



- Botpress cung cấp mức giá minh bạch, không có phí ẩn về AI, giúp chi phí AI của bạn phản ánh đúng mức sử dụng thực tế.
- Lưu trữ phản hồi AI có thể giảm chi phí truy vấn khoảng 30% mà không ảnh hưởng đến trải nghiệm người dùng.
- Việc chọn đúng mô hình AI, ví dụ như bắt đầu với GPT-3.5 Turbo thay vì GPT-4, rất quan trọng để cân bằng giữa chi phí và chất lượng.
Nhiều doanh nghiệp gặp khó khăn khi tận dụng tiềm năng của công nghệ AI mà không vượt quá ngân sách. Chúng tôi hiểu tầm quan trọng của sự cân bằng này và cam kết cung cấp các giải pháp giúp người dùng tận dụng AI một cách tiết kiệm chi phí.
Cách tiếp cận của chúng tôi với chi phí AI
Trước tiên, cần hiểu hai thành phần quan trọng trong cách chúng tôi giảm chi phí liên quan đến AI cho người dùng mà vẫn đảm bảo các lợi ích từ AI.
Giá minh bạch: Không phí ẩn
Chúng tôi không cộng thêm bất kỳ khoản phí nào vào các tác vụ liên quan đến AI. Điều này có nghĩa là chi phí AI của bạn hoàn toàn dựa trên mức sử dụng thực tế, không có phí AI bổ sung từ phía chúng tôi.
Lưu trữ phản hồi AI
Lưu trữ phản hồi AI là một trong những chiến lược hiệu quả nhất để giảm chi phí AI cho bot. Bằng cách lưu trữ phản hồi AI, chúng tôi giảm số lượng yêu cầu gửi đến nhà cung cấp LLM, từ đó có thể giảm chi phí truy vấn khoảng 30% mà không làm giảm chất lượng tương tác giữa bot và người dùng.
Mẹo tối ưu chi phí AI
Sau khi đã biết hai cách tiếp cận của chúng tôi để giảm chi phí AI cho người dùng, hãy cùng xem các mẹo bạn có thể áp dụng khi xây dựng bot để giảm chi phí AI hơn nữa.
Tối ưu hóa Knowledge Base của bạn
Tối ưu hóa Knowledge Base (KB) có thể ảnh hưởng lớn đến chi phí AI vì KB thường là yếu tố chi phí AI lớn nhất trong một dự án Botpress.
Mẹo 1: Chọn đúng mô hình AI
Việc lựa chọn mô hình AI ảnh hưởng lớn đến chi phí. Vì GPT-3.5 Turbo nhanh và rẻ hơn GPT-4 Turbo, chúng tôi khuyên bạn nên kiểm tra kỹ hệ thống của mình với GPT-3.5 Turbo trước khi cân nhắc nâng cấp lên phiên bản cao hơn.
Chế độ lai KB Agent của chúng tôi là một lựa chọn cân bằng, vì ban đầu sẽ sử dụng GPT-3.5 Turbo để trả lời truy vấn và chỉ chuyển sang GPT-4 Turbo khi cần thiết.
Mẹo 2: Bảo vệ KB của bạn
Bạn có thể giảm chi phí AI bằng cách bảo vệ KB khỏi các câu hỏi thường gặp không cần AI hoặc trả lời thông minh bằng thẻ Find Records. Cách hoạt động: nếu bạn biết người dùng thường hỏi một số câu hỏi nhất định và bạn có 50 câu hỏi phổ biến cùng câu trả lời, hãy thêm chúng vào một bảng và truy vấn bảng đó bằng thẻ Find Records. Nếu không tìm thấy câu trả lời, lúc đó mới tra cứu trong KB.
Mẹo 3: Phạm vi KB hợp lý
Tùy vào loại và lượng thông tin bạn muốn thêm vào KB, thông thường nên thực hiện song song hai việc để giảm chi phí AI. Đầu tiên, tổ chức thông tin thành các KB nhỏ hơn, mỗi KB tập trung vào một sản phẩm/tính năng/chủ đề cụ thể. Thứ hai, dẫn dắt người dùng qua quy trình với nhiều câu hỏi để thu hẹp phạm vi tìm kiếm vào một KB cụ thể; điều này không chỉ giảm chi phí mà còn mang lại kết quả tốt hơn.
