASR-Pipeline.
Kurz gesagt: Diese Merkmale, oft Spektrogramme, entstehen durch eine mathematische Berechnung der Sprache und wandeln Sprache in ein Format um, das Ähnlichkeiten innerhalb einer Äußerung betont und Unterschiede zwischen Sprechern minimiert.
Das heißt: Die gleiche Äußerung, von zwei verschiedenen Personen gesprochen, ergibt ähnliche Spektrogramme – egal, wie unterschiedlich ihre Stimmen sind.
Ich erwähne das, weil ich gleich von Modellen spreche, die „Transkripte aus Sprache vorhersagen“. Das stimmt technisch nicht ganz; die Modelle sagen Transkripte aus Merkmalen voraus. Aber man kann die Merkmalsextraktion als Teil des Modells betrachten.
Frühe ASR: HMM-GMM
Hidden Markov Modelle (HMMs) und Gaussian Mixture Models (GMMs) sind Vorhersagemodelle aus der Zeit, bevor tiefe neuronale Netze den Bereich übernommen haben.
HMMs dominierten die ASR bis vor kurzem.
Bei einer Audiodatei sagte das HMM die Dauer eines Phonems voraus, das GMM das Phonem selbst.
Das klingt irgendwie verdreht, und das ist es auch, etwa so:
- HMM: „Die ersten 0,2 Sekunden sind ein Phonem.“
- GMM: „Dieses Phonem ist ein G, wie in Gary.“
Um einen Audioclip in Text umzuwandeln, brauchte es noch ein paar weitere Komponenten, nämlich:
- Ein Aussprachewörterbuch: eine vollständige Liste aller Wörter im Vokabular mit den jeweiligen Aussprachen.
- Ein Sprachmodell: Kombinationen von Wörtern im Vokabular und deren Wahrscheinlichkeiten, gemeinsam aufzutreten.
Selbst wenn das GMM /f/ statt /s/ vorhersagt, weiß das Sprachmodell, dass „a penny for your thoughts“ viel wahrscheinlicher ist als foughts.
Wir hatten all diese Teile, weil – um es direkt zu sagen – kein Teil dieser Pipeline wirklich herausragend war.
Das HMM lag oft bei der Ausrichtung daneben, das GMM verwechselte ähnliche Laute wie /s/ und /f/, /p/ und /t/ – und über Vokale will ich gar nicht erst anfangen.
Und dann musste das Sprachmodell das Chaos aus unzusammenhängenden Phonemen in etwas Sprachähnliches verwandeln.
End-to-End-ASR mit Deep Learning
Viele Teile der ASR-Pipeline wurden inzwischen zusammengeführt.
Statt einzelne Modelle für Rechtschreibung, Ausrichtung und Aussprache zu trainieren, übernimmt heute ein einziges Modell die Spracheingabe und gibt (hoffentlich) korrekt geschriebene Wörter und mittlerweile auch Zeitstempel aus.
(In der Praxis wird dieses Ergebnis oft noch mit einem zusätzlichen Sprachmodell korrigiert oder „neu bewertet“.)
Das heißt aber nicht, dass Faktoren wie Ausrichtung und Rechtschreibung keine eigene Aufmerksamkeit bekommen. Es gibt immer noch unzählige Forschungsarbeiten zu gezielten Verbesserungen.
Das heißt, Forscher entwickeln Methoden, um gezielt bestimmte Aspekte der Modellleistung zu optimieren, zum Beispiel:
- Ein RNN-Transducer-Decoder, der auf vorherigen Ausgaben basiert, um die Rechtschreibung zu verbessern.
- Konvolutionales Downsampling, um leere Ausgaben zu reduzieren und die Ausrichtung zu verbessern.
Ich weiß, das klingt alles nach Kauderwelsch. Ich komme nur meiner Chefin zuvor, die fragt: „Kannst du ein einfaches Beispiel geben?“
Die Antwort ist nein.
Nein, kann ich nicht.
Wie wird die Leistung von ASR gemessen?
Wenn ASR schlecht funktioniert, merkt man das sofort.
Ich habe schon gesehen, wie Karamellisierung als kommunistische Asiaten transkribiert wurde. Knusprigkeit zu Chris p — du weißt, was ich meine.
