



- ASRは機械学習を使って音声をテキストに変換し、音声コマンドやリアルタイムの文字起こしを可能にします。
- 最新のASRシステムは、個別の音素モデル(HMM-GMM)から、単語全体を予測するディープラーニングモデルへと進化しました。
- ASRの性能は単語誤り率(WER)で評価され、誤りは置換・削除・挿入から発生します。WERが低いほど文字起こしの品質が高くなります。
- ASRの今後は、プライバシーのための端末内処理や、リソースの少ない言語への対応が重視されています。
最後に字幕なしで何かを見たのはいつですか?
以前は字幕はオプションでしたが、今では短い動画にも当たり前のように表示されます。字幕がコンテンツに溶け込みすぎて、存在を忘れてしまうほどです。
自動音声認識(ASR)――話された言葉を素早く正確に自動でテキスト化する能力――が、この変化を支える技術です。
AI音声エージェントについて考えるとき、私たちはその言葉選びや話し方、声の特徴を思い浮かべます。
しかし、私たちのやりとりがスムーズに進むのは、ボットが私たちの言葉を理解できるからこそです。そして、「えー」や「あー」といった言葉や騒がしい環境でもボットが理解できるようになるまでには、多くの苦労がありました。
今回は、字幕を支える技術――自動音声認識(ASR)についてお話しします。
自己紹介をさせてください。私は音声技術の修士号を持ち、余暇にはASRの最新情報を調べたり、ものづくりをしたりしています。
ASRの基本を説明し、その技術の仕組みを少し掘り下げ、今後どこへ向かうのかも予想してみます。
ASRとは?
自動音声認識(ASR)または音声からテキストへの変換(STT)は、機械学習技術を使って音声をテキストに変換するプロセスです。
音声を扱う技術の多くは、何らかの形でASRを組み込んでいます。例えば、動画の字幕生成、カスタマーサポートの会話の文字起こしと分析、音声アシスタントとのやりとりなどです。
音声からテキストへのアルゴリズム
基盤となる技術は時代とともに変化してきましたが、どの方式にも必ずデータとモデルという2つの要素が存在します。
ASRの場合、データはラベル付き音声――話された言語の音声ファイルと、それに対応する文字起こしです。
モデルは、音声から文字起こしを予測するアルゴリズムです。ラベル付きデータを使ってモデルを学習させることで、未知の音声にも対応できるようになります。
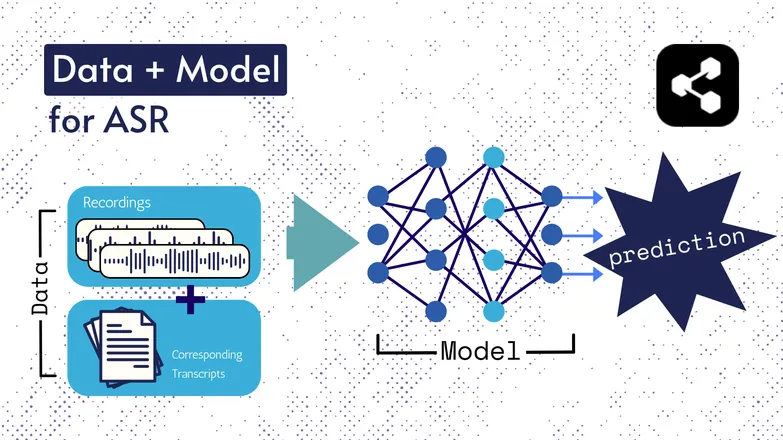
これは、あなたが初めて聞く単語の並びや、知らない人の声でも意味を理解できるのと似ています。
繰り返しになりますが、モデルの種類や詳細は時代とともに変化してきました。速度や精度の向上は、データセットやモデルの規模・仕様によるものです。
ちょっと補足:特徴量抽出
特徴量や表現については、私のテキスト読み上げの記事でも触れました。これらは過去も現在もASRモデルで使われています。
特徴量抽出――音声を特徴量に変換すること――は、ほぼすべてのASRパイプラインの最初のステップです。
簡単に言うと、これらの特徴量は多くの場合スペクトログラムであり、音声に対して数学的な計算を行った結果です。発話内の共通点を強調し、話者ごとの差異を最小限に抑える形式に音声を変換します。
つまり、2人の異なる話者が同じ発話をしても、声がどれほど違ってもスペクトログラムは似たものになります。
ここで強調したいのは、今後「モデルが音声から文字起こしを予測する」と表現しますが、厳密には特徴量から予測しています。ですが、特徴量抽出もモデルの一部と考えて問題ありません。
