


- チェーン・オブ・ソートプロンプトはAIモデルに段階的な推論を促し、単に次の単語を予測するよりも複雑なタスクを正確に解決できるようにします。
- これは、数学や論理パズル、手順が多いタスクなど、複数のステップが必要な問題に最適ですが、単純な事実や1ステップの質問には不要です。
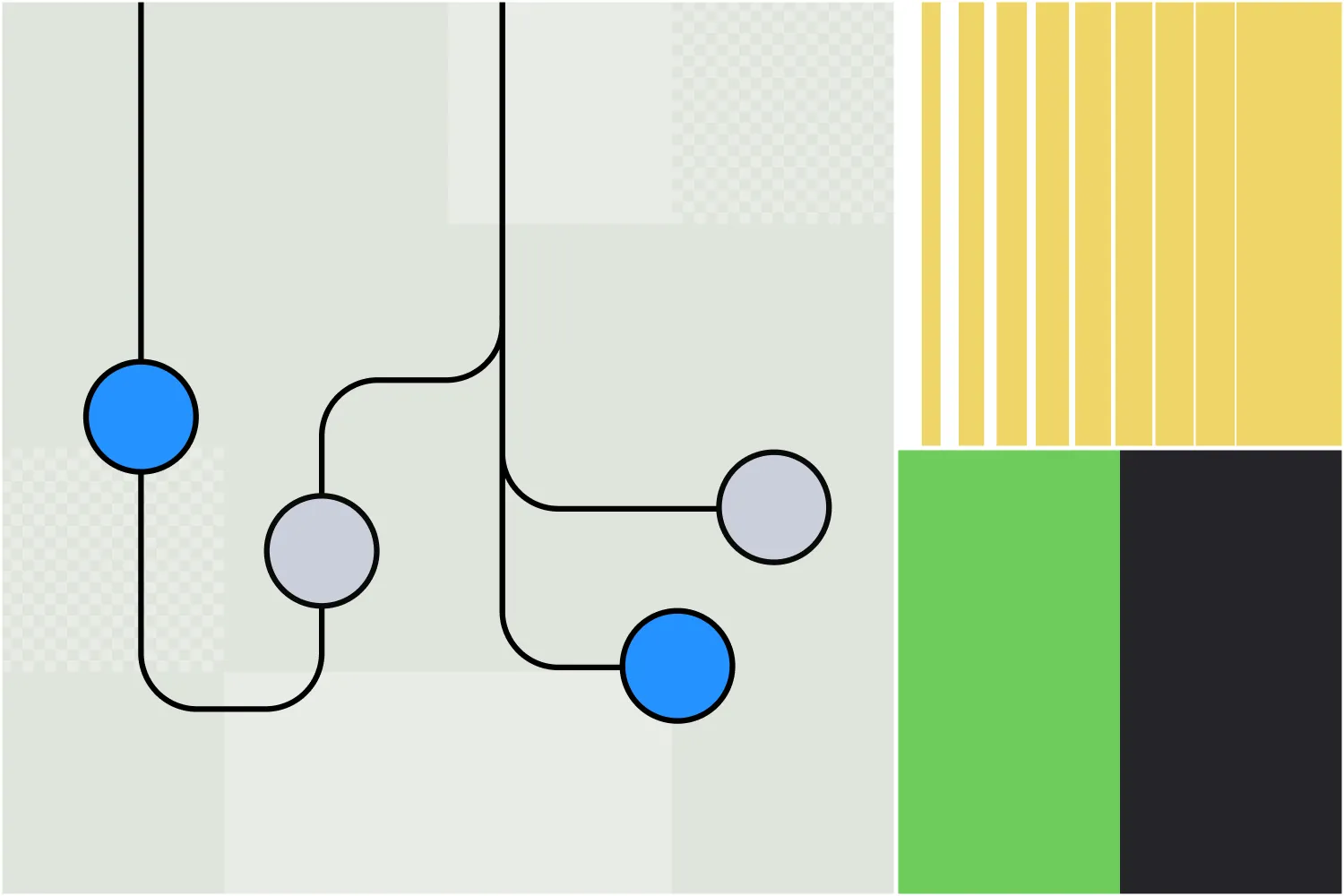
- プロンプトチェーンは、1つのタスクを複数のプロンプトに分割する点で、1つのプロンプト内で思考を展開するchain-of-thoughtプロンプトとは異なります。
GPTチャットボット(ChatGPTなど)を使ったことがあれば、出力の質にばらつきがあることに気づいたはずです。
必要な答えがそのまま返ってくることもあれば、AIの“知能”に疑問を感じることもあります。
ChatGPTの活用レベルをさらに上げるには、プロンプトの工夫が効果的です。チェーン・オブ・ソートプロンプトは、LLMエージェントにタスクを段階的に考えさせてから回答を生成させます。
新しいAIモデルや機能では、チェーン・オブ・ソート推論が直接組み込まれ、追加のプロンプトなしで自動的に問題を推論するようになっています。
Chain-of-thoughtプロンプティングとは何ですか?
チェーン・オブ・ソートプロンプトは、AIに複雑なタスクを分解し、各ステップを推論してから回答するよう指示するプロンプトエンジニアリング手法です。
「チェーン・オブ・ソート推論」という用語も耳にするかもしれません。これは、モデルがタスクを解決するために段階的に推論を進めるプロセスを指します。
OpenAI o1モデルは、すでにチェーン・オブ・ソート推論が組み込まれているため、特別なプロンプトは不要です。ただし、どのLLM搭載チャットボットでもチェーン・オブ・ソートプロンプトを使うことができます。
チェーン・オブ・ソート推論はどのように機能するのでしょうか?
チェーン・オブ・ソート推論とは、AIチャットボットが問題を小さな論理的ステップに分解し、順番に解決していくことを指します。
まずAIが問題の重要な部分を特定します。次に各部分を順番に処理し、各ステップが次のステップにつながるように考えます。前のステップを基に進めることで、AIは論理的な結論に向かって着実に進みます。
チェーン・オブ・ソート・プロンプティングの例
有名な「ストロベリー」プロンプト
ChatGPTなどのLLMにはよく知られた弱点があります。その一つが「strawberry」に含まれる「R」の数を正確に特定できないことです。(おそらくo1モデルのコードネーム「Strawberry」の由来となった有名な制限です。)
ChatGPT-4oはチェーン・オブ・ソート推論を使いません。その代わり、学習データを参照し、各単語が前の単語の後に続く確率に基づいて応答を生成します。多くの場合正しく聞こえるかもしれませんが、実際は人間の言語を模倣しているだけで、推論や調査をしているわけではありません。
有名なイチゴの問題をChatGPT-4oに聞くと、正しい答えを出せません。

