



- Un réseau de neurones profond (DNN) est un système d'apprentissage automatique composé de couches de nœuds connectés qui apprennent des schémas dans les données pour effectuer des prédictions.
- Les DNN peuvent ajuster leurs connexions internes en fonction des erreurs passées, améliorant ainsi leur précision au fil du temps grâce à la rétropropagation.
- Les progrès en puissance de calcul et l'accès à d'immenses ensembles de données ont rendu les DNN utilisables pour des tâches impliquant des données non structurées comme le texte, les images ou l'audio.
- Les DNN fonctionnent comme des « boîtes noires » : il est souvent difficile de comprendre comment ils prennent leurs décisions.
Qu'est-ce qu'un réseau de neurones profond ?
Un réseau de neurones profond (DNN) est un type de modèle d'apprentissage automatique qui imite la façon dont le cerveau humain traite l'information. Contrairement aux algorithmes traditionnels qui suivent des règles prédéfinies, les DNN apprennent à partir des données et font des prédictions en se basant sur l'expérience — comme nous.
Les DNN sont à la base de l'apprentissage profond et alimentent des applications comme les agents IA, la reconnaissance d'images, les assistants vocaux ou encore les chatbots IA.
Le marché mondial de l’IA — incluant les applications reposant sur les réseaux de neurones profonds — va dépasser les 500 milliards de dollars d’ici 2027.
Qu'est-ce que l'architecture d'un réseau de neurones ?
Le terme « profond » dans DNN fait référence à la présence de plusieurs couches cachées, ce qui permet au réseau de reconnaître des schémas complexes.
Un réseau de neurones est composé de plusieurs couches de nœuds qui reçoivent des données d'autres couches et produisent un résultat final.
Un réseau de neurones se compose de couches de nœuds (neurones). Chaque nœud reçoit une entrée, la traite, puis la transmet à la couche suivante.
- Couche d'entrée : La première couche qui reçoit les données brutes (par exemple, images, texte).
- Couches cachées : Les couches intermédiaires qui transforment les données et détectent des schémas.
- Couche de sortie : Produit la prédiction finale.
Les réseaux de neurones peuvent comporter un nombre quelconque de couches cachées : plus il y a de couches, plus le réseau est complexe. Les réseaux de neurones traditionnels ont généralement 2 ou 3 couches cachées, tandis que les réseaux d'apprentissage profond peuvent en avoir jusqu'à 150.
Quelles différences entre réseaux de neurones et réseaux de neurones profonds ?
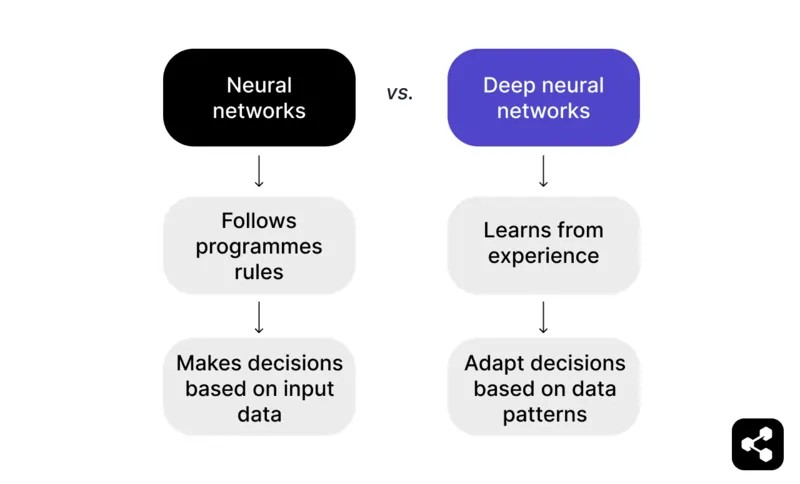
En résumé : Un réseau de neurones qui va au-delà des données d'entrée et apprend de l'expérience devient un réseau de neurones profond.
Un réseau de neurones applique des règles programmées pour prendre des décisions à partir des données d'entrée. Par exemple, dans un jeu d'échecs, il peut suggérer des coups selon des tactiques prédéfinies, mais il reste limité à ce que le programmeur a prévu.
Mais un réseau de neurones profond va plus loin en apprenant de l'expérience. Au lieu de s'appuyer uniquement sur des règles, un DNN ajuste ses décisions selon les schémas qu'il repère dans de grands ensembles de données.
Exemple
Imaginez écrire un programme pour reconnaître des chiens sur des photos. Un réseau de neurones traditionnel aurait besoin de règles explicites pour identifier des caractéristiques comme la fourrure ou la queue. Un DNN, lui, apprend à partir de milliers d'images annotées et améliore sa précision avec le temps — même dans les cas difficiles, sans programmation supplémentaire.