初期のASR:HMM-GMM
隠れマルコフモデル(HMM)とガウス混合モデル(GMM)は、ディープニューラルネットワークが主流になる前の予測モデルです。
HMMは最近までASRの主流でした。
音声ファイルが与えられると、HMMは音素の継続時間を予測し、GMMはその音素自体を予測します。
少し逆のように聞こえますが、実際その通りで、例えば:
- HMM:「最初の0.2秒は1つの音素です。」
- GMM:「その音素はG、つまりGaryのGです。」
音声クリップをテキストに変換するには、さらにいくつかの要素が必要でした。
- 発音辞書:語彙内のすべての単語と、それぞれの発音を網羅したリスト。
- 言語モデル:語彙内の単語の組み合わせと、それらが一緒に現れる確率。
たとえば、GMMが/f/を/s/よりも予測したとしても、言語モデルは「a penny for your thoughts」と言う方がfoughtsよりもはるかに一般的だと判断します。
これらの要素が必要だったのは、率直に言えば、このパイプラインのどの部分も特別優れていたわけではなかったからです。
HMMはタイミングを間違え、GMMは似た音を混同します:/s/と/f/、/p/と/t/、母音については言うまでもありません。
そして言語モデルが、不明瞭な音素の羅列を、より言語らしいものに整えていました。
ディープラーニングによるエンドツーエンドASR
ASRパイプラインの多くの要素は、現在では統合されています。
スペル、タイミング、発音を個別のモデルで処理するのではなく、1つのモデルが音声を入力し、(うまくいけば)正しく綴られた単語と、最近ではタイムスタンプも出力します。
(ただし、実際には追加の言語モデルでこの出力を修正、または「再スコア」することも多いです。)
だからといって、タイミングやスペルなどの要素が個別に重視されなくなったわけではありません。特定の課題に対処するための研究は今も膨大に存在します。
つまり、研究者たちはモデルの構造を工夫し、性能の特定要素を改善する方法を考案しています。例えば:
- スペルを改善するため、前の出力に基づいて動作するRNN-Transducerデコーダ。
- 空白出力を減らし、タイミングを改善するための畳み込みダウンサンプリング。
意味が分からないと思いますが、上司に「分かりやすい例を出して」と言われる前に言っておきます。
答えはノーです。
できません。
ASRの性能はどう評価する?
ASRの精度が悪いと、すぐに分かります。
caramelizationがcommunist Asiansと文字起こしされたのを見たことがあります。CrispinessがChris p —になったり……もうお分かりですよね。
誤りを数値で表す指標として使われるのが、単語誤り率(WER)です。WERの計算式は次の通りです。
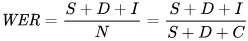
各項目の意味:
- Sは置換の数(予測テキストを参照テキストに合わせるために変更された単語数)
- Dは削除の数(参照テキストに比べて出力から抜けている単語数)
- Iは挿入の数(参照テキストに比べて出力に余分に含まれる単語数)
- Nは参照テキストの単語総数
例えば、参照テキストが「the cat sat.」の場合、
- モデルの出力が「the cat sank」なら、これは置換です。
- 「cat sat」なら、これは削除です。
- 「the cat has sat」なら、これは挿入です。
ASRの用途は?