Mẹo 4: Nguồn dữ liệu KB từ Website so với Search the Web
Nếu bạn dùng website làm nguồn dữ liệu KB nhưng không thường xuyên thay đổi nội dung website cần cập nhật cho bot theo thời gian thực, một lựa chọn tiết kiệm là dùng Search The Web làm nguồn dữ liệu KB thay vì Website KB. Trước khi chuyển đổi, hãy kiểm tra hiệu suất với các câu hỏi bạn dự đoán sẽ không bị giảm khi thay đổi này.
Mẹo 5: Truy vấn bảng bằng Find Records hoặc thẻ Execute Code
Nếu bạn có một bảng dữ liệu cần truy vấn, hãy cân nhắc dùng thẻ Find Records thay vì đưa bảng vào KB. Với những ai có kỹ năng kỹ thuật, thực thi mã có thể là cách truy vấn bảng tiết kiệm chi phí hơn nữa. Bạn có thể truy vấn trực tiếp từ thẻ Execute Code và lưu kết quả vào biến workflow để sử dụng sau.
Mẹo 6: Kiểm soát số lượng chunks
Ở đây, chunks là số lượng đoạn thông tin được lấy từ Knowledge Base để tạo câu trả lời. Thông thường, càng lấy nhiều chunks thì câu trả lời càng chính xác – nhưng sẽ tốn nhiều thời gian hơn và tiêu tốn nhiều token AI hơn. Hãy thử nghiệm kích thước chunk để xác định mức tối thiểu vẫn đảm bảo độ chính xác.
Dùng thẻ Execute Code để giảm chi phí AI
Thẻ Execute Code có thể thay thế tiết kiệm chi phí cho một số thẻ AI. Dưới đây là một số trường hợp bạn có thể cân nhắc sử dụng:
Giải pháp thay thế tin nhắn thông minh
Nếu bạn muốn bot gửi phản hồi AI khác nhau cho cùng một truy vấn mỗi lần, bạn cần tắt lưu trữ (xem Phụ lục để biết cách thực hiện). Có những trường hợp tăng chi phí AI là hợp lý để cải thiện trải nghiệm hội thoại. Nhưng không phải lúc nào cũng vậy.
Ví dụ như một lời chào đơn giản được tạo bằng LLM. Mỗi lời chào sẽ phát sinh thêm chi phí AI. Có đáng không? Có lẽ là không. May mắn thay, có một cách tiết kiệm: dùng một mảng nhiều câu trả lời và một hàm đơn giản để chọn ngẫu nhiên và hiển thị.
Tùy vào lượng hội thoại, số tiền tiết kiệm được nhờ cách này có thể rất đáng kể.
Bạn có thể xem thêm chi tiết về cách triển khai tin nhắn thay thế tại đây.
Thực thi mã cho các tác vụ đơn giản
Với các tác vụ đơn giản như định dạng lại dữ liệu hoặc trích xuất thông tin từ dữ liệu có cấu trúc, dùng thẻ Execute Code sẽ hiệu quả, tiết kiệm và nhanh hơn so với dùng LLM.
Giải pháp thay thế Summary Agent
Bạn có thể dùng thẻ Execute Code để tạo transcript riêng. Đặt thẻ Execute Code ở bất kỳ đâu bạn muốn lưu lại tin nhắn của người dùng và bot vào một biến mảng. Sau đó, bạn có thể dùng mảng này làm ngữ cảnh cho KB.
Đơn giản hóa khi có thể
Chọn phương thức tương tác đơn giản nhất mà vẫn đạt mục tiêu mà không làm giảm trải nghiệm người dùng. Ví dụ, nếu bạn muốn thu thập phản hồi, hệ thống đánh giá sao kèm bình luận sẽ tiết kiệm chi phí hơn so với dùng AI để thu thập thông tin tương tự.