Comment fonctionne un réseau de neurones profond ?
D'abord, chaque neurone de la couche d'entrée reçoit une donnée brute, comme des pixels d'une image ou des mots d'une phrase, et attribue un poids à cette entrée pour indiquer son importance pour la tâche.
Un poids faible (inférieur à 0,5) signifie que l'information est probablement peu pertinente. Ces entrées pondérées traversent les couches cachées, où les neurones ajustent encore l'information. Ce processus se répète jusqu'à ce que la couche de sortie fournisse une prédiction finale.
Comment un réseau de neurones profond sait-il s'il a raison ?
Un réseau de neurones profond sait s'il a raison en comparant ses prédictions à des données annotées lors de l'entraînement. Pour chaque entrée, il vérifie si sa prédiction correspond au résultat réel. En cas d'erreur, il calcule l'écart grâce à une fonction de perte, qui mesure la différence entre la prédiction et la réalité.
Le réseau utilise ensuite la rétropropagation pour ajuster les poids des neurones responsables de l'erreur. Ce processus se répète à chaque itération.
Quels sont les différents types de réseaux de neurones ?
Comment un réseau de neurones profond s'améliore-t-il avec le temps ?
Un réseau de neurones profond s'améliore avec le temps en apprenant de ses erreurs. Lorsqu'il fait une prédiction — par exemple, identifier un problème client ou recommander un produit — il vérifie si elle était correcte. Sinon, le système s'ajuste pour progresser lors de la prochaine tentative.
Par exemple, dans le support client, un DNN peut prédire comment résoudre un ticket. Si la prédiction était incorrecte, il apprend de cette erreur et devient plus efficace pour traiter des tickets similaires à l'avenir. En vente, un DNN peut apprendre quels prospects convertissent le mieux en analysant les ventes passées, ce qui améliore ses recommandations au fil du temps.
Ainsi, à chaque interaction, le DNN devient plus précis et fiable.
Les réseaux de neurones profonds pensent-ils différemment des humains ?
Mais les modèles d'apprentissage profond fonctionnent souvent comme une « boîte noire » : il est difficile pour les humains de comprendre comment ils prennent leurs décisions. Comme l'explique la chercheuse Cynthia Rudin de l'université Duke explique, l'interprétabilité est essentielle pour un usage éthique de l'IA, surtout dans des contextes critiques.
Des chercheurs ont tenté de visualiser la façon dont les réseaux traitent les images, mais pour des tâches plus complexes — comme le langage ou la finance — la logique reste cachée. Même si ces algorithmes semblent récents, beaucoup existent depuis des décennies. Ce sont les progrès en données et en puissance de calcul qui les rendent utilisables aujourd'hui.
Pourquoi les réseaux de neurones profonds sont-ils de plus en plus populaires ?
1. Amélioration de la puissance de calcul
L'une des raisons principales de l'essor des DNN est la rapidité et le coût réduit de la puissance de calcul. Cela a permis d'obtenir des résultats rapides. « L'arrivée de matériels spécialisés comme les GPU et les TPU a rendu possible l'entraînement de réseaux avec des milliards de paramètres. »
2. Disponibilité croissante des ensembles de données
Un autre facteur clé est la disponibilité de grands ensembles de données, indispensables pour que les réseaux de neurones profonds apprennent efficacement. À mesure que les entreprises génèrent plus de données, les DNN peuvent découvrir des schémas complexes que les modèles traditionnels ne peuvent pas traiter.
3. Progrès dans le traitement des données non structurées
Leur capacité à traiter des données non structurées comme le texte, les images ou l'audio a aussi permis de nouvelles applications, notamment dans les chatbots, les systèmes de recommandation ou l'analyse prédictive.
Les réseaux de neurones peuvent-ils traiter des données non structurées ?
Oui, les réseaux de neurones peuvent traiter des données non structurées, et c'est l'un de leurs plus grands atouts.
Les réseaux de neurones artificiels qui traitent des données non structurées relèvent de l'apprentissage non supervisé. C'est le Graal de l'apprentissage automatique et cela se rapproche davantage de la façon dont les humains apprennent.
Les algorithmes traditionnels d'apprentissage automatique ont du mal à traiter les données non structurées, car ils nécessitent une ingénierie des caractéristiques — c’est-à-dire la sélection et l’extraction manuelles des éléments pertinents. À l’inverse, les réseaux neuronaux peuvent apprendre automatiquement des motifs à partir des données brutes, sans intervention manuelle poussée.
Comment les réseaux neuronaux profonds apprennent-ils grâce à l’entraînement ?
Un réseau neuronal profond apprend en faisant des prédictions puis en les comparant aux résultats attendus. Par exemple, lorsqu’il analyse des photos, il prédit si une image contient un chien et mesure la fréquence de ses bonnes réponses.