しかし、LLM搭載のチャットボットが正しい答えにたどり着くように、チェーン・オブ・ソート推論プロンプト手法を使うことができます。

OpenAI o1-previewによる最新のChatGPTは、追加のプロンプトなしでチェーン・オブ・ソート推論を使う初の主要LLMです。
最初の試行で正解を導き出せるのは、上記の2つ目のChatGPT-4oプロンプトと同じ手順を自動的に実行するよう指示されているからです。唯一の違いは、追加のプロンプトなしでこのプロセスを行う点です。

数学
以前のChatGPTに小学校の教科書の数学問題を質問しても、必ずしも正解できるとは限りませんでした。
複数ステップの数学問題には推論が必要ですが、以前のLLMにはその能力がありませんでした。問題の各ステップを分解することはできても、正しい手順がわからなければLLMは役に立ちませんでした。
ChatGPT-4oは、問題を段階的に分解して答えを導き出すことができます。

Hubspot連携AIエージェント
実際の活用例として、Hubspotに連携されたLLM搭載のAIエージェントを見てみましょう。営業チームがこのAIエージェントを使い、複数チャネルから集まった新規リードを処理しています。
シナリオ
営業担当者が新しいリードをAIエージェントに送り、Hubspotへの登録と初回メール送信を依頼します。ただし、そのリードがすでに見込み客企業に所属している場合は登録しないよう指示します。