Mẹo cho AI Tasks, AI Generate Text và Dịch thuật
Chọn đúng mô hình AI
Đúng vậy, việc chọn đúng mô hình AI quan trọng đến mức cần nhắc lại lần nữa. Tương tự như KB, lựa chọn mô hình AI ảnh hưởng lớn đến chi phí khi thực hiện AI Tasks. Hãy ưu tiên GPT-3.5 Turbo cho các hướng dẫn không quá phức tạp. Trước khi cân nhắc nâng cấp, hãy kiểm tra kỹ hệ thống với mô hình này. Lưu ý, GPT-4 Turbo đắt gấp 20 lần GPT-3.5 Turbo. Trừ khi kết quả vượt trội, hãy chọn GPT-3.5 Turbo.
Ngoài ra, bạn cũng có thể tiết kiệm chi phí AI bằng cách giảm số lượng token tiêu thụ trong mỗi lần chạy AI Task.
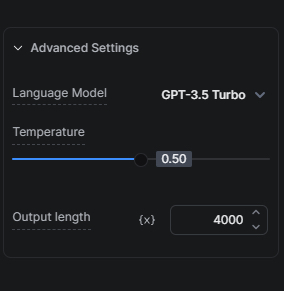
Tôi khuyên bạn nên chú ý giảm số này vì bất kỳ token nào vượt quá sẽ bị cắt bớt. Ví dụ, nếu bạn giới hạn độ dài 2000 token mà tổng prompt và kết quả vượt quá 2000 token, phần đầu vào sẽ bị cắt tương ứng.
AI Task so với AI Generate Text
Với các đầu ra văn bản đơn giản, thẻ AI Generate Text dùng ít token hơn và dễ thiết lập hơn thẻ AI Task. Với các tác vụ cần phân tích thông tin, thẻ AI Task hiệu quả hơn AI Generate Text.
Vì vậy, tôi khuyên bạn dùng thẻ AI Task khi cần AI xử lý thông tin (ví dụ: xác định ý định người dùng hoặc phân tích đầu vào). Nếu chỉ cần AI tạo văn bản, hãy dùng thẻ AI Generate Text (ví dụ: mở rộng câu trả lời từ KB hoặc tạo câu hỏi sáng tạo).
Để tìm hiểu sâu hơn về sự khác biệt giữa thẻ AI Task và AI Generate Text, xem thêm tại đây.
Dịch thuật
Nếu bot của bạn sẽ xử lý nhiều hội thoại đa ngôn ngữ, hãy cân nhắc tích hợp hook với dịch vụ dịch thuật bên ngoài để tiết kiệm chi phí hơn.
Bạn có thể tìm thông tin thêm về hook tại đây.
Kết luận
Với các chiến lược và mẹo này, bạn sẽ tối ưu hóa được chi phí AI trong Botpress. Hiểu rõ tác động chi phí của từng tác vụ và lựa chọn phương pháp hiệu quả nhất sẽ giúp bạn giảm chi phí AI mà không ảnh hưởng đến hiệu suất.
Đội ngũ của chúng tôi luôn sẵn sàng hỗ trợ bạn lựa chọn các phương án phù hợp và đảm bảo chatbot của bạn mang lại trải nghiệm tốt nhất cho người dùng với chi phí tối ưu nhất. Truy cập trang Giá cả của chúng tôi để biết thêm thông tin hoặc tham gia máy chủ Discord của chúng tôi để được hỗ trợ.
Phụ lục
Cách Ngăn Bộ Nhớ Đệm
Nếu bạn muốn vượt qua bộ nhớ đệm để luôn nhận được kết quả trực tiếp, bạn có thể thực hiện một trong các cách sau:
- Để ngăn chặn bộ nhớ đệm lâu dài: thêm `And discard:{{Date.now()}}` vào tất cả các thẻ liên quan đến AI (ví dụ: trong các prompt Nhiệm vụ AI, trong ngữ cảnh KB, v.v.).
- Để ngăn chặn bộ nhớ đệm tạm thời: xuất bản bot của bạn và kiểm tra từ cửa sổ ẩn danh.
Khóa học đề xuất
- Kỹ thuật xây dựng Prompt ChatGPT cho Nhà phát triển (mặc dù tiêu đề nói là dành cho nhà phát triển, nhưng những người không phải nhà phát triển cũng sẽ được lợi!)
- Xây dựng hệ thống với ChatGPT API