Le réseau calcule sa précision en vérifiant le pourcentage de prédictions correctes et utilise ce retour pour s’améliorer. Il ajuste les poids de ses neurones et recommence le processus. Si la précision s’améliore, il conserve les nouveaux poids ; sinon, il essaie d’autres ajustements.
Ce cycle se répète de nombreuses fois jusqu’à ce que le réseau parvienne à reconnaître les motifs et à faire des prédictions fiables. Lorsqu’il atteint ce stade, on dit que le réseau a convergé et qu’il est correctement entraîné.
Gagnez du temps de développement tout en obtenant de meilleurs résultats
Le réseau de neurones porte ce nom car il existe une ressemblance entre cette approche de programmation et le fonctionnement du cerveau humain.
Comme le cerveau, les algorithmes de réseaux neuronaux utilisent un réseau de neurones ou de nœuds. Et, à l’image du cerveau, ces neurones sont des fonctions distinctes (ou de petites machines, si vous préférez) qui reçoivent des entrées et produisent des sorties. Ces nœuds sont organisés en couches : les sorties d’une couche deviennent les entrées de la suivante, jusqu’à ce que les neurones de la couche finale produisent le résultat.
Il existe donc plusieurs couches de neurones, chaque neurone individuel recevant très peu d’entrées et produisant peu de sorties, tout comme dans le cerveau. La première couche (ou couche d’entrée) reçoit les données, et la dernière couche (ou couche de sortie) fournit le résultat final.
Est-il pertinent d’appeler ce type d’algorithme un « réseau de neurones » ?
Appeler cet algorithme un « réseau neuronal profond » s’est révélé efficace d’un point de vue marketing, même si cela peut susciter des attentes exagérées. Malgré leur puissance, ces modèles restent bien plus simples que la complexité du cerveau humain. Néanmoins, la recherche continue sur des architectures neuronales visant une intelligence générale, proche de celle de l’humain.
Cela dit, certains essaient de ré-ingénier le cerveau à l’aide de réseaux neuronaux très complexes, dans l’espoir de reproduire une intelligence générale, semblable à celle de l’humain, dans le développement de bots. Alors, comment un réseau de neurones et les techniques d’apprentissage automatique peuvent-ils nous aider à reconnaître un chien ?
Plutôt que de définir manuellement les caractéristiques d’un chien, un algorithme de réseau neuronal profond peut identifier les attributs importants et gérer tous les cas particuliers sans programmation spécifique.
FAQ
1. Combien de temps faut-il pour entraîner un réseau neuronal profond ?
La durée d’entraînement d’un réseau neuronal profond dépend de la taille du jeu de données et de la complexité du modèle. Un modèle simple peut être entraîné en quelques minutes sur un ordinateur portable, tandis qu’un modèle de grande taille comme GPT ou ResNet peut demander plusieurs jours, voire semaines, sur des GPU ou TPU performants.
2. Puis-je entraîner un réseau neuronal profond sur mon ordinateur personnel ?
Oui, il est possible d’entraîner un réseau neuronal profond sur un ordinateur personnel si le jeu de données est petit et le modèle relativement simple. En revanche, pour des modèles volumineux ou de grands ensembles de données, il faudra un ordinateur équipé d’un GPU ou utiliser des plateformes cloud comme AWS ou Azure.
3. Quelle est la différence entre un réseau neuronal profond utilisé en vision par ordinateur et un autre utilisé en traitement du langage naturel ?
Un réseau neuronal profond utilisé en vision par ordinateur s’appuie sur des couches convolutionnelles (CNN) pour traiter les pixels, tandis que les modèles de traitement du langage naturel utilisent des architectures comme les transformers, LSTM ou RNN pour gérer la structure séquentielle et sémantique du langage. Les deux reposent sur l’apprentissage profond, mais sont optimisés pour des types de données différents.
4. Comment choisir le nombre de couches cachées dans un réseau neuronal profond ?
Le choix du nombre de couches cachées dans un réseau neuronal profond se fait par expérimentation : trop peu de couches risquent de sous-apprendre les données, tandis qu’un trop grand nombre peut entraîner du surapprentissage et ralentir l’entraînement. Pour des tâches simples, commencez par 1 à 3 couches et augmentez progressivement, en validant les performances avec la validation croisée ou un jeu de test.
5. Quelles sont les prochaines grandes avancées attendues dans la recherche sur les réseaux neuronaux profonds ?
Les prochaines avancées dans la recherche sur les réseaux neuronaux profonds incluent les réseaux neuronaux clairsemés (pour réduire les coûts de calcul), le raisonnement neurosymbolique (qui combine logique et apprentissage profond), de meilleures techniques d’interprétabilité, ainsi que des architectures plus économes en énergie, inspirées de l’efficacité du cerveau humain (par exemple, les réseaux neuronaux impulsionnels).