チェーン・オブ・ソート推論なしのLLM
LLM搭載のAIエージェントがリードを登録し、メールを送信しますが、その会社がすでに見込み客かどうかを確認せず、重要な条件を見落としています。
チェーン・オブ・ソート推論を持つLLM
LLM搭載のAIエージェントは、企業がすでに見込み客かどうかを確認してから行動します。見込み客なら登録やメール送信をスキップし、そうでなければリード登録とメール送信を営業担当の指示通りに実行します。
チェーン・オブ・ソート・プロンプティングはいつ使うべきですか?
チェーン・オブ・ソートプロンプトは、段階的な推論が必要な場面で最も効果を発揮します。
論理的推論、計算問題、手順作業、複数ステップが必要な状況などが自動化の有力候補です。
でもちょっと待ってください:推論は良さそうなのに、なぜ常に使わないのでしょうか?
良い質問ですね。すべての質問に推論が必要なわけではありません。例えば:
- 「カナダの首都は?」のような単純な事実確認の質問
- 「145 + 37は?」のような単純な一問一答の問題
- 「同僚にプロジェクトの進捗を3文で丁寧に確認するメールを書いて」などのコンテンツ生成タスク
プロンプトの変更とチェーン・オブ・ソート・プロンプトの違い
名前は似ていますが、プロンプトチェーンとチェーン・オブ・ソート・プロンプティングは、生成AIの出力を向上させるための異なるプロンプト戦略です。
Chain-of-thoughtプロンプト
チェーン・オブ・ソートプロンプトでは、ユーザーがAIに対し、回答の根拠を一度の応答で説明するよう促します。AIは問題解決の各ステップを順に説明しますが、これは1つのプロンプトと応答で完結します。
例えば、チェーン・オブ・ソートプロンプトは1つのメッセージで完結します:
「人事チームが5人分の従業員評価を確認する必要があります。各評価には30分かかり、事前準備に15分必要です。シニア評価はそれぞれ追加で10分かかります。シニア5件とジュニア25件の評価を終えるには合計でどれくらい時間がかかりますか?推論をステップごとに説明してください。」
プロンプトチェーン
プロンプトチェーンでは、タスクを複数のプロンプトに分けて、それぞれが前の結果を基に進めます。これにより、AIが複雑なタスクを構造的に進めやすくなります。
最初のプロンプト例:
プロンプト 1:リモートワークへの移行時に企業が直面しやすい主な課題を特定してください。
出力:
- コミュニケーションのギャップ
- 生産性の維持
- 技術インフラの整備
- 従業員のエンゲージメント
次のプロンプトでは、これらの課題についてさらに深掘りします。例:
プロンプト2:リモートワークへの移行時に発生するコミュニケーションギャップの解決策を企業がどのように見つけられるか教えてください。
次の出力を受けて、さらに次のチェーンとして:
プロンプト3:これらのソリューションを導入する際、企業が直面しがちな課題は何ですか?
このように、両者は似ているものの、生成AIツールからより深く関連性の高い内容を引き出すためのアプローチが異なります。
Botpressでのチェーン・オブ・ソートプロンプト
Botpressユーザーは、チェーン・オブ・ソート推論を活用する機能にすでに馴染みがあります。
Autonomous Nodeは2024年7月にBotpressで登場しました。Autonomous Nodeは、複数ステップのワークフローを自律的に自動化し、意思決定も自動で行えます。
Autonomous Nodeは、「あなたの目的は有望なリードを獲得することです。購入意欲を示したユーザーがいればSalesforceにリードを作成してください。」のようなシンプルなテキストで作成・指示できます。
このAutonomous Nodeを使って構築したAIエージェントは、目標達成のためにさまざまなアクションを自律的に実行します。必要に応じて異なるLLMを切り替え、スピードや性能を優先する判断も可能です。
カスタム自律型エージェントを構築する
Botpressは、本当に自律的なエージェントを構築できる唯一のAIエージェントプラットフォームです。
オープンかつ柔軟なBotpress Studioは、HRからリード獲得まで、あらゆる業界のユースケースに対応します。事前構築済みの統合ライブラリや豊富なチュートリアルにより、ユーザーはゼロからAIエージェントを簡単に構築できます。
今すぐ構築を始めましょう。無料です。
または営業チームにお問い合わせください。
よくある質問
1. チェーン・オブ・ソート・プロンプティングはAIモデルだけに有用なのでしょうか?それとも人間の問題解決にも役立つのでしょうか?
チェーン・オブ・ソートプロンプトはAIモデルの活用だけでなく、人間の問題解決にも役立ちます。人が複雑な課題を一歩ずつ論理的に考えるプロセスを模倣しているためです。
2. チェーン・オブ・ソート推論は「段階的に考える」だけとどう違うのか?
「ステップごとに考える」という一般的な方法に対し、チェーン・オブ・ソート推論はより構造的かつ意図的であり、AIモデルが中間的な推論過程を明示的に説明するよう促します。
3. なぜ一部のLLMはデフォルトでチェーン・オブ・ソート推論を使わないのですか?
一部のLLM、特に初期や小規模なモデルは、マルチステップ出力を生成するようにファインチューニングされていないため、デフォルトでチェーン・オブ・ソート推論を使わず、学習データのパターンから最もありそうな答えを予測することに重点を置いています。
4. チェーン・オブ・ソート・プロンプティングは、推論時にモデルを「トレーニング」する一種ですか?
いいえ、チェーン・オブ・ソートプロンプトはトレーニングの一種ではありません。モデルの重みや知識を変更するのではなく、推論時に構造的な思考を促すことで出力の振る舞いを導きます。
5. チェーン・オブ・ソートプロンプトは常に精度を向上させるのか?
Chain-of-thoughtプロンプトは、必ずしも精度を向上させるわけではありません。複数ステップの推論が必要なタスクには効果的ですが、単純なタスクでは複雑さが増し、パフォーマンスが下がることもあります。