ASRはとても便利なツールです。
また、重要な産業分野で安全性・アクセシビリティ・効率の向上を通じて、私たちの生活の質を高めてきました。
医療
私が医師に音声認識の研究をしていると言うと、「ああ、Dragonみたいなやつね」と返されます。
医療分野での生成AIが登場する前は、医師たちは限られた語彙で1分間に30語程度の口述メモを取っていました。
ASR(自動音声認識)は、医師が広く経験する燃え尽き症候群の抑制に大きく貢献しています。
医師は膨大な書類作業と患者対応の両立を求められます。2018年の時点で、研究者たちは診察時のデジタル文字起こしの活用を訴えており、医師がより良いケアを提供できるようにしようとしていました。
これは、診察内容を後から記録する作業が患者との対面時間を減らすだけでなく、実際の診察内容を文字起こしして要約したものよりも正確性が劣るためです。
スマートホーム
私にはよくやる冗談があります。
電気を消したいけど立ち上がるのが面倒なとき、私は素早く2回手を叩きます——まるでクラッパーがあるかのように。
パートナーは一度も笑いません。
音声操作のスマートホームは未来的でありながら、どこか贅沢すぎる気もします。そんな印象です。
確かに便利ですが、多くの場合、これまでできなかったことを可能にしてくれます。
良い例がエネルギー消費です。照明やサーモスタットの微調整を1日中何度も行うのは、毎回立ち上がってダイヤルをいじる必要があれば現実的ではありません。
音声操作なら、こうした細かな調整が簡単になるだけでなく、人間の話し方のニュアンスも読み取ってくれます。
たとえば「もう少し涼しくして」と言えば、アシスタントが自然言語処理を使ってリクエストを温度変更に変換し、現在の気温や天気予報、他のユーザーのサーモスタット利用データなど、さまざまな情報を考慮します。
人間は人間らしい部分を担い、コンピューター的な処理はコンピューターに任せましょう。
自分の感覚だけで何度下げるかを当てるより、ずっと簡単だと思います。
さらに省エネルギーでもあります。例えば、音声操作のスマート照明を導入した家庭では、エネルギー消費を80%削減したという報告もあります。
カスタマーサポート
医療分野でも触れましたが、文字起こしと要約は、やり取りを後からまとめるよりもはるかに効果的です。
繰り返しになりますが、時間の節約になり、正確性も向上します。自動化によって人々が本来の仕事に集中できる時間が増えることが、何度も証明されています。
特に顕著なのがカスタマーサポート分野で、ASRを活用したサポートは初回対応解決率が25%高いというデータもあります。
文字起こしと要約によって、顧客の感情や問い合わせ内容から解決策を自動的に導き出すプロセスが効率化されます。
車載アシスタント
ここでもホームアシスタントの応用ですが、ぜひ紹介したい分野です。
音声認識は運転者の認知負荷や視覚的な注意散漫を減らします。
また、注意散漫が衝突事故の最大30%の原因となっていることからも、この技術の導入は安全面でも明らかに有効です。
言語聴覚療法
ASRは言語障害の評価や治療のツールとして長く活用されています。
機械は単に作業を自動化するだけでなく、人間にはできないことも実現できることを忘れてはいけません。
音声認識は、人間の耳ではほとんど気づけないような微妙な発話の違いも検出でき、見逃されがちな特徴も捉えることができます。
ASRの未来
STT(音声からテキストへの変換)は、もはや意識せずに使えるほど精度が上がっています。
しかし舞台裏では、研究者たちがさらに強力で使いやすく、目立たない技術にすべく日々努力しています。
ASRの進歩を活かした注目のトレンドをいくつか選び、私自身の考えも交えてみました。
端末内音声認識
多くのASRソリューションはクラウド上で動作しています。これはよく耳にする話でしょう。つまりモデルが遠隔のコンピューター上で動作するということです。
これは、スマートフォンの小さなプロセッサーでは巨大なモデルを動かせなかったり、文字起こしに非常に時間がかかるためです。
そのため、音声データはインターネット経由で、持ち運びできないほど大きなGPUを搭載したリモートサーバーに送信されます。GPUがASRモデルを実行し、文字起こし結果を端末に返します。
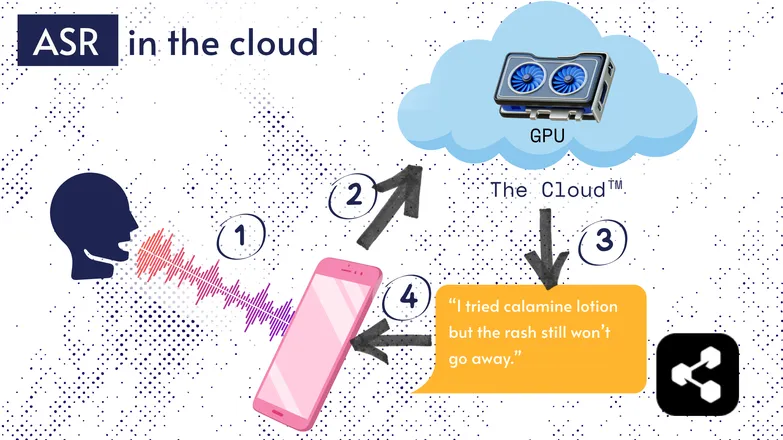
省エネやセキュリティ(個人データをネット上に流したくない人も多い)を理由に、端末上で直接動作するほど小型化されたモデルの研究が盛んに行われています。スマートフォン、パソコン、ブラウザエンジンなどが対象です。
私自身もASRモデルの量子化に関する論文を書き、端末内動作を目指しました。Picovoiceは、カナダの企業で低遅延な端末内音声AIを開発しており、注目しています。
端末内ASRは、低コストで文字起こしを利用できるため、低所得コミュニティへの普及も期待できます。
トランスクリプト優先UI
音声と文字起こしの距離が縮まっています。どういうことでしょうか?