Die Kennzahl, mit der wir Fehler mathematisch abbilden, ist die Wortfehlerrate (WER). Die Formel für WER lautet:
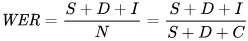
Dabei gilt:
- S ist die Anzahl der Ersetzungen (Wörter, die im vorhergesagten Text geändert werden müssen, um dem Referenztext zu entsprechen)
- D ist die Anzahl der Auslassungen (Wörter, die im Ergebnis fehlen, verglichen mit dem Referenztext)
- I ist die Anzahl der Einfügungen (zusätzliche Wörter im Ergebnis, verglichen mit dem Referenztext)
- N ist die Gesamtzahl der Wörter im Referenztext
Angenommen, der Referenztext ist „the cat sat.“
- Wenn das Modell „the cat sank“ ausgibt, ist das eine Ersetzung.
- Wenn das Modell „cat sat“ ausgibt, ist das eine Auslassung.
- Wenn es „the cat has sat“ ausgibt, ist das eine Einfügung.
Wofür wird ASR eingesetzt?
ASR ist ein praktisches Werkzeug.
Es hat auch unsere Lebensqualität verbessert – durch mehr Sicherheit, Barrierefreiheit und Effizienz in wichtigen Branchen.
Gesundheitswesen
Wenn ich Ärzten erzähle, dass ich zu Spracherkennung forsche, sagen sie: „Ach, wie Dragon.“
Bevor es generative KI im Gesundheitswesen gab, machten Ärzte verbale Notizen mit 30 Wörtern pro Minute und einem begrenzten Wortschatz.
ASR hat maßgeblich dazu beigetragen, das weitverbreitete Burnout-Problem bei Ärzten einzudämmen.
Ärzte jonglieren mit Bergen von Papierkram und müssen gleichzeitig für ihre Patienten da sein. Schon 2018 forschten Wissenschaftler und forderten den Einsatz digitaler Transkription in Sprechstunden, um die Versorgungsqualität zu verbessern.
Denn wenn Konsultationen nachträglich dokumentiert werden müssen, geht nicht nur Zeit mit den Patienten verloren – die Genauigkeit leidet auch im Vergleich zu Zusammenfassungen echter Transkriptionen.
Smart Homes
Ich habe da so einen Witz.
Wenn ich das Licht ausschalten will, aber keine Lust habe aufzustehen, klatsche ich zweimal schnell hintereinander – als hätte ich einen Klatschsensor.
Mein Partner lacht nie.
Sprachgesteuerte Smart Homes wirken futuristisch und gleichzeitig irgendwie übertrieben. Oder zumindest fühlt es sich so an.
Klar, sie sind praktisch, aber oft ermöglichen sie Dinge, die sonst gar nicht möglich wären.
Ein gutes Beispiel ist der Energieverbrauch: Kleine Anpassungen bei Licht oder Thermostat wären tagsüber kaum machbar, wenn man jedes Mal aufstehen und am Regler drehen müsste.
Mit Sprachsteuerung sind solche Anpassungen nicht nur einfacher, sondern das System versteht auch die Feinheiten menschlicher Sprache.
Zum Beispiel: Man sagt „Kannst du es ein bisschen kühler machen?“ Die Assistenz nutzt Natural Language Processing, um die Anfrage in eine Temperaturänderung umzusetzen – und bezieht dabei viele weitere Daten ein: aktuelle Temperatur, Wettervorhersage, Nutzungsdaten anderer, usw.
Du übernimmst den menschlichen Part, den Rest erledigt der Computer.
Das ist meiner Meinung nach viel einfacher, als selbst zu raten, wie viele Grad man runterdrehen sollte.
Und es ist zudem energieeffizienter: Es gibt Berichte von Familien, die mit sprachgesteuerter, intelligenter Beleuchtung ihren Energieverbrauch um 80 % senken konnten – nur um ein Beispiel zu nennen.
Kundensupport
Wie schon beim Gesundheitswesen besprochen: Transkribieren und Zusammenfassen ist viel effektiver, als wenn Menschen nachträglich Interaktionen zusammenfassen.
Es spart Zeit und ist genauer. Immer wieder zeigt sich: Automatisierung verschafft Menschen Freiraum, ihre Arbeit besser zu machen.
Und nirgendwo trifft das mehr zu als im Kundensupport, wo durch ASR-gestützten Support eine um 25 % höhere Erstlösungsquote erreicht wird.
Transkription und Zusammenfassung helfen dabei, Lösungen automatisch zu finden – basierend auf Stimmung und Anliegen des Kunden.
In-Car Assistants
Wir knüpfen hier an die Home-Assistenten an, aber das verdient eine eigene Erwähnung.
Spracherkennung reduziert die kognitive Belastung und visuelle Ablenkung für Fahrer.