Premiere ProやDescriptのような動画編集ソフトでは、文字起こしを使って録音をナビゲートできます。単語をクリックすると、そのタイムスタンプにジャンプします。
何度か録り直しましたか?気に入ったものを選んで、他はテキストエディタのように削除できます。動画も自動でトリミングされます。
波形だけで編集するのはとても面倒ですが、文字起こしベースのエディタなら驚くほど簡単です。
同様に、WhatsAppのようなメッセージサービスでは、音声メモを文字起こししてテキストでスクラブ(移動)できます。単語の上を指でなぞると、その部分の録音にジャンプします。

面白い話ですが:実はAppleが同様の機能を発表する1週間ほど前に、私も似たものを作っていました。
これらの例は、複雑な裏側の技術が、エンドユーザー向けアプリケーションにシンプルさと直感性をもたらしていることを示しています。
公平性・インクルージョン・低リソース言語
まだ課題は残っています。
ASRは英語や他の主要なリソース豊富な言語では優れた性能を発揮しますが、低リソース言語では必ずしもそうとは限りません。
方言話者や発話障害、音声技術における公平性など、さまざまな課題が残っています。
せっかくの良い流れに水を差すようで申し訳ありませんが、このセクションはASRの「未来」です。私は、誇れる未来を目指したいと思います。
進歩するなら、みんなで一緒に進むべきです。そうでなければ社会的不平等が拡大するリスクがあります。
今日からASRを使い始めましょう
どんな業種でもASRの活用は間違いなく有効ですが、導入方法が気になる方も多いでしょう。ASRをどう実装するのか?そのデータを他のツールにどう渡すのか?
Botpressには使いやすい文字起こしカードが用意されています。ドラッグ&ドロップのフローに組み込め、さまざまなアプリやコミュニケーションチャネルとの連携も簡単です。
今すぐ構築を始めましょう。無料です。
よくある質問
現代のASRは、さまざまなアクセントや騒がしい環境でもどれくらい正確なのでしょうか?
最新のASRシステムは、主要言語の一般的なアクセントであれば非常に高い精度を誇り、クリアな環境下では単語誤り率(WER)が10%未満となります。ただし、強いアクセントや方言、大きな雑音がある場合は精度が大きく低下します。GoogleやMicrosoftなどのベンダーは多様な音声データでモデルを訓練していますが、騒がしい環境での完全な文字起こしは依然として課題です。
ASRは専門用語や業界特有の言葉の書き起こしにも信頼できますか?
ASRは、一般的な会話データで訓練されているため、専門用語や業界特有の言葉には標準設定のままだと対応が難しい場合があります。未知の単語は誤認識や省略されることもありますが、企業向けソリューションではカスタム語彙や業界特化の言語モデル、発音辞書を追加できるため、医療・法律・工学などの分野でも技術用語の認識精度を高めることが可能です。
無料のASRツールとエンタープライズ向けソリューションの違いは何ですか?
無料のASRツールとエンタープライズ向けソリューションの違いは、精度・拡張性・カスタマイズ性・プライバシー管理にあります。無料ツールは誤認識率が高く、対応言語や利用上限が限られます。一方、エンタープライズ向けは低いWER、業界特化カスタマイズ、各種連携、SLA、機密データ対応の強固なセキュリティ機能などを備えています。
ASRは文字起こしの際、ユーザーのプライバシーや機密情報をどのように保護していますか?
ASRは、データ送信時の暗号化や、音声データを外部サーバーに送信せずに端末上でモデルを実行できるオプションなどにより、ユーザーのプライバシーを保護します。多くのエンタープライズ向けプロバイダーはGDPRやHIPAAなどのプライバシー規制にも準拠しており、機密情報を保護するためにデータの匿名化も可能です。
クラウドベースのASRサービスと端末上で動作するソリューションのコストはどのくらい違いますか?
クラウド型ASRサービスは通常、音声1分ごとや利用量に応じて課金され、精度や機能によって1分あたり0.03~1.00ドル以上の料金が発生します。一方、端末内で動作するソリューションは、開発費やライセンス料など初期費用が必要です。