Da Ablenkungen für bis zu 30 % der Unfälle verantwortlich sind, ist der Einsatz dieser Technologie ein klarer Schritt für mehr Sicherheit.
Sprachpathologie
ASR wird seit Langem als Werkzeug zur Diagnose und Behandlung von Sprachstörungen eingesetzt.
Man sollte sich bewusst machen: Maschinen automatisieren nicht nur Aufgaben, sie können auch Dinge, die Menschen nicht können.
Spracherkennung erkennt Feinheiten, die für das menschliche Ohr kaum wahrnehmbar sind, und entdeckt Details in beeinträchtigter Sprache, die sonst unbemerkt bleiben würden.
Die Zukunft von ASR
STT ist inzwischen so gut, dass wir kaum noch darüber nachdenken.
Doch im Hintergrund arbeiten Forscher daran, die Technologie noch leistungsfähiger, zugänglicher – und unauffälliger – zu machen.
Ich habe ein paar spannende Trends herausgegriffen, die auf ASR-Fortschritten aufbauen, und meine eigenen Gedanken dazu ergänzt.
On-Device-Spracherkennung
Die meisten ASR-Lösungen laufen in der Cloud. Das hast du bestimmt schon gehört. Das heißt, das Modell läuft auf einem entfernten Computer, irgendwo anders.
Das liegt daran, dass der kleine Prozessor deines Handys das große Modell meist nicht ausführen kann – oder es würde ewig dauern, etwas zu transkribieren.
Stattdessen wird dein Audio über das Internet an einen entfernten Server geschickt, der eine GPU nutzt, die viel zu groß für die Hosentasche ist. Die GPU führt das ASR-Modell aus und schickt die Transkription zurück an dein Gerät.
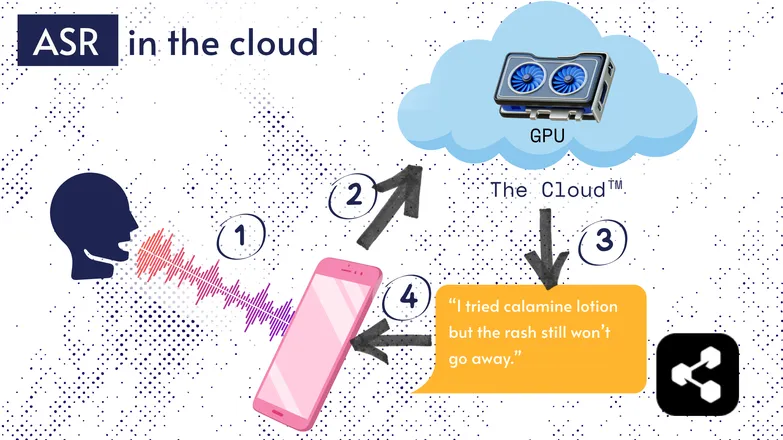
Aus Gründen der Energieeffizienz und Sicherheit (nicht jeder möchte, dass persönliche Daten durchs Netz schwirren) wird intensiv daran geforscht, Modelle so kompakt zu machen, dass sie direkt auf deinem Gerät laufen können – egal ob Handy, Computer oder Browser.
Ich selbst habe eine Abschlussarbeit über Quantisierung von ASR-Modellen geschrieben, damit sie auf dem Gerät laufen. Picovoice ist ein kanadisches Unternehmen, das latenzarme On-Device-Sprach-KI entwickelt – sehr spannend.
On-Device-ASR macht Transkription günstiger und kann auch einkommensschwache Gruppen erreichen.
Transcript-First-Benutzeroberfläche
Die Lücke zwischen Audio und Transkription wird kleiner. Was heißt das?
Videoeditoren wie Premiere Pro und Descript ermöglichen es, Aufnahmen über das Transkript zu navigieren: Klickt man auf ein Wort, springt man zur passenden Stelle im Video.
Mehrere Anläufe gebraucht? Wählen Sie Ihren Favoriten aus und löschen Sie die anderen – wie in einem Texteditor. Das Video wird dabei automatisch für Sie zugeschnitten.
Solches Editieren ist mit einer reinen Wellenform ziemlich mühsam, aber mit transkriptbasierten Editoren kinderleicht.
Ähnlich transkribieren Messenger wie WhatsApp deine Sprachnachrichten und lassen dich per Text darin navigieren. Streicht man über ein Wort, springt man zur entsprechenden Stelle in der Aufnahme.

Lustige Geschichte: Ich habe tatsächlich so etwas gebaut, etwa eine Woche bevor Apple eine ähnliche Funktion angekündigt hat.
Diese Beispiele zeigen, wie komplexe Technologien im Hintergrund für einfache und intuitive Nutzererfahrungen sorgen.
Gleichberechtigung, Inklusion und wenig verbreitete Sprachen
Der Kampf ist noch nicht gewonnen.
ASR funktioniert hervorragend für Englisch und andere weit verbreitete Sprachen. Für wenig verbreitete Sprachen gilt das nicht unbedingt.
Es gibt Lücken bei Dialekten, beeinträchtigter Sprache und anderen Aspekten der Gleichberechtigung in der Sprachtechnologie.
Sorry, dass ich die Stimmung trübe. Dieser Abschnitt heißt „Zukunft“ von ASR. Und ich entscheide mich, einer Zukunft entgegenzusehen, auf die wir stolz sein können.
Wenn wir Fortschritte machen wollen, sollten wir das gemeinsam tun – sonst riskieren wir, gesellschaftliche Ungleichheiten zu verstärken.
Beginne noch heute mit ASR
Ganz gleich, in welcher Branche Sie tätig sind: Der Einsatz von ASR ist ein klarer Vorteil – aber vermutlich fragen Sie sich, wie Sie anfangen. Wie implementiert man ASR? Wie gibt man die Daten an andere Tools weiter?
Botpress bietet einfach zu nutzende Transkriptionskarten. Sie lassen sich per Drag-and-Drop in Flows integrieren und mit zahlreichen Anwendungen und Kommunikationskanälen verbinden.
Jetzt loslegen. Kostenlos.
FAQs
Wie genau ist moderne ASR bei verschiedenen Akzenten und in lauten Umgebungen?
Moderne ASR-Systeme sind für gängige Akzente in den wichtigsten Sprachen beeindruckend präzise und erreichen in ruhigen Umgebungen Wortfehlerraten (WER) von unter 10 %. Bei starken Akzenten, Dialekten oder viel Hintergrundlärm sinkt die Genauigkeit jedoch spürbar. Anbieter wie Google und Microsoft trainieren ihre Modelle mit vielfältigen Sprachdaten, aber eine perfekte Transkription in lauten Umgebungen bleibt weiterhin eine Herausforderung.
Ist ASR zuverlässig bei der Transkription von Fachjargon oder branchenspezifischen Begriffen?
ASR ist für Fachjargon oder branchenspezifische Begriffe weniger zuverlässig, da das Trainingsmaterial meist auf allgemeine Sprache ausgerichtet ist; unbekannte Wörter werden oft falsch erkannt oder ausgelassen. Unternehmenslösungen bieten jedoch die Möglichkeit, eigene Vokabulare, domänenspezifische Sprachmodelle und Aussprachewörterbücher zu integrieren, um die Erkennung technischer Begriffe etwa im Gesundheitswesen, in der Rechtsbranche oder im Ingenieurwesen zu verbessern.
Was ist der Unterschied zwischen kostenlosen ASR-Tools und Enterprise-Lösungen?
Der Unterschied zwischen kostenlosen ASR-Tools und Enterprise-Lösungen liegt in Genauigkeit, Skalierbarkeit, Anpassbarkeit und Datenschutz: Kostenlose Tools haben oft höhere Fehlerraten, unterstützen weniger Sprachen und sind in der Nutzung eingeschränkt, während Enterprise-Lösungen niedrigere WER, domänenspezifische Anpassungen, Integrationen, Service-Level-Agreements (SLAs) und umfassende Sicherheitsfunktionen für sensible Daten bieten.
Wie schützt ASR die Privatsphäre der Nutzer und sensible Informationen während der Transkription?
ASR schützt die Privatsphäre der Nutzer durch Verschlüsselung während der Datenübertragung und bietet Optionen wie die Ausführung von Modellen direkt auf dem Gerät, sodass Sprachdaten nicht an externe Server gesendet werden müssen. Viele Anbieter für Unternehmen erfüllen zudem Datenschutzvorgaben wie die DSGVO oder HIPAA und können Daten anonymisieren, um sensible Informationen zu schützen.
Wie teuer sind cloudbasierte ASR-Dienste im Vergleich zu On-Device-Lösungen?
Cloudbasierte ASR-Dienste rechnen in der Regel pro Audiominute oder nach Nutzungspaketen ab, mit Kosten von 0,03–1,00 $ (oder mehr) pro Minute – je nach Genauigkeit und Funktionsumfang. Bei On-Device-Lösungen fallen hingegen einmalige Entwicklungskosten und Lizenzgebühren an.



